「Deep Learningをサービスに導入したい!」人に周囲が泣かされないために:機械学習活用プロジェクト大解剖(2)(1/3 ページ)
サイト内検索のランキングアルゴリズムに機械学習を活用した事例を通じて、Deep Learningをはじめとした機械学習の強みと限界を探る連載。今回は、機械学習を活用しやすくする開発・運用体制や、機械学習を実際に活用する人が意識することについて解説します。
リクルートテクノロジーズにおける検索改善施策の事例を通じて、Deep Learningをはじめとした機械学習の強みと限界を探る本連載「機械学習活用プロジェクト大解剖」。
前回は、検索改善のためのアーキテクチャ(QueryRewriter)とDeep Learningを導入する動機を紹介しました。今回は、「Deep Learningの導入のために何が必要であり、なぜQueryRewriterが開発されたのか」について解説します。
- 今回話す内容
- 次回話す内容
- 具体的な改善事例
- 検索改善に本当に必要だったもの
より具体的な改善事例は次回解説します。
機械学習を活用しやすくする開発・運用体制――2つのアンチパターン
まず、「とにかくDeep Learningを使いたい!」というようなデータサイエンティストに周囲を泣かされないための仕組みと開発・運用体制について考えます。
新しい技術を導入する際は、何であれ慎重に進めた方がいいです。Deep Learningのような解釈可能性が極めて低い手法を導入する場合は、特にそうです。
しかも、精度を高めるために逐次的に機械学習のモデルを更新していく場合は、最終アウトプットが将来の入力データに依存するため、サービス導入以前に完全なテストを実施することは不可能です。このような不安定なものを実際のサービスに導入する際に、可能な限り失敗しないように知恵を絞るのは非常に重要です。しかし、失敗しないことよりも、「失敗した場合のダメージをいかに最小に抑えるか」の方に重点をおくべきです。
機械学習のサービス導入後の失敗は大きく分けて下記の2つがあります。ここでは、サービス導入前の失敗、例えば「データ不備により開発できなかった」は導入前のサービスにとって直接的な悪影響があるわけではないので無視します。
- 【失敗パターン1】エラーを出してサービスに悪影響を与えた
- 【失敗パターン2】精度に課題がありサービス改善にならなかった
【失敗パターン1】エラーを出してサービスに悪影響を与えた
【失敗パターン1】は機械学習に関係なく、開発全般でいえる失敗でもあります。とはいえ、機械学習は「最終アウトプットが入力データに依存する性質」があることから、開発環境での網羅的なテストが相対的に難しく、いくら入念な事前テストをしても幾つかの課題は出てきてしまいます。
特にDeep Learningでは「さまざまな種類・性質の入力を大量に使いたい」「学習アルゴリズムの挙動が分かりづらい」などの理由で、見つけにくい課題が生まれやすいです。そのため、念入りなテストや値チェックの機構が重要になりますが、「取りあえず実験的に機械学習を導入してみよう」という段階での非常に念入りなテストは開発期間の長期化とコスト増大を招き、スピードが求められる開発にはフィットしません。
しかし、サービス改善のための強力なツールである機械学習を、リスクを理由にいつまでも導入しないでいるわけにはいきません。そこで、機械学習導入のリスクをいかに最小化するか、つまり失敗した場合の影響を最小化する仕組みについて考えます。
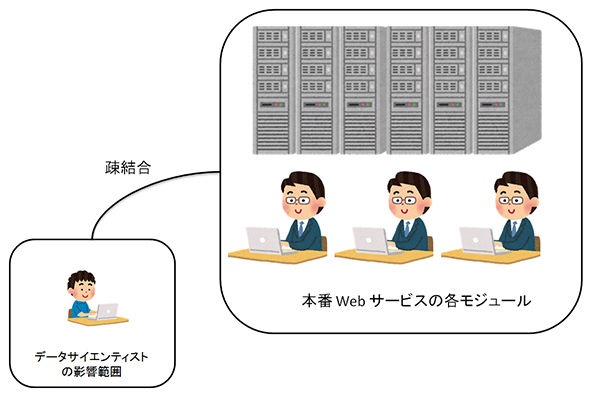 図1 データサイエンティストの影響を閉じ込める(前回の図1にある通り、QueryRewriterはアプリケーション本体から切り離されている)
図1 データサイエンティストの影響を閉じ込める(前回の図1にある通り、QueryRewriterはアプリケーション本体から切り離されている)これはプログラミングの世界における「特定のモジュール変更による影響範囲をどのように抑えるか」と同じ問題です。データサイエンティストの機械学習モジュールの責任範囲を明確にし、その他のモジュールとの結合度を最小にすると影響範囲を小さくできます。
【回避方法1】影響範囲をSolrクエリに限定
われわれの検索改善プロジェクトでは、機械学習の結果を検索ランキングアルゴリズムに反映させています。実装面では、QueryRewriterの中で、もともとのSolrクエリにファンクションクエリを追加し、追加したファンクションクエリの出力値をソートキーに追加する処理を行っています。
