UbuntuでのGPUディープラーニング環境の構築【Ubuntu 16.04 LTS対応】:機械学習&ディープラーニング環境構築入門(3/4 ページ)
2. NVIDIA GPU環境の準備
NVIDIA GPUを使用するには、まずはそのドライバーと開発環境であるNVIDIA CUDA Toolkit(単にCUDAとも表現される)をインストールする必要がある。また、ディープラーニング環境を構築するためには、ディープ・ニューラル・ネットワーク(DNN)ライブラリのcuDNNをインストールする必要がある。さらに必要に応じて、GPUが使えるDockerであるnvidia-dockerのインストールもこのタイミングで行うとよい。
この章では、こういったNVIDIA GPU環境の構築方法を説明する。CPUを使う場合は、この章はスキップしてよい。
2.1. NVIDIAドライバーとCUDA Toolkitのバージョン要件の確認
ドライバーも、CUDA Toolkitも、基本的には最新版をインストールしておけば問題ないはずである。しかし、使いたいディープラーニングのライブラリによっては、CUDA Toolkitのバージョン要件が細かく指定されている可能性があるので、念のために事前に調べるようにしてほしい。
執筆時点でCUDA Toolkitの最新バージョンは9.1であるが、例えばTensorFlowの場合、
- CUDA Toolkit 9.0
- CUDA Toolkit 9.0に対応したNVIDIAドライバー
- cuDNN v7.0
- CUDA Compute Capability 3.0以上のGPUカード
- libcupti-devライブラリ(NVIDIA CUDA Profile Tools Interface)
というサポート要件が指定されている。
なお、ここで言う「GPUカード」とはNVIDIA製のグラフィックボード(=ビデオカード)のことで、各GPUカードのCompute Capability(計算能力)はこちらの公式ページで調べられる。公式ページによると、本稿で使用したGPUカードの「GeForce GTX 1060」は6.1で、「Tesla M60」は5.2となっており、どちらも上記の要件をクリアしている。最新のNVIDIA GPUを使っていればこの要件は問題なくクリアできる可能性が高いので、心配する必要はないだろう。
上記の「CUDA Toolkit 9.0」はUbuntu 17.04と16.04 LTSをサポートしている(※14.04 LTSはサポートしていない)。TensorFlow自体はUbuntu 16.04 LTS以降をサポートしている。
現在使用中のUbuntuバージョン用にCUDA Toolkitの各バージョンが提供されているかは、CUDA Toolkit Archiveから確認するとよい。まず使いたいCUDA Toolkitのバージョン(今回は9.0)を選択して、[Operating System]欄はLinux、[Architecture]欄はx86_64、[Distribution]欄はUbuntuを選択すると、対応するUbuntuバージョンを確認できる(図6)。
![[CUDA Toolkit 9.0]をクリック](https://image.itmedia.co.jp/ait/articles/1804/18/di-06-1.gif)

2.2. NVIDIAドライバー(=CUDAドライバー)
インストールするCUDA Toolkitのバージョンを決めたら、次にPCに搭載したNVIDIA GPUカードを認識させるためのドライバーをインストールする。
対応ドライバーは、こちらで検索できる。
- 製品のタイプ: Tesla
- 製品シリーズ: M-Class
- 製品ファミリー: M60
- オペレーティングシステム: Linux 64-bit Ubuntu 16.06 (※「全てのオペレーティング システムを表示する」を選択すると選択肢が増える)
- CUDA Toolkit: 9.0 (※選択した製品によっては表示されない。その場合は選択なしのままでよい)
- 言語: Japanese
上記のような条件を指定して検索したページから、ドライバーのDebian用インストーラーパッケージ(.debファイル)をダウンロードする。通常どおりクリックしてダウンロードしてもよいが、本稿ではwgetコマンドを使う方法で説明しよう。まず、検索結果のページ上にある[ダウンロード]をクリックして、次のページの[ダウンロードの同意]ボタンリンクを右クリックしてリンクのアドレスをコピーし、リスト2.1のようにコマンドを実行する(※当然ながら、wgetに指定するダウンロードリンクは、各自でコピーしたものに差し替える必要がある)。
$ wget http://jp.download.nvidia.com/tesla/384.125/nvidia-diag-driver-local-repo-ubuntu1604-384.125_1.0-1_amd64.deb \
-O nvidia-driver.deb
このコマンド例ではnvidia-driver.debファイルがダウンロードされる。
それでは、ダウンロードしたdebパッケージからドライバーをインストールしよう。リスト2.2のようにコマンドを実行する(※ファイル名は適切なものに差し替えてほしい)。
$ sudo dpkg -i nvidia-driver.deb
……省略……
The public CUDA GPG key does not appear to be installed.
