富山県民を分類してみたら……?――クラスタリング分析の手法:ITエンジニアのためのデータサイエンティスト養成講座(8)(3/4 ページ)
オープンデータ(富山県の市町村別人口動態データ)を使った市町村のクラスタリング
前述サンプルでは2次元データのケースでしたが、アルゴリズムとしてはn次元のデータも対応可能です。
実際のケースでも3つ以上の属性を使ったクラスタリングを行うケースが多いので、次の例ではオープンデータを使った3次元のクラスタリングを紹介したいと思います。サンプルデータとしてはオープンデータと公開されている、「富山県の市町村別人口動態(平成23年10月1日〜平成24年9月30日)」(元データのリンク、Excelデータ)を用いて、各市町村の人口の自然増加、転入、転出の3つの軸でクラスタリングしてみましょう。
必要なライブラリをインポートしてデータを取り込みます(In [1]〜In [10])。
公開されているデータがExcel形式なので、URLからファイルを直接取り込んで(In [6]〜In [8])、1枚目のシートから必要な列(A列、C列、G列、J列)を抽出し(In [9])、DataFrameに取り込みます(In [10])。
In [1]: # ライブラリのインポート In [2]: %pylab Welcome to pylab, a matplotlib-based Python environment [backend: TkAgg]. For more information, type 'help(pylab)'. In [3]: import urllib2 In [4]: import pandas as pd In [5]: # データの取り込み In [6]: link = 'http://www.pref.toyama.jp/sections/1015/lib/jinko/_dat_h24/jinko_dat005.xls' In [7]: socket = urllib2.urlopen(link) In [8]: xls = pd.ExcelFile(socket) In [9]: df = xls.parse(xls.sheet_names[0], header=None, index_col=0, skiprows=5, parse_cols="A,C,G,J") In [10]: df.columns = ['natural', 'in', 'out']
3つの軸があるので、自然増加(natural)、転入(in)、転出(out)を組み合わせて6種類のグラフを表示します。
Pandasライブラリにはscatter_matrix関数という便利な関数が用意されていますので、6種類のグラフを一気に表示することが可能です(図8)。
In [11]: # グラフ表示(散布図)
In [12]: pd.scatter_matrix(df)
Out[12]:
array([[<matplotlib.axes.AxesSubplot object at 0x049EA550>,
<matplotlib.axes.AxesSubplot object at 0x04BB2D90>,
<matplotlib.axes.AxesSubplot object at 0x049F3D10>],
[<matplotlib.axes.AxesSubplot object at 0x04C8BFB0>,
<matplotlib.axes.AxesSubplot object at 0x04CDB810>,
<matplotlib.axes.AxesSubplot object at 0x04D078B0>],
[<matplotlib.axes.AxesSubplot object at 0x04D6DB70>,
<matplotlib.axes.AxesSubplot object at 0x07A37910>,
<matplotlib.axes.AxesSubplot object at 0x07A81CD0>]], dtype=object)
In [13]: # グラフを閉じる
In [14]: plt.close()
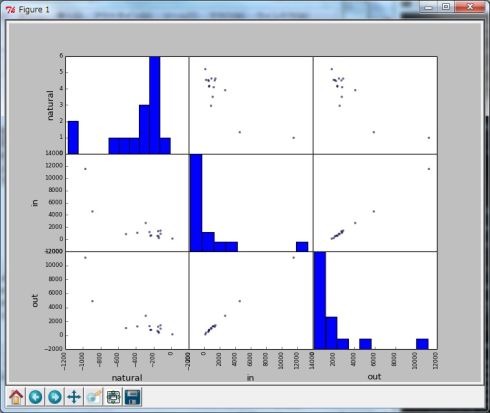
グラフを見ると人口の多い富山市と高岡市以外はデータが密集していて分類が難しいので、富山市と高岡市を除外した13市町村でクラスタリングしてみましょう(In [15]〜In [17])。
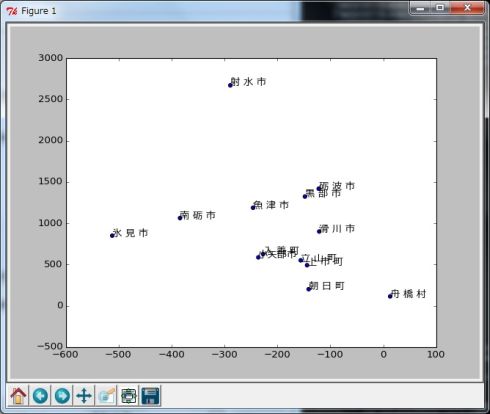
自然増加(natural)と転入(in)でデータの分散を確認します(In [18]〜In [21])。
In [21]で市町村名を表示させていますが、デフォルトの設定では日本語が文字化けしてしまいますので、フォント名を明示的に指定しておきます(In [20])(図9)。
In [15]: # データの絞り込み(富山市と高岡市を除外)
In [16]: df = df[2:]
In [17]: df
Out[17]:
natural in out
0
魚 津 市 -246 1188 1313
氷 見 市 -512 850 1029
滑 川 市 -121 900 945
黒 部 市 -148 1324 1227
砺 波 市 -122 1419 1426
小矢部市 -236 587 772
南 砺 市 -384 1063 1267