Solrのファンクションクエリでは、Solrのインデックス内の値や他のクエリのスコア(テキスト検索時のBM25類似度など)を足したり掛けたり階乗したりすることで、ある程度複雑な計算をSolrの内部の処理に付け加えることができます。
後は、この出力値でSolrレスポンスのアイテムを並び替えればランキングアルゴリズムになります。これはSolrの外からのクエリで制御できるため、Solr内部を大きく変更することなしにランキングアルゴリズムだけを変えることができます。影響範囲をSolrクエリに限定することで、変更作業(多くは新しいランキングアルゴリズムのテスト)によって変更される箇所は、その時のSolrへのリクエストのレスポンスの並び順だけになります。
【回避方法2】A/Bテストを実施し、瞬時にテストパターンの割合を変える
また新しいランキングアルゴリズムを導入する際は、A/Bテストを実施することにしています。ランキングアルゴリズムを大きく変更する際は、テストパターンの割合を小さくした状態からテストし、影響範囲を一部のカスタマーに限定させます。
さらに、瞬時にテストパターンの割合を変えられる機能も導入しています。この機能によって、新しいランキングアルゴリズムの不備で不測の事態が起きた場合でも、すぐにテストを中止できます。これも影響を限定しやすくするための工夫です。
このように、検索ランキングアルゴリズムの新規導入や変更の際の影響範囲を極めて限定的にすることで、Deep Learning の導入などの挑戦的な取り組みを行いやすくしています。
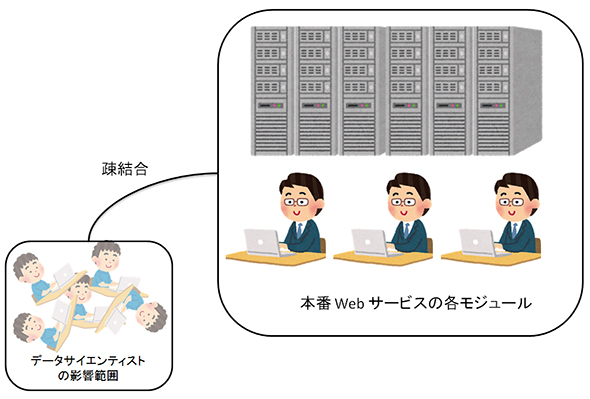 図2 データサイエンティストは、影響が限定されることで、かえって自由に動ける(前回の図3にあるように、QueryRewriterは無停止でロジックを更新できるので、リリース時期の自由度も高い)
図2 データサイエンティストは、影響が限定されることで、かえって自由に動ける(前回の図3にあるように、QueryRewriterは無停止でロジックを更新できるので、リリース時期の自由度も高い)【回避方法3】クエリの書き換えしか行わない
また、クエリの書き換えしか行わないことで、エラーを発生させた場合もサービスへの悪影響を最小化しています。何らかのエラーを検知した場合に直ちに書き換えを行わないようにすれば、新しいランキングアルゴリズムは利用されないものの、検索自体は従来通りに行われるため、サービスへの悪影響はなくなります。
もし、これが既存クエリの書き換えだけではなく、新しく検索エンジンを作ってしまった場合はどうなるでしょうか。その場合は「万が一に備え、従来通りの検索を可能にしておくため2つの検索エンジンも運用し続ける(実質使っていない)」または「新しい検索エンジンにエラーが発生した場合は深刻なサービス障害が引きおこる」のどちらかになります。両方共、良い選択肢ではないです。
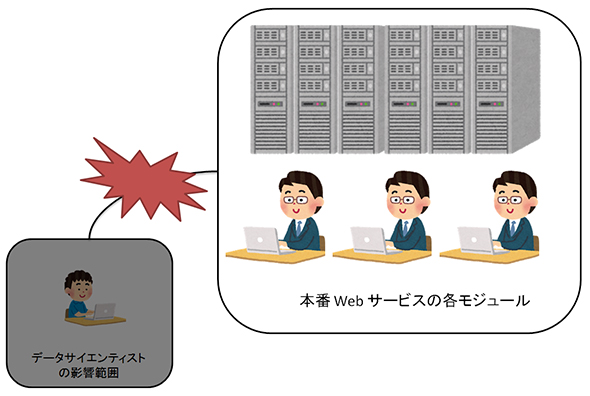 図3 データサイエンティストの働きが意図通りでない場合に備え、切り離しやすくしておく(前回の図2にあるようにQueryRewriterはフェイルオーバー機能に対応している)
図3 データサイエンティストの働きが意図通りでない場合に備え、切り離しやすくしておく(前回の図2にあるようにQueryRewriterはフェイルオーバー機能に対応している)関連記事
 事例で分かるデータ分析プロジェクトの進め方の基本
事例で分かるデータ分析プロジェクトの進め方の基本
ビジネスのデータ分析業務に12年ほど関わる筆者の経験に基づきデータ分析のプロジェクトがどのようなものかをお話しします。 リクルートの有名サイト事例に見る、シナリオベースABテストの基本的な考え方と改善プロセス、チーム体制
リクルートの有名サイト事例に見る、シナリオベースABテストの基本的な考え方と改善プロセス、チーム体制
ABテストを利用したサイト改善の限界にぶつかっている人たちに向けて、リクルートグループ内で実践している改善ノウハウをお伝えする連載。初回はユーザー体験(シナリオ)の良しあしの検証と、改善するABテストの基本的な考え方、サービス改善PDCAプロセス、チーム体制について。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。