To install the key, run this command:
sudo apt-key add /var/nvidia-diag-driver-local-repo-384.125/7fa2af80.pub
$ # 上記の指示に従って、次のコマンドも実行
$ sudo apt-key add /var/nvidia-diag-driver-local-repo-384.125/7fa2af80.pub
$ sudo apt -y update
$ sudo apt -y install cuda-drivers
最後に、アップグレード可能なパッケージはアップグレードして、念のため再起動もしておこう(リスト2.3)。
$ sudo apt -y upgrade
$ sudo reboot
以上でNVIDIAドライバーのインストールは完了だ。
2.3. NVIDIA GPUの状態確認
これでNVIDIA GPUが認識されて使えるようになったはずだ。さっそくリスト2.4のコマンドを実行して、正常にNVIDIA GPUカードが認識されているかを確認してみよう。
$ lspci | grep -i nvidia
f1d2:00:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1)
lspciコマンドとgrepコマンドで、nvidiaという表記(大文字と小文字を区別しない)があるPCIデバイスを絞り込んで表示している。確かにTesla M60というNVIDIA GPUが確認できる。
さらに、NVIDIAのシステム管理インターフェースを意味するnvidia-smiコマンドを実行して、NVIDIA GPUが利用可能な状態かを確認してみよう。リスト2.5のように表示されるはずだ。Driver Version: 384.125という表記がドライバーバージョンになる(※参考:最新のドライバーのバージョン情報は「公式サイト:ドライバー(日本版)」や「同(通常英語版)」で参照できる)。
$ nvidia-smi
Wed Apr 18 08:23:08 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.125 Driver Version: 384.125 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M60 Off | 00002621:00:00.0 Off | Off |
| N/A 29C P0 37W / 150W | 0MiB / 8123MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
ちなみにnvidia-smiコマンドは、GPUの実行状態を確認する際によく使うので、ぜひ覚えてほしい。
2.4. nvidia-docker(OS環境切り替え)[オプション]
nvidia-dockerは、NVIDIAが公式に提供している「NVIDIA GPUをDockerでも有効にするためのDockerエンジンユーティリティ」で、すでにバージョン2.0がリリースされている。なお、nvidia-dockerのベースとなっているNVIDIAコンテナー・ランタイム・ライブラリである「libnvidia-container」は執筆時点ではまだベータリリースである。
前述したように、nvidia-dockerを使うと、DockerコンテナーごとにUbuntuのバージョンを切り替えられるようになる。Chainer、TensorFlowなど、ディープラーニングのライブラリは多数あり、必要に応じて使い分けが必要になる可能性があるが、その場合に、大本(おおもと)のOSレベルで切り替えられるようになる。Dockerコンテナーは非常に素早く起動し、作成・利用・削除も手軽であることから、1つのライブラリしか使わないと決めている人でなければ、ここでインストールするとよい。もちろん後からインストールすることも可能なので、必要になったらインストールするということでも構わない。
なお、「複数のディープラーニングのライブラリを使い分けるのに、なぜ環境を切り替える必要があるのか」と思った人もいるかもしれない。これは、各ディープ・ラーニング・ライブラリの要件(主にcuDNNライブラリやPythonなどの対応バージョン)が異なっているからである。全てのライブラリ要件を満たす環境を構築するのは、1つのライブラリの要件を満たす環境を構築するのに比べて大変であり、実際に複数ライブラリが動く環境が作れたとしても、久しぶりに別のライブラリを動かしてみたら、以前は動作していたライブラリが動作しなくなっていたという状況が起こりかねない。このような問題に対処し続けるよりは、必要に応じてDockerコンテナーでまっさらな環境を新規構築して、必要なくなったら捨てるというやり方の方が気軽で健全である。
というわけで筆者としては、多少のオーバーヘッドはあるかもしれないが、nvidia-dockerの使用をお勧めする。