射 水 市 -289 2671 2791
舟 橋 村 13 114 132
上 市 町 -144 492 497
立 山 町 -156 551 610
入 善 町 -227 627 767
朝 日 町 -141 201 356
In [18]: # グラフ(散布図)で確認
In [19]: plt.scatter(df['natural'], df['in'])
Out[19]: <matplotlib.collections.PathCollection at 0x7f814f0>
In [20]: myprop = matplotlib.font_manager.FontProperties(fname=r'C:\Windows\Fonts\meiryo.ttc')
In [21]: for i, text in enumerate(df.index):
....: plt.annotate(text, xy = (df['natural'][i], df['in'][i]), fontproperties=myprop)
....:
In [22]: # グラフを閉じる
In [23]: plt.close()
では先程と同様にkmeans2関数を使って、13市町村を3つのクラスターに分類してみましょう(In [24]〜In [33])。
In [24]: # K平均法のライブラリをインポート
In [25]: from scipy.cluster.vq import kmeans2
In [26]: # K平均法で2つのクラスターに分割
In [27]: centroid, label = kmeans2(array(df), 3)
In [28]: # 各クラスターの中心の確認
In [29]: center = pd.DataFrame(centroid)
In [30]: center
Out[30]:
0 1 2
0 -255.5 1124.000000 1201.166667
1 -289.0 2671.000000 2791.000000
2 -148.5 428.666667 522.333333
In [31]: # 各クラスターのラベルを追加してクラスターを確認
In [32]: df['cluster'] = label
In [33]: df
Out[33]:
natural in out cluster
0
魚 津 市 -246 1188 1313 0
氷 見 市 -512 850 1029 0
滑 川 市 -121 900 945 0
黒 部 市 -148 1324 1227 0
砺 波 市 -122 1419 1426 0
小矢部市 -236 587 772 2
南 砺 市 -384 1063 1267 0
射 水 市 -289 2671 2791 1
舟 橋 村 13 114 132 2
上 市 町 -144 492 497 2
立 山 町 -156 551 610 2
入 善 町 -227 627 767 2
朝 日 町 -141 201 356 2
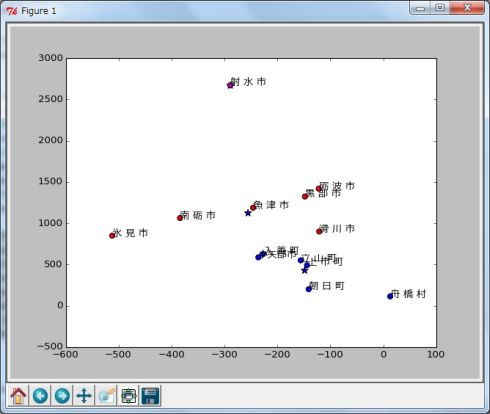
結果をグラフでも確認します。今回は3つのクラスターに分類しているので赤、青、マゼンダの3色で表示させています(In [34]〜In [40])(図10)。
In [34]: # クラスターの中心をグラフに表示 In [35]: plt.scatter(center[0], center[1], s= 80, c='b', marker='*') Out[35]: <matplotlib.collections.PathCollection at 0x8066bd0> In [36]: # 各クラスターをグラフに表示 In [37]: plt.scatter(df[df['cluster'] == 0]['natural'], df[df['cluster'] == 0]['in'], s=40, c='r', marker='o') Out[37]: <matplotlib.collections.PathCollection at 0x82f99b0> In [38]: plt.scatter(df[df['cluster'] == 1]['natural'], df[df['cluster'] == 1]['in'], s=40, c='m', marker='o') Out[38]: <matplotlib.collections.PathCollection at 0x830e3d0> In [39]: plt.scatter(df[df['cluster'] == 2]['natural'], df[df['cluster'] == 2]['in'], s=40, c='b', marker='o') Out[39]: <matplotlib.collections.PathCollection at 0x830eff0> In [40]: for i, text in enumerate(df.index): ....: plt.annotate(text, xy = (df['natural'][i], df['in'][i]), fontproperties=myprop) ....:
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。