構築・設定・運用・障害対策まで、今すぐできるクラウド時代の運用自動化入門:特集:運用自動化ツールで実現する、クラウド時代の運用スタイル(5)(2/3 ページ)
クラウドの特徴を生かすための運用自動化のポイント
クラウド時代のシステム運用においては、こうしたクラウドの特徴をうまく活用し、運用も含めて昨今のビジネス環境の変化速度に追従できるようにする必要がある。ではそのために、運用面ではどのような点に気を付ける必要があるのだろうか。実際の運用作業を自動化する上で押さえておくべきポイントを、構築・設定、定常運用、障害対策の3つの観点から見てみよう。
構築・設定
従来の環境では、リソースの増強は簡単に行えるものではなく、ハードウェア調達などを進めながら設定する内容を手順書にまとめ、手作業で設定を実施していた。しかしクラウドを利用すれば、「特定の日だけクラウド上のサーバーの台数を増やし、終われば元の台数に戻す」といったことも容易に行えるようになる。そういった場面において、新たに追加したサーバーの設定作業を従来通り手動で行っていたのでは、そのスピードを生かすことができない。
そうした変化を踏まえて、ビジネス要求の変化に迅速に対応するために「Infrastructure as Code」という考え方が広まりつつある。従来の運用とInfrastrcuture as Codeによる運用を対比したのが図1だ。
従来のように、手順書としてまとめた作業内容を手動で行うのではなく、プログラムのコードの形で作業内容を記述し、自動的に構築を行う。これにより、人的ミスを削減しつつ迅速な構築・設定が可能になる。また、作業に人手を介する必要がなくなるため、他のシステムと連携すれば、何らかのイベントを検知して自動的に設定の変更を行うことも可能になる。このInfrastructure as Codeの考え方はクラウド環境に限らず従来の環境でも有用なものであるが、特に頻繁に構成や設定の変更を行うクラウドにおいては重要な概念となる。
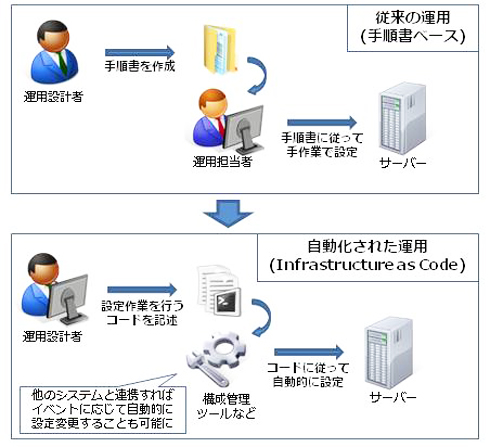 図1. 従来の運用とInfrastructure as Codeによる運用
図1. 従来の運用とInfrastructure as Codeによる運用ここ数年で、Infrastructure as Codeを実践するためのツールやサービスは数多く登場してきている。特によく取り上げられるのは、例えばPuppet、Chef、Ansibleといった、実際にサーバーを起動した後にOSやミドルウェアの各種設定を自動化する構成管理ツールだろう。
こうしたツールをうまく活用できれば、環境の情報やサーバーに持たせる役割に応じて、自動的に適切な設定を施すことが可能になる。また実際にサーバーを起動した後の設定だけではなく、各種クラウドから必要なリソースを調達する部分についても、一部のクラウドではそれを支援するサービスが提供されている。
例えば「AWS CloudFormation」や「OpenStack Heat」では、必要なシステム構成を一定のフォーマットに従って記述しておくことで、その構成を自動的に構築できる。こうしたツールやサービスを組み合わせて利用することで、必要な設定作業を全て自動化することも可能になる。
参考リンク
また近年は、すぐにリソースを確保でき、使用した分だけ費用が発生するクラウドの特性を生かした「Blue Green Deployment」や「Immutable Infrastructure」といった運用手法も注目されている。
これらの手法では、従来のように稼働中の本番環境にバージョンアップなどの変更を加えるのではなく、変更を反映した同じ構成の環境をもう1セット構築し、ユーザーからのアクセスの起点となるルーターやDNSのアクセス先を切り替えることで更新を行う。これにより、本番環境の停止時間を最小限に抑え、何か問題が起きても旧環境に切り戻すことが容易になる。
こういった運用手法は、使いたい時に使いたい時間だけリソースを調達できるクラウドならではの手法であるといえる。そしてこうした運用を行うためには、同じ環境を自動的にもう1セット用意するための構築処理の自動化が欠かせない。これらの手法の詳細については、特集第3回「いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜」でも説明されているので、そちらを参照いただきたい。
スピードというクラウドの利点を生かすためにはテスト自動化も不可欠
