学習塾を運営するのに最適なのはどこ? オープンデータを活用して実践的なスキルを身に付ける:ITエンジニアのためのデータサイエンティスト養成講座(特別編)(3/3 ページ)
» 2013年10月02日 15時45分 公開
[中林紀彦,日本アイ・ビー・エム]
単純な推計人口の分析
千葉市内で学習塾を運営するのに最適なのはどの区?
データの整備だけでは面白くありませんので、簡単な分析をしてみましょう。例えば中学生向けの高校受験の塾を千葉市内で展開する際にどの区がよいのかを検討するために、今後10年間の区毎の中学生の推移を知りたいとしましょう。今回整備したデータを使って簡易的な人口推定を行うことで今後の中学生の人口推移をしることが可能です。
表のように2013年は13歳から15歳が中学生ですが、2014年では2013年に12歳から14歳が中学生です。このように1年ごとに1歳ずつスライドさせて計算していくと、今後10年間の中学生の数を簡易的に推定することができます。“簡易的”というのは他からの転入や転出、出生率や死亡率を加味していないからです。

# 必要なライブラリの読み込み
get_ipython().magic(u'pylab')
import pandas as pd
# CSVファイルからデータの読み込み
dfall = pd.read_csv('all_tyo.csv', header=0, encoding='UTF-8')
# データフレームの定義
df = pd.DataFrame(columns=['year', 'group', 'ward', 'num'])
dfwork = pd.DataFrame(columns=['year', 'group', 'ward', 'num'], index=range(0,6))
# 値の設定
dfwork.ward = dfall[dfall.year== 2013].groupby(['ward'])['num'].sum().index
dfwork.group = '中学生'
# 2013年から2022年までの中学生(13歳から15歳)の数を区毎に集計
for i in range(0,10):
dfwork.year = 2013+i
dfwork.num = dfall[(dfall.year== 2013) & (dfall.age >=12-i) & (dfall.age <= 12+2-i)]\
.groupby(['ward'])['num'].sum().values
df = pd.concat([df, dfwork])
# 年度と区別にクロス集計
dfpivot = pd.pivot_table(df, values='num', rows='year', cols='ward', aggfunc=sum,fill_value=0)
# グラフ表示
dfpivot.plot()
myprop = {'fname' : r'C:\Windows\Fonts\meiryo.ttc'}
plt.legend(loc='lower left', prop=myprop)
Analysis.py
上記のソースコードで2013年から2022年までの年度別、区別の中学生の人口を計算できます。pandasのpivot_table関数でクロス集計が可能(20行目)ですので、グラフにプロットするためにクロス集計しておきます。
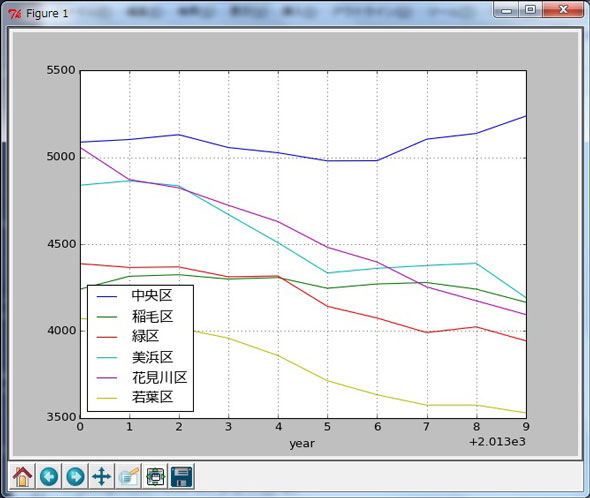
In [15]: dfpivot Out[15]: ward 中央区 稲毛区 緑区 美浜区 花見川区 若葉区 year 2013 5087 4240 4388 4839 5059 4072 2014 5102 4315 4366 4864 4872 4057 2015 5130 4324 4369 4836 4824 4017 2016 5056 4299 4312 4671 4724 3959 2017 5026 4308 4317 4509 4630 3859 2018 4979 4246 4142 4334 4482 3714 2019 4980 4271 4075 4361 4397 3633 2020 5104 4279 3991 4377 4254 3574 2021 5137 4241 4024 4390 4174 3574 2022 5237 4166 3944 4193 4095 3529
結果をプロットしたものが下のグラフです。唯一、中央区だけが中学生の数が増加していくのが確認できますし、それ以外の区では中学生が年々減少し続けることが見てとれます。
おわりに
今回の特別編では、オープンデータを分析に活用する際に必要な実践的なテクニックについて紹介しました。オープンデータとして今回扱ったようなExcel形式のデータはさまざまなものが公開されていますので、各回の連載や今回紹介したテクニックを駆使して皆さんのデータ活用に役立ててください。
「ITエンジニアのためのデータサイエンティスト養成講座」バックナンバー
- 時系列分析II―ARMAモデル(自己回帰移動平均モデル)の評価と将来予測
- 時系列分析I ――ARMAモデルと時系列分析
- 富山県民を分類してみたら……?――クラスタリング分析の手法
- 回帰分析II:重回帰分析の方法、科学的な将来予測
- 回帰分析I:回帰分析って何? から、最小二乗法、モデル評価、妥当性検討の実際まで
- 学習塾を運営するのに最適なのはどこ? オープンデータを活用して実践的なスキルを身に付ける
- 「ビールと紙おむつ」のような相関関係を探る分析手法にはどんなものがある?――データ分析方法についての検討
- ログを分析するには? XMLデータを分析するには? pandasでデータを分析できる状態にする
- データを取り込む・格納するための方法を理解する
- データ分析がデキるITエンジニアになるために必要な「道具」を揃える
- ITエンジニアがデータサイエンティストを目指すには?
Copyright © ITmedia, Inc. All Rights Reserved.
SpecialPR
アイティメディアからのお知らせ
スポンサーからのお知らせPR
SpecialPR




注目のテーマ

システム開発ノウハウ 【発注ナビ】PR
編集部からのお知らせ
あなたにおすすめの記事PR
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。