2.4.1. nvidia-dockerを使う場合のシステム構成
nvidia-dockerによるシステム構成は、図7に示すようになる。
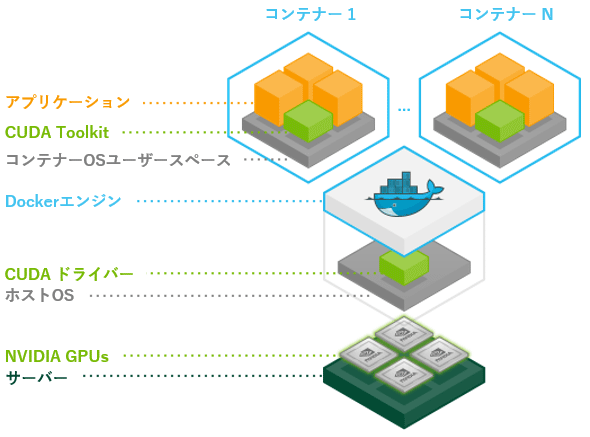 図7 nvidia-dockerのシステム構成例(
図7 nvidia-dockerのシステム構成例(- サーバーマシン上にNVIDIA GPUs(※複数搭載可能なためsが付与されている)が搭載され、その上にホストOS(Ubuntu)が存在する。
- ホストOSの上にはCUDAドライバー(=本稿ではNVIDIAドライバーと表現)があり、その上にDockerエンジンがある。
- nvidia-dockerでコンテナーOS(Ubuntu)を実行する際に、CUDA Toolkitを含めて起動することができる(詳細後述)。その上で任意のアプリケーションを実行する。このようなコンテナーは1〜N個と複数作成できる。
それでは、nvidia-dockerをインストールし、コンテナーを1つ作って起動してみよう。
2.4.2. Docker
まずはDocker本体のインストールが必要である。本稿ではDocker CE(Community Edition、コミュニティ版)をインストールした。利用要件やインストール方法は、公式ドキュメント(日本語)を参照してほしい。ここでは参考までにどのようなコマンドを実行したのかを、リスト2.6に提示しておこう。
$ # パッケージインストール前に念のため、apt用リポジトリをアップデート
$ sudo apt update
$ # 「HTTPS越しにリポジトリを使うためのapt」を有効にするパッケージをインストール
$ sudo apt -y install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
$ # Dockerの公式GPG鍵を追加:
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | \
sudo apt-key add -
$ # 鍵の指紋(fingerprint)が「9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88」かを、指紋の最後の8文字を検索することによって検証する
$ sudo apt-key fingerprint 0EBFCD88
pub 4096R/0EBFCD88 2017-02-22
フィンガー・プリント = 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88
uid Docker Release (CE deb) <docker@docker.com>
sub 4096R/F273FCD8 2017-02-22
$ # stable(安定版)リポジトリをセットアップする。「amd64」は、x86_64(=64 bitのARMv8)のこと(「uname -m」コマンドを実行すると、「x86_64」と表示される)。他には「armhf」(=32 bitのARMv7、Raspberry Piなど)」や「s390x」(=IBM z Systems)がある。「lsb_release -cs」コマンドは「xenial」(参照:前掲の脚注*3)となる。
$ sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
$ # Dockerの最新版をインストール
$ sudo apt update
$ sudo apt -y install docker-ce
$ # インストールされたDockerのバージョンを確認
$ sudo docker version
Client:
Version: 18.03.0-ce
API version: 1.37
Go version: go1.9.4
Git commit: 0520e24
Built: Wed Mar 21 23:10:01 2018
OS/Arch: linux/amd64
Experimental: false
Orchestrator: swarm
Server:
Engine:
Version: 18.03.0-ce
API version: 1.37 (minimum version 1.12)
Go version: go1.9.4
Git commit: 0520e24
Built: Wed Mar 21 23:08:31 2018
OS/Arch: linux/amd64
Experimental: false
$ # 「hello-world」イメージを実行することによって、Docker CEが正常にインストールされたかを検証
$ sudo docker run hello-world
……省略……
Hello from Docker!
This message shows that your installation appears to be working correctly.
