fluentdと定番プラグインのインストール:今さら聞けないfluentd〜クラウド時代のログ管理入門(2)(2/2 ページ)
これは便利! 知っておきたいfluentdのプラグイン
ここまでの説明で、各プラグインを利用する前提となる設定ファイルの記法についてはお分かりいただけたと思います。
ここからは代表的なプラグインの概要および用途、設定例について、各プラグインの利用時の注意点などと併せて紹介します。
各プラグインの設定に関するより詳細な情報は、公式のドキュメントや各プラグインの公開サイトにある「README」などを参照してください。
fluentdの標準組み込みプラグイン
インプットプラグイン
・in_tail
ログファイルへの書き込み情報を、常時入力として取り込むプラグインです。pathで指定したファイルをリアルタイムに読み込み、formatで指定した形式でログの各データをkeyとvalueのセットにして、fluentdに入力できます。
例えば、Apacheのログファイルやアプリケーションのログファイルをリアルタイムに管理したい場合に有効です。ローテートするログファイルに関しても、ログデータを取りこぼすことなく入力できるように作られています。
in_tailプラグインを使う場合の注意点は、pos_fileの設定です。これは、fluentdがログファイルのどこまでを読み込んだかを記録するファイルを指定するオプション設定です。
もしpos_fileの指定がないと、fluentdの起動後に追記されたログのみが入力されることになります。そのため、例えばメンテナンスのためにfluentdを一時的に停止しなければならない状況が発生すると、fluentdの停止期間中に発生したログの入力が行われません。
pos_fileの設定を行い、前回どこまで読み込んだかを記録しておくことで、fluentdは起動後、前回読み込んだ位置から継続して続きを読み込むことができます。これによりログの収集漏れなく管理することが可能になります。
・設定例
<source> type tail format json #json、tsv、csv、ltsv、syslog、apache2など、標準で用意されているもの以外にも正規表現での指定も可能 path /tmp/json.log #tail実行対象となるファイルを指定 tag app.log #各行のログデータに対して付与するタグを指定 pos_file /tmp/tail_pos.log #前回の読込み位置を記録 </source>
・in_forward
別のfluentdから送られてきたデータを入力として取り込むプラグインです。指定したポートでTCPおよびUDPソケットをリッスンし、他のfluentdのout_forwardプラグインから送られてくるイベントデータを受け取ります。
このプラグインは、複数のサーバーで管理されているログデータを1個所に集約して管理する場合などに有効です。
・設定例
<source> type forward port 24224 #TCPでデータの受信をUDPでハートビートパケットの受信を実施(デフォルトは24224ポート) bind 0.0.0.0 #リッスンするアドレスの指定 </source>
・in_exec
任意のコマンド実行結果を入力として取り込むプラグインです。commandで指定したコマンドを実行した結果を入力とすることができます。コマンド結果はTSV(タブ区切りでの出力)、JSON、MessagePackの形式であれば扱えます。コマンド結果の中に含まれるデータの中身をタグとして指定することも可能なため、コマンド実行結果に応じてアウトプットの処理を動的に振り分けることもできます。
他の組み込みプラグインや公開されているプラグインの中に、望んでいる処理が実現できるものが見つからない場合などは、このプラグインを使うことで、任意の処理結果をfluentdで扱えるようになります。
・設定例
<source> type exec command ruby /tmp/sample.rb #実行するコマンドを指定 format tsv #tsv、json、msgpackのいずれかを指定(デフォルトはtsv) keys tag, time, key1, key2 #出力結果の各カラムに対してkeyの名前を割り当て tag_key tag #タグとして利用する値はどのkeyかを指定(tagで全てのデータに共通のタグを設定も可能)) time_key time #時刻として利用する値はどのkeyかを指定(指定なしの場合は現在時刻が採用される) time_format %Y-%m-%d %H:%M:%S %Z #時刻のフォーマットを指定 run_interval 10s #コマンドの実行間隔を指定 </source>