こうしたクラウドの特性を生かした運用手法を取り入れて自動化を進めていくと、構成変動に対応するための設定変更や、システム構成自体の再構築自体が頻繁に行われるようになる。しかし、自動的に構築した環境でも、「正しく構築が行われたか」を確認するテストは必要だ。だが、どれほど構築・設定作業が自動化されようと、その後のテスト作業が人手に頼ったままであれば、やはり迅速なリリースを行うことはできない。クラウドの特性を生かした運用を行うためには、構築・設定作業を自動化するだけではなく、それが正しく行われたことを保証するテスト工程の自動化も不可欠となる。
こうしたインフラの自動テストを実現するためのツールの例としては、「Serverspec」や「Infrataster」などが挙げられる。
Serverspecを使えば、「構築が完了したサーバーが意図した通りに設定されているか」を自動的に確認できる。Infratasterでは「外部からのアクセスに対して意図した通りの応答が返ってくるか」を確認できる。こうしたツールを組み合わせて利用することで、自動構築したサーバーが意図通りに稼働しているかを動的にテストすることが可能になる。
定常運用
一度運用フェーズに入れば、基本的にはクラウド上のシステムでも行うべき運用作業の内容にそれほど違いはなく、監視、バックアップ、ログ管理、ジョブ管理といった、従来行っていた作業をそのまま行うことになる。ただし、オートスケーリングのように、クラウドを利用することで新たに可能になった機能を利用する場合は、それに合わせて運用方法を見直す必要がある。
例えばオートスケーリングを利用する場合、負荷の状況などに応じて自動的にサーバーを追加・削減することができる。こうした機能は拡張性を維持しつつコストを最小限に抑える上で非常に有用だが、運用の側面から見れば、いつの間にか管理すべきサーバーが増加・減少することになる。そのため、サーバーの増減に合わせて、監視やバックアップといった運用系のシステムも自動的に対応できなければ、適切な運用を続けることができない。従って、サーバーの増減に合わせて運用管理系システムの設定を自動的に変更する仕組みは不可欠となる。
自動的なサーバーの増減に対応するためには、そうした状況に対応するための機能を持った製品を利用するか、もしくは増減が起こったことを検知して外部から制御を行う必要がある。例えば本特集第2回「徹底比較! 運用監視を自動化するオープンソースソフトウェア10製品の特徴、メリット・デメリットをひとまとめ」でも紹介したOSSの監視ツールであるZabbixの場合、「特定のセグメント内に未登録のサーバーが増えていないか、定期的に確認するAuto Discovery機能」や、「新たなサーバーが起動した際に、自分から管理サーバーに登録申請を行うAuto Registration機能」が用意されている。
また、そうした機能を持たない運用管理製品であっても、同じく本特集第2回で紹介したSerfやConsulのように、「クラスター内のサーバーの増減」といった各種イベントを検出して、適切な処理の呼び出しを行えるオーケストレーションツールを介することで、動的に設定を変更することが可能になる。
障害対策〜リソースの増減が得意なクラウドの特性を生かす〜
従来の物理環境では、障害が起きると原因を調査し、障害が発生したサーバーを復旧させるのが通常だった。クラウドの場合でもそうした対応は可能だが、クラウドではリソースの増減が自在にできるため、サーバーに障害が発生したことを検知した際に自動的に同じ内容のサーバーを再構築して置き換えるといった対応も一つの選択肢となる。
例えば「AWS Elastic Load Balancing」の場合、定期的にサーバーのヘルスチェックが行われており、「Auto Scaling」の機能と組み合わせれば、障害発生時に自動的に同じサーバーを立ち上げ直すことも可能になる。こうしたサービスを活用するためには設定などの作業を全て自動化しておく必要があるが、それを満たすことができれば障害に強いシステムを実現できる。
参考リンク
また、システム構成全体の構築を自動化することができれば、特定の地域のデータセンター全域に障害が発生した場合であっても、別の地域のデータセンター上で同じ構成を自動的に復旧することが可能になる。主要なパブリッククラウドでは、世界中の複数の拠点の中から利用する拠点を選択できることが多いため、大きな災害が起こっても別の国でシステムを再構築すれば、サービスを早期に復旧させることが可能になる。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。