……省略……
$ # dockerグループにユーザーを追加してsudoなしでも実行できるようにする(ここでは「既に存在します」となっているが、念のため実行している)
$ sudo groupadd docker
groupadd: グループ 'docker' は既に存在します
$ sudo gpasswd -a $USER docker
ユーザー <現在のユーザー名> をグループ docker に追加
$ newgrp docker
2.4.3. nvidia-docker
続いて、NVIDIAが提供するnvidia-dockerをインストールする。要件などの詳細は、公式ドキュメントを参照してほしいが、本稿の内容でインストールしてきたのであれば要件はクリアしているはずなので、あとはリスト2.7のコマンドを実行すればよい。
$ # Ubuntuディストリビューション用のnvidia-dockerリポジトリを構成する
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ # nvidia-docker2パッケージをインストール
$ sudo apt update
$ sudo apt -y install nvidia-docker2
$ # Dockerデーモン構成をリロード
$ sudo pkill -SIGHUP dockerd
以上でnvidia-dockerのインストールは完了だ。
2.4.4. Dockerコンテナー上でのGPU状態の確認
さっそく、NVIDIAが提供するDockerイメージをrunしてGPU付きコンテナーを起動し、コンテナー上にある任意のコマンドを実行してみよう(リスト2.8)。
$ # Dockerコンテナー上でGPUが利用可能かを確認するためにnvidia-smiコマンドを実行
$ docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
Wed Apr 18 09:34:24 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.125 Driver Version: 384.125 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M60 Off | 00002621:00:00.0 Off | Off |
| N/A 30C P0 35W / 150W | 0MiB / 8123MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
$ # CUDA Toolkit 最新バージョンのイメージでコンテナー上のコマンドをテスト実行
$ docker run --runtime=nvidia --rm nvidia/cuda nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2017 NVIDIA Corporation
Built on Fri_Sep__1_21:08:03_CDT_2017
Cuda compilation tools, release 9.0, V9.0.176
$ # CUDA Toolkit 9.0+cuDNN 7.0のイメージでコンテナー上のコマンドをテスト実行
$ docker run --runtime=nvidia --rm nvidia/cuda:9.0-cudnn7-devel nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2017 NVIDIA Corporation
Built on Fri_Sep__1_21:08:03_CDT_2017
Cuda compilation tools, release 9.0, V9.0.176
※docker run --runtime=nvidiaコマンドの代わりに、nvidia-docker runコマンドも使えることを確認しているが、公式ページの記述方法に倣い、前者の書き方で説明している。
リスト2.8を見ると分かるように、Dockerコンテナー上でGPUが認識されていることが確認できた。
docker runコマンドに指定されている各引数には、次の意味がある。
- --runtimeオプション: コンテナーのために使われるランタイム。ここではnvidiaランタイムが指定されている。
- --rmオプション: コンテナー終了時にそれを自動的に削除するモード。コマンドをテスト実行したいときに使いやすい。
- nvidia/cudaイメージ: Dockerイメージ。ここではNVIDIA CUDA Toolkitの最新(latest)バージョンがインストール済みのDockerイメージが指定されている。
- nvcc --versionコマンド: NVIDIA CUDAコンパイラードライバーのバージョン情報を出力するために、--versionコマンドライン引数を付けてnvccコマンドを実行している。
3つ目のコマンド実行では、nvidia/cudaではなく、nvidia/cuda:9.0-cudnn7-develというイメージが指定されている。これは、CUDA Toolkit 9.0+cuDNNライブラリ7.0+CUDA開発環境(devel)がインストール済みのDockerイメージであることを意味する。このように、NVIDIAはnvidia-docker用に各バージョンがインストール済みのDockerイメージを提供しており、後述するCUDA Toolkit 9.0やcuDNNライブラリはインストールしなくてもすぐに実行できる状態が整っている。どのようなイメージがあるかは、次のリンク先を参照してほしい。
nvidia/cudaリポジトリでは、下記の3つのフレーバーのDockerイメージが提供されている。