この例では、コマンド実行結果(sample.rbの出力)が「タグ名<TAB>時刻<TAB>値1<TAB>値2」というTSV形式で出力されるように設定しています。
アウトプットプラグイン
・out_copy
1つのイベントデータを複数のアウトプットプラグインに複製して出力するためのプラグインです。バッファーを利用しないMultiOutputというタイプのアウトプットプラグインです。<match>ディレクティブ内に<store>ディレクティブを指定することで複製して出力できます。
これは、ログデータを複数の用途で利用するために複数のツールに振り分けて登録したい場合などに有効です。
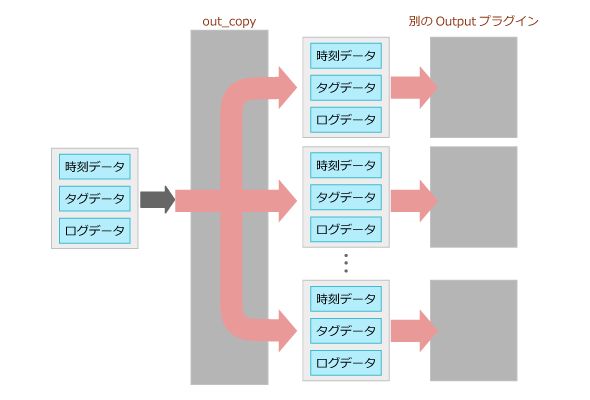 図1 out_copy処理概要
図1 out_copy処理概要・設定例
<match タグパターン>
type copy
<store> #storeディレクティブを複数指定することで複製されます
type file
path /tmp/out
</store>
<store>
type s3
aws_key_id xxxxxx
aws_sec_key xxxxx
s3_bucket fluentd_log
s3_endpoint s3-ap-northeast-1.amazonaws.com
buffer_path /tmp/buffer.log
</store>
</match>
この例の場合は、fluentdが稼働するサーバーのローカルファイルとAmazon S3のバケットにコピーし、出力します。
・out_file
fluentdが稼働しているサーバー内のファイルにイベントデータを出力するためのプラグインです。時間ベースでバッファー管理を行うTimeSlicedOutputというタイプのアウトプットプラグインとなります。
pathで指定した名前と日付情報に.logという拡張子が連結された名前のファイルにイベントデータを出力し、time_slice_formatで指定した単位でログを管理します(デフォルトは0時0分+time_slice_wait[デフォルトは10分後]で、指定した時間が経過した時点でバッファーに蓄積されたデータをファイルに書き込みます)。
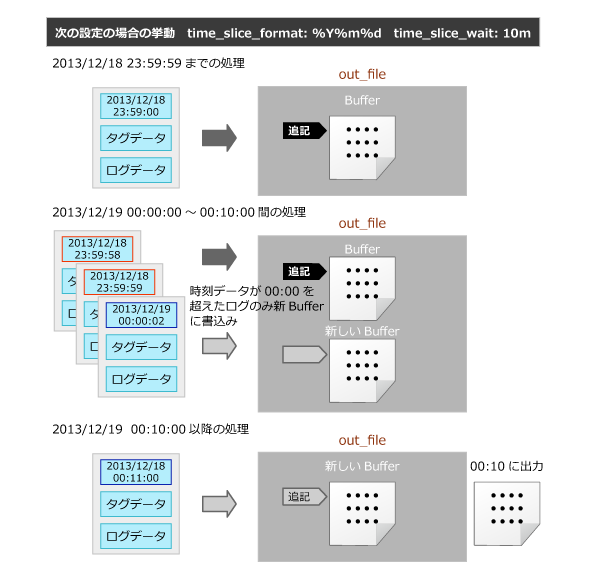 図2 out_file処理概要
図2 out_file処理概要・設定例
<match タグパターン> type file path /var/log/fluent/test #ファイル出力する先のディレクトリとファイルの先頭に付ける名前を指定(この設定例では、/var/log/fluent/test.[time_slice_formatで指定した形式]_(No.).logで出力) time_slice_format %Y%m%d #ファイルに書き出すタイミングの指定(デフォルトは%Y%m%dで、その日の0時0分が書き出しの起点となる。1時間毎の場合は「%Y%m%d%H」、1分毎の場合は「%Y%m%d%H%M」と設定) time_slice_wait 10m #fluentdに対して遅れて到達したログを書き出すための待ち時間設定(書き出し時刻よりも前のログデータの到着待ちを行う)。 time_format %Y-%d-%m_%H:%M:%S #ログファイルに書きだす際の時刻表示フォーマット指定 utc #時刻をUTCで扱う(utcを設定しない場合はlocaltimeを使用) commpress gzip #ファイル書き出し時に圧縮するかどうかの設定(デフォルトは無圧縮) </match>
・out_forward
受信したログデータを他のfluentdに転送するためのプラグインです。送信先サーバーのin_forwardプラグインの設定とセットで使います。バッファー管理するObjectBufferedOutputというタイプのアウトプットプラグインです。
serverディレクティブに指定したIPアドレスおよびポート上で稼働しているfluentdに対してログデータを転送します。複数のサーバーを指定した場合には、ログデータを分散させて転送することが可能です。分散の度合いは重み付け(weight設定)して制御できます。
