実装のひと工夫で高速化する技術:Database Watch(2014年5月版)(2/3 ページ)
InfiniDB、高速化の仕掛け
次はDWH専用データベースInfiniDBです。アシストでInfiniDBを担当しているデータベース技術本部 技術開発部 小野明洋氏(写真)に聞きました。

InfiniDBは無限大を表す「∞」の目をしたハチの「インディ」がトレードマークです。開発元であるInfiniDB, Inc. が米国テキサス州にあるため、帽子やスカーフでカウボーイスタイルを表現しているようです。2010年にはエンタープライズエディションを発表し、2012年からは日本市場でも展開されるようになりました。さらに最近では専用サイト「インディの部屋」も開設されました。
データベースとして見ると、InfiniDBはMySQLをベースにした製品です(MySQLのストレージエンジンという意味ではありません)。MySQLのインターフェースが使えるなど、MySQLに慣れた人なら扱いやすい実装になっています。親和性が高いことからMySQLからInfiniDBに移行するケースもあるのだとか。
集計処理に特化し、チューニングがほぼ不要などの特徴を見ると、IBMが買収したNetezzaと共通する部分も見受けられます。例えば、データベースなのにインデックスを持たず「create index」をするとエラーになるところはNetezzaも同じです。
ただし、Netezzaはハードウェアとソフトウェアが一体化しているのに対し、InfiniDBは、あくまでもデータベースのソフトウェアです。また、DWHに特化しているとはいえ、実際にはWebFocusなど、何らかのBIツールと組み合わせて使います。ハードウェアやBIツールを選べるところに自由度があるともいえるでしょう。
InfiniDBの特徴として小野氏が掲げるのは「高速、シンプル、拡張可能」の3つです。
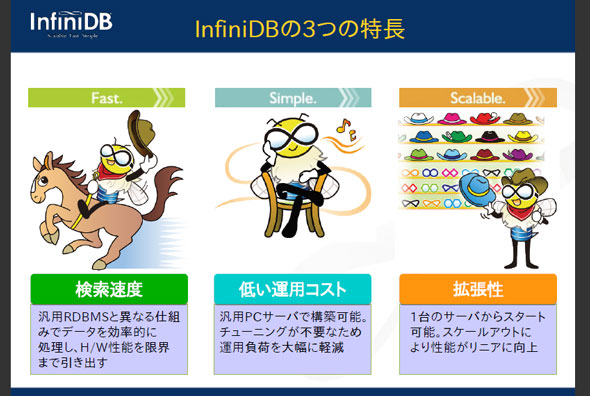 InfiniDBの3つの特長(資料提供:アシスト)
InfiniDBの3つの特長(資料提供:アシスト)高速化の仕掛け
このうち、高速さについては、分析集計処理に最適化された列指向型アーキテクチャを採用していることが大きいでしょう。
独自の列指向実装
汎用的なリレーショナルデータベースの行指向型に対して、列単位でデータを圧縮して格納するため、集計処理に不要な列にアクセスせずに済み、ストレージI/Oを大幅に削減できます。これだけでも行指向型に対しては大きなアドバンテージを持ちます。
列指向型も、ただの列指向ではありません。列データは特定の範囲ごとにブロックに分けて格納しています。サイズにして8〜64MB程度。このブロックをInfiniDBでは「エクステント」と呼び、これのインデックスに相当するのが「エクステントマップ」です。
ん……? どこかで聞いたような気がしませんか。
このエクステントマップの実装は、本稿の前半で紹介したNEC IRSで実装したレンジクラスタと考え方が似ています。特定の列のデータを、範囲ごとにまとめて格納することで、データの読み込みを効率化するというものです。集計処理でまとまった列のデータを読み込むなら、範囲ごとにデータがかたまりになっていた方が扱いやすいのでしょうね。
例として、あるクエリにおいて、RDBMS製品では読み込みデータサイズが80GBのところ、InfiniDBでは列指向や圧縮が効いて20GBを切ることもある、と小野氏は説明します。データベースの処理でネックになりやすいのはデータの読み書き時に発生するI/Oなので、読み込みデータサイズが小さくなればそれだけ有利です。これに加えてInfiniDBには、CPUの使い方にもひと工夫があります。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。