- base: 事前ビルドされたCUDAアプリケーションを展開するための最小構成のイメージ。CUDA Toolkit 9.0以降のみ。
- runtime: CUDA toolkitから全ての共有ライブラリを追加したCUDA実行用のイメージ。
- devel: 共有ライブラリだけでなくコンパイラーチェーン、デバッグ用ツール、スタティックライブラリなどが追加されたCUDA開発用のイメージ。
以上で、nvidia-dockerを利用できる環境が整った。
2.4.5. GPU付きDockerコンテナーの実行
上記のnvidia/cuda:9.0-cudnn7-develイメージでGPU付きDockerコンテナーを作成して起動すれば、あとはアタッチして使えばよい。この手順を簡単に紹介しよう。
なお、このイメージを使った場合には、CUDA ToolkitやcuDNNライブラリのインストールは不要なので、この後の2.5と2.6の手順はスキップしてほしい。2.7の「CUDA Profiling Tools Interface(libcupti-devライブラリ)のインストール」からの手順は必要になる。
$ docker run --runtime=nvidia --name mycontainer -d -it -p 7777:8888 nvidia/cuda:9.0-cudnn7-devel bash
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
106f31d27600 nvidia/cuda:9.0-cudnn7-devel "bash" 10 minutes ago Up 10 minutes 0.0.0.0:7777->8888/tcp mycontainer
まずdocker runコマンドに指定されている各引数のうち、まだ説明していないものには以下がある。
- --name mycontainerオプション: コンテナーの名前。ここではmycontainerという名前が指定されている。
- -dオプション: デタッチドモードで起動するモード。コンテナーがバックグラウンドで実行され続ける。前述の-rmオプションと違い、終了しても削除されない。
- -itオプション: -i(=--interactive)と-t(=--tty)の2つのオプションが合体している。これにより、ターミナル上でコンテナーの標準入出力ができるようになる。
- -p 7777:8888オプション: 外部からアクセスされるポート番号(この例では7777)とコンテナー側のポート番号(この例では8888)を指定。コンテナー側のJupyter Notebookにホスト側からアクセスしたりするときに使用する。
コンテナーが作成できたので、あとはこれにアタッチする(リスト2.10)。コンテナー側のbashシェルセッションに入るので、そこで以降の各種インストール処理を実行すればよい(※この例ではrootユーザーによるコマンド実行になるので、sudoが不要になる点に注意してほしい)。
$ docker attach mycontainer
root@<コンテナーID>:/#
root@<コンテナーID>:/# apt update # aptパッケージのアップデート。sudoは不要
root@<コンテナーID>:/# apt -y upgrade # 既存パッケージのアップグレード
root@<コンテナーID>:/# apt install -y wget # wgetコマンドのインストール
$ # 必要に応じて、前述のデスクトップ環境のインストールなどを行ってもよい。
※コマンド実行後に何も表示されない場合は、もう一度、[Enter]キーを押してみてほしい。
一連の作業が終わってコンテナー側のbashシェルセッションを抜けるには、[Ctrl]キーを押しながら[P]キーに続けて[Q]キーを押せばよい。
なお、コンテナーを終了したい場合や再起動したい場合は、リスト2.11のようにすればよい。
$ # コンテナーを終了する
$ docker stop mycontainer
$ # コンテナーを起動する
$ docker start mycontainer
以上、必要最小限のコマンドだけ紹介したが、機会があれば別記事でnvidia-dockerを使う方法をより詳しく説明したい。
基本的にnvidia-dockerは必要になってから使えばよいので、取りあえずコンテナーは終了して、ホスト側に下記の2.5以降のインストール手順を実行してほしい。
2.5. CUDA Toolkit(開発環境)
本稿ではTensorFlowの要件に合わせてCUDA Toolkit 9.0をインストールする。
まずはCUDA Toolkit 9.0のベースインストーラー(本稿の例ではcuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.deb)をダウンロードする。これには、CUDA Toolkit Archiveから前掲の図6の続きで、[Distribution]欄の次の[Installer Type]欄はdeb (local)を選択する。これにより、図8のように[Download Installers for Linux Ubuntu 16.04 x86_64]枠が表示される。この枠に、CUDA Toolkitのインストール方法が記載されているので、これに従ってインストールすればよい。

参考までに、本稿では[Base Installer]欄にある[Download]リンクを右クリックしてリンクのアドレスをコピーして、リスト2.12のようにコマンドを実行した(※当然ながら、wgetに指定するダウンロードリンクは、各自でコピーしたものに差し替える必要がある)。
$ wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64-deb \