複数のサーバーに全てのデータを転送したい場合には、前述したout_copyプラグインを使って複製し、out_forwardで転送すれば実現できます。
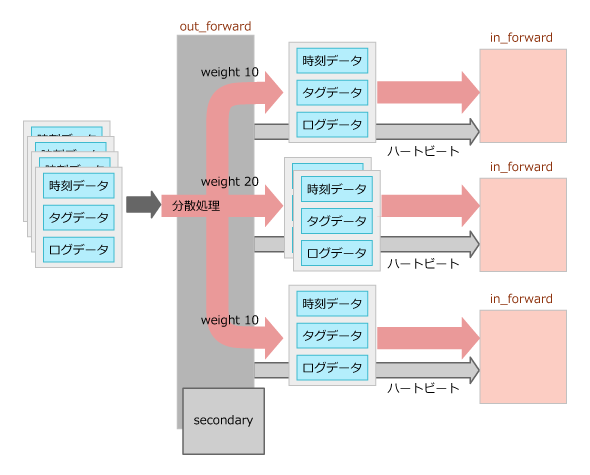 図3 out_forward処理概要
図3 out_forward処理概要・設定例
<match タグパターン>
type forward
send_timeout 60s #ログデータ転送時のタイムアウト時間(デフォルトは60秒)
recover_wait 10s #障害復旧時に、再度振り分け先として登録する前の待ち時間(デフォルトは10秒)
heartbeat_interval 1s #転送先サーバーの稼働チェック間隔(デフォルトは1秒)
phi_threshold 16 #ハートビートによる死活監視の遅延状況を示す値(phi)の閾値(デフォルトは16)
hard_timeout 60s #通信できない転送先サーバーのチェックに対するタイムアウト時間(デフォルトは60秒)
<server> #転送先サーバーの設定
name server-01
port 24224
host server-1.example.com
weight 60 #分散の重み設定(大きい数字のサーバーには、より多くのデータが転送される。デフォルトは60)
</server>
<secondary> #どのサーバーにも転送できなかった時の出力先
アウトプットプラグイン設定
</secondary>
</match>
その他の公開プラグイン
ここまで解説した標準で組み込まれているプラグイン以外にも、fluentdでは非常に多くの有用なプラグインが公開されています。
例えば、AWSの監視サービスである「CloudWatch」からデータを収集するインプットプラグインや、ストレージサービスであるAmazon S3にログデータを出力するアウトプットプラグインなど、クラウドサービスと連携するためのプラグインが提供されている他、「Zabbix」や「Ganglia」などの監視ツールにログデータを出力するアウトプットプラグインまで、環境や用途に合わせ、さまざまなものが公開されています。
| プラグイン名 | 用途 |
|---|---|
| dstat | dstat出力結果取り込み |
| mysqlslowquery | MySQLスロークエリログ取り込み |
| cloudwatch | Amazon CloudWatchのデータ取り込み |
| インプットプラグイン | |
| プラグイン名 | 用途 |
|---|---|
| s3 | Amazon S3にデータ登録 |
| mongo | MongoDBにデータ登録 |
| webhdfs | HDFSにデータ登録 |
| datacounter | インプットで取り込まれたデータを分析し、発生件数、発生頻度、発生割合を算出 |
| zabbix | ZabbixのZabbixトラッパー監視アイテムにデータ登録 |
| growthforecast | グラフ化ツール「GrowthForecast」にデータ登録 |
| アウトプットプラグイン | |
まとめ
第2回目は、fluentdのインストール方法から代表的なプラグインの利用方法までを紹介しました。
おそらく簡単なログ管理であれば、これらのプラグインを適材適所で利用することで実施できるでしょう。その際には、各プラグインの設定パラメーターが何を示すのか、それを指定した場合の挙動がどうなるのかを正しく理解した上で活用することが重要です。
fluentdは、これらプラグインを効果的に組み合わせることでいっそうの効果を発揮します。第3回では実際の利用を想定し、より実践的な利用方法を紹介します。
著者プロフィール
池田大輔
Twitter : @ike_dai
TIS株式会社戦略技術センター所属。社内向けシステムの保守運用業務を経験後、クラウド時代の効率的な統合運用管理をテーマに活動中。特に、OSSを駆使した運用のエコシステム実現を目指し、fluentdなどの導入や検証に取り組む。TIS戦略技術センターでは、技術検証成果などを技術ブログ『Tech-Sketch』にて発信中。著書:『Zabbix統合監視徹底活用 - 複雑化・大規模化するインフラの一元管理』
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。