Caffeで画像解析を始めるための基礎知識とインストール、基本的な使い方:いまさら聞けないDeep Learning超入門(2)(2/2 ページ)
Caffeの環境構築の仕方
このように、Caffeには多大なるメリットがある半面、環境構築に少しハードルがあります。
まず、関連するライブラリ群が多く、動かすまでに根気が必要です。
また、GPUを利用して高速で動作させるためにNVIDIAのCUDA(Compute Unified Device Architecture)が必要で、こちらもインストールする必要があります。GPUの使える環境に関しては、Amazon EC2のGPUインスタンスなどクラウド環境がお手軽です。
以下に、必要なモジュール郡とインストール方法と簡単な役割を示します。
| モジュール名 | インストール方法 | 役割 |
|---|---|---|
| OpenCV | wget/make | 画像の切り抜きなどの加工に利用 |
| Gflags | wget/make | コマンドラインオプション機能を提供するC++ライブラリ |
| Glog | wget/make | ログ用のC++ライブラリ |
| LevelDB | wget/make | 高速処理用のKVSのDB。学習やテスト時にデータをDBにまとめて利用 |
| LMDB | wget/make | LevelDB同様、KVSのDB。DBへの同時アクセスが可能 |
| snappy-devel | yum | LevelDBデータの圧縮/解凍に利用 |
| atlas-devel | yum | 線形代数演算の高速化に利用 |
| protobuf-devel | yum | データのシリアライズに利用 |
| boost-devel | yum | メモリ管理・シリアライズ・型の制御など、さまざまな機能を提供するC++ライブラリ |
| anaconda | wget/sh実行 | Pythonで利用する際に必要なモジュールが全て含まれている |
| CUDA | wget/sh実行 | GPU利用のためのSDK |
CUDAの利用に関しては、「Nouveau」を無効化しなければコンフリクトを起こしてしまうため、こちらを無効化してください。
なお、CUDA以外の上記設定が大変な場合は、Dockerを利用する手もあります。CUDAの利用を有効にしたGPUインスタンス上にDockerを用意し、Caffeが使えるコンテナーを取得することでCaffeの利用が可能となります。
Caffeの基本的な使い方
「CNNとは?」の箇所で述べた通り、CNNではネットワーク定義と重みの学習が重要です。今回は、これらの記述方法について、Caffeに梱包されている「MNIST」の画像セットを対象としたファイルの中身を見ながらブレークダウンしていきます。
なお、CaffeのソースはGitHub上にありますので、そちらに沿った形で説明します。以下の説明で「$CAFFE_DIR」という表現が出てきますが、これはGitHubからクローンした直下のディレクトリを指しています。
【1】ネットワーク定義
lenet_train_test.prototxtというファイルに、Convolution層やPooling層などの処理の順番とパラメーター設定を定義します。ネットワーク定義ファイルの例は以下です。
 $CAFFE_DIR/examples/mnist/lenet_train_test.prototxtの一部抜粋
$CAFFE_DIR/examples/mnist/lenet_train_test.prototxtの一部抜粋
ネットワーク定義ファイルは、JSONのような形式で、レイヤーごとに分けて記載するルールとなっています。各レイヤーには、「name」「type」「bottom」「top」およびレイヤーの種類ごとのパラメーターが記載されます。nameはレイヤーを意味付ける任意の文字を、typeはそのレイヤーの種類を、bottomはそのレイヤーへのインプットを、topはそのレイヤーのアウトプットを意味します。
上図の左がDataレイヤーで、画像データと正解カテゴリが出力されるのでtopが二つ設定されています。「transform_param」は正規化に利用する値で、RGBやグレースケールの値を正規化する意味で「0.00390625(=256分の1)」がセットされています。「data_param」は学習に利用するDBの種類と名前、一度の学習で何枚を同時に処理するかという「batch_size」を指定します。
上図の真ん中はConvolutionレイヤーで、bottomにDataレイヤーのdataを指定します。「num_output」が出力する特徴量の数を指しており、「karnel_size」がパッチ画像の一辺の長さを、「stride」がパッチ画像を取得するときにスライドさせるサイズをそれぞれ示しています。これらの設定で、topで指定している「conv1」を出力とします。
上図の一番右がPoolingレイヤーです。このbottomには、先ほどのconv1が指定されており、Convolutionの結果を受け取ることが明示されています。そして、karnel_sizeでまとめ上げるサイズを、strideでスライドするサイズを指定します。出力は、topにセットされた「pool1」となります。
下図はConvolutionとPoolingのイメージです。
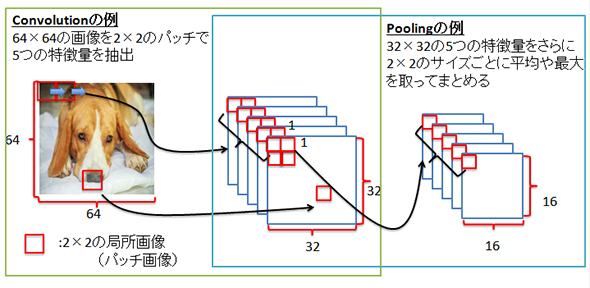
今回は抜粋のため全てを記載してはおりませんが、実際にはこの後にpool1を受け取って、「conv2→pool2→Full Connect1→ReLU[活性化関数]→Full Connect2」といったようにネットワーク定義が続いていきます。
【2】solver定義ファイル(重みの学習方法を設定)
solver定義ファイルは、重みの学習方法を設定するためのファイルで、以下のような形式を採ります。
[lenet_solver.prototxt] net: "examples/mnist/lenet_train_test.prototxt" test_iter: 100 test_interval: 500 base_lr: 0.01 momentum: 0.9 weight_decay: 0.0005 lr_policy: "inv" gamma: 0.0001 power: 0.75 display: 100 max_iter: 10000 snapshot: 5000 snapshot_prefix: "examples/mnist/lenet" solver_mode: CPU