-O cuda-toolkit.deb
このコマンド例ではcuda-toolkit.debという名前のファイル(=Debian用のインストーラーパッケージで、通常は.debという拡張子が付く)がダウンロードされる。念のため、ファイルが壊れていないかをチェックサムで確認しておくとよい。そのためのコマンドはリスト2.13のようになる。
$ md5sum cuda-toolkit.deb
e78e6ff56582f09a0cbc607049bdb2fd cuda-toolkit.deb
e78e6ff56582f09a0cbc607049bdb2fdがチェックサムの値になるが、図6に示したインストール方法の説明の中にある[Installer Checksums]リンクからファイルに対する正常なチェックサム値を参照して、両者が一致するか確認すればよい。
それでは、ダウンロードしたdebパッケージからCUDA Toolkitをインストールしよう。リスト2.14のようにコマンドを実行する。
$ sudo dpkg -i cuda-toolkit.deb
$ sudo apt update
$ sudo apt -y install cuda
今回の例では[Base Installer]欄の下nに[Patch 1 (Released Jan 25, 2018)]と[Patch 2 (Released Mar 5, 2018)]という記載があり、パッチもインストールできる。これらのインストール方法もここまでの説明と同様なので、リスト2.15にコマンド例だけ示す。
$ wget https://developer.nvidia.com/compute/cuda/9.0/Prod/patches/1/cuda-repo-ubuntu1604-9-0-local-cublas-performance-update_1.0-1_amd64-deb \
-O cuda-patch1.deb
$ md5sum cuda-patch1.deb
aa849a2b5ae80278ed1298e4e799df65 cuda-patch2
$ wget https://developer.nvidia.com/compute/cuda/9.0/Prod/patches/2/cuda-repo-ubuntu1604-9-0-local-cublas-performance-update-2_1.0-1_amd64-deb \
-O cuda-patch2.deb
$ md5sum cuda-patch2.deb
104a1f4eda51cfc34c56d17da8059bc6 cuda-patch2
$ sudo dpkg -i cuda-patch1.deb
$ sudo dpkg -i cuda-patch2.deb
$ sudo apt update
$ sudo apt -y upgrade
$ sudo reboot
以上でCUDA Toolkit(開発環境)のインストールは完了だ。
2.6. cuDNN(ディープラーニング用ライブラリ)
cuDNNは、CUDAを活用するDeep Neural Network(DNN)開発ライブラリである。具体的な内容は公式サイトを、インストール手順は公式ガイドを参照してほしい。
ここでは参考までにどのようなコマンドを実行したのかを、リスト2.16に提示しておこう。
なお、cuDNNインストーラーの.debファイルをダウンロードするためには認証が必要になるので注意してほしい。このため、wgetコマンドではなく、公式のcuDNN Downloadページをデスクトップ環境のブラウザーで開いてから(※メンバーシップにJoinしてからLoginする必要あり)、下記の3つのファイル(※「v7.1.3」は執筆時点のもの)をダウンロードしてほしい(【〜】内に記述したのは、リネームした後のファイル名)。
- 「cuDNN v7.1.3 Runtime Library for Ubuntu16.04 (Deb)」【cudnn7.deb】
- 「cuDNN v7.1.3 Developer Library for Ubuntu16.04 (Deb)」【cudnn7-dev.deb】
- 「cuDNN v7.1.3 Code Samples and User Guide for Ubuntu16.04 (Deb)」【cudnn7-doc.deb】
$ # 3つのdebパッケージをインストール
$ sudo dpkg -i cudnn7.deb
$ sudo dpkg -i cudnn7-dev.deb
$ sudo dpkg -i cudnn7-doc.deb
$ # ホームディレクトリにサンプルコードをコピー
$ mkdir ~/samples
$ cp -r /usr/src/cudnn_samples_v7/ ~/samples/cudnn_samples_v7/
$ # cuDNNライブラリが利用できるかテスト
$ cd ~/samples/cudnn_samples_v7/mnistCUDNN
$ make clean && make
$ ./mnistCUDNN
Test passed!
2.7. CUDA Profiling Tools Interface(libcupti-devライブラリ)のインストール
CUDA Profile Tools Interfaceは、GPU内の挙動を確認(プロファイリング)するのに役立つ。前述のとおり、TensorFlowなどではインストール要件となっているので、ここでインストールしておこう(リスト2.17)。
$ sudo apt -y install libcupti-dev
以上でGPU利用環境が整った。次はディープラーニングの開発環境を構築していく。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。