「net」には、【1】のネットワーク定義ファイルを指定します。「test_iter」には、精度評価時の順伝播回数を指定します。テスト用の全画像枚数を、テスト時のネットワーク定義時のbatch_size(1回の学習に利用する枚数)で割った値を入れることが標準的です。
「test_interval」は、精度評価を挟む学習回数を指定します。この設定は、チューニングを効率良く実施するために重要です。この設定により得られる精度の表示が、今回の学習が精度向上の見込みが高いかどうかを早期に発見する指標となります。「base_lr」〜「power」には、学習時の学習率の初期値・更新方法・正規化の重みなどを設定します。
「max_iter」は、学習を繰り返す最大の回数です。test_intervalでの精度結果を見ながら、まだ精度が伸びそうであれば、これを上げると精度向上が見込まれます。
「snapshot」は、指定回数ごとの状態を保存するための設定です。これがあることにより、途中から学習を開始することなどが可能となります。
最後の「solver_mode」は、学習にGPUを利用するかCPUを利用するかを指定します。
コマンドで学習を開始
これら設定の完了後、以下のコマンドで学習を開始します。
$CAFFE_DIR/build/tools/caffe train -solver= lenet_solver.prototxt
次回は、大規模サービスにおけるCaffeやCNNの活用事例
以上がCaffeにおけるネットワーク定義および重みの学習方法を設定するファイルの設定および実行の説明です。Caffeには、まだまだ紹介しきれていないたくさんの機能がありますが、本稿が少しでもお役に立てば幸いです。
次回はリクルートグループのサービスの中で、どのようにCNNが活用されているかを紹介します。
筆者紹介
白井 祐典(しらい ゆうすけ)
リクルートテクノロジーズ ITソリューション統括部 ビッグデータ部
独立系SIerで2年半働き、2012年にリクルートテクノロジーズ ビッグデータ部に中途入社。以降、3年にわたってカーセンサー(リクルートマーケティングパートナーズ提供)におけるHadoopを用いたビッグデータ活用に従事。現在は、事業対応とともに画像解析の技術検証とディレクション業務に従事。
関連記事
 グーグルの人工知能を利用できるWebインターフェースが登場
グーグルの人工知能を利用できるWebインターフェースが登場
オズミックコーポレーションとイントロンワークスは7月7日、グーグルの人工知能アルゴリズム「Deep Dream」を利用できるWebインターフェースを公開した。 顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成――デザイナー/クリエイターが茫然自失で拍手喝采な最先端技術動画11連発
顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成――デザイナー/クリエイターが茫然自失で拍手喝采な最先端技術動画11連発
アドビ システムズは、2015年10月6日(現地時間)に開催した「Adobe MAX 2015 Sneak Peeks」で、11の新技術を披露。顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成naなど、今回もデザイナー/クリエイターのみならず、日常的にデジカメやスマホで写真を撮る人でも欲しくなるような機能が多数見られた。 米AlpacaDBがDeep-Learningを使った金融プラットフォームを開発へ
米AlpacaDBがDeep-Learningを使った金融プラットフォームを開発へ
Deep-Learning技術による画像認識プラットフォームを展開してきたAlpacaDBが、資金調達に成功し、金融系の事業領域に本格進出する。 セキュリティ対策に数学の力を――機械学習は先行防御の夢を見るか?
セキュリティ対策に数学の力を――機械学習は先行防御の夢を見るか?
どうしても攻撃者の後手に回りがちなセキュリティ対策。ここに機械学習を活用することで、先手を打った対策を実現できないか――そんな取り組みが始まろうとしている。 個人と対話するボットの裏側――大衆化するITの出口とバックエンド
個人と対話するボットの裏側――大衆化するITの出口とバックエンド
マシンラーニング、ディープラーニングなど、未来を感じさせる数理モデルを使ったコンピューター実装が注目されている。自ら学習し、機械だけでなく人間との対話も可能な技術だ。では、コンピューターはどのように人間との対話を図ればよいのだろうか。コンピューターの技術だけでなく、そこで実装されるべきインターフェースデザインを考えるヒントを、あるコンシューマーアプリ開発のストーリーから見ていく。 自動車を制御するロボットの思考と行動の仕組み――Google Carが現実世界を認識する際の3つのアルゴリズムと実用化への課題
自動車を制御するロボットの思考と行動の仕組み――Google Carが現実世界を認識する際の3つのアルゴリズムと実用化への課題
本連載では、公開情報を基に主にソフトウエア(AI、アルゴリズム)の観点でGoogle Carの仕組みを解説していきます。今回は、制御AIの思考と行動のサイクル、位置推定の考え方「Markov Localization」における3つのアルゴリズムと、その使い分け、現実世界の認識における課題などについて。 バンナム、スクエニ、東ロボ、MS――人工知能や機械学習はゲーム開発者に何をもたらすのか
バンナム、スクエニ、東ロボ、MS――人工知能や機械学習はゲーム開発者に何をもたらすのか
8月26日に開催されたゲーム開発者向けイベントの中から、バンナム、スクエニ、東ロボ、MSなどによる人工知能や機械学習、データ解析における取り組みについての講演内容をまとめてお伝えする。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。