どのようにデータ基盤を作ったのか?「俺の考えた最強のデータ基盤」は使われない:開発現場に“データ文化”を浸透させる「データ基盤」大解剖(3)(2/2 ページ)
重厚長大なExcelを読み解く
データの項目追加といった【2】Model改修案件については、ビジネス部門が管理していたExcelシートを「正解」と仮置きしました。見るべきデータや指標の定義を変えると、既存業務への予期しない影響が生じる可能性があるからです。
また、新しく一から指標を定義して関係者全員に合意を得るのは容易ではありません。既存データに基づいて案件を進め、フィードバックを元に修正する方が、イテレーションを素早く回せるだろうと判断しました。
実際の業務内容としてはExcel上で集計していた処理を、PythonとBigQueryに反映していきました。後に社内では「データ基盤のEOL(End of Life)対応、再構築」と呼称されるようになります。最初はExcelシートが事実上のデータ基盤かもしれませんが、Excelは本来データストアではありません。組織が成長して利用者やデータ量が増えると、いずれツールの限界が訪れます。それがデータ基盤のEOLとなり、再構築が必要となるのです。
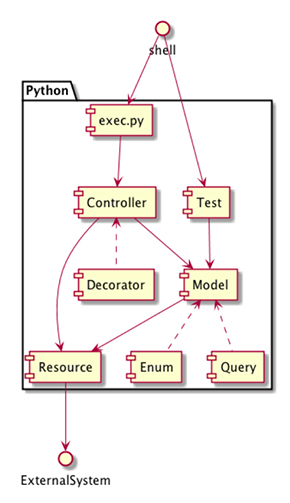
Excelの集計ロジックを再現する際にはテストファーストを意識しました。Pythonの標準的なテストライブラリである「unittest」による自動テストを活用しています。
Excelの集計結果をテストコードの期待値として設定します。集計ロジックを作成、修正して、期待値と一致するようになったら再現完了です。SQLのチューニングやリファクタリングによって修正ロジックに意図しない変更が生じた場合、集計結果が変わってしまうので、自動テストでエラーが返るようになります。加えて、デグレードの即時検知ができるので、保守、運用の観点でも有益です。
集計ロジックを再現するためには、重厚長大なExcelを解読する必要があります。シートやファイルをまたいだ多重参照や、Excelに貼り付ける元データを出力するシステム内での加工処理など、一つ一つ丁寧に読み解いていかなければなりません。
すると、「部署Aが扱うシートでは消費税を加味するために1.08を掛けているのに、そのシートを参照している部署Bのシートでは消費税が不要なので1.08で割っている」といった、無駄な処理が連なって肥大化していることが分かりました。
このような参照関係や加工処理については、マインドマップツールを使って解読していき、あるべき集計ロジックへと差し替えていきました。
ニーズ開拓の好循環を回す
既存ロジックの解読を進めるうちに計算ミスやデータ不整合を発見することが多々ありました。その際にはJupyter Notebookをフル活用することで、調査、記録、レポートを一括で達成しました。
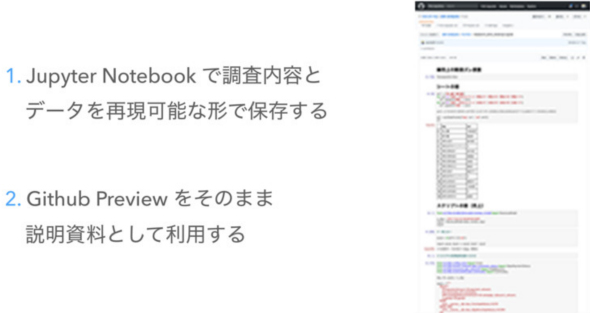
Jupyter Notebookで調査内容とデータを再現可能な形で保存します。
調査内容としては事象、原因、影響、改修方針、関係者への依頼事項が含まれます。再現可能な形で保存するのは、利用しているデータソースの中身が後から変わってしまう可能性があるからです。例えば、プロダクト本体のバグによってDBのデータに不整合が生じていた場合、修正パッチを当てることになるでしょう。
調査実施タイミングのデータを記録、共有するために、Jupyter NotebookのファイルはGitでバージョン管理しました。GitHubにホスティングすると、GitHubのPreview機能でレポートを表示できるので、そのまま関係者への説明資料として利用できます。

「既存データの計算ミスや不整合を発見したら報告して直す」ことを繰り返していくと、小さな実績が積み重なっていきます。やがて「データのことはこいつに聞け」と信頼してもらうことで、各部署から質問や相談が寄せられるようになります。寄せられた質問や相談を通して、どのようなユースケースでデータを使っているのかを知ることができます。データの用途を知ることで、既存の集計ミスや運用課題、さらなる介在余地に気付き、いっそうの実績を積み重ねることができます。
このようにしてニーズ開拓の好循環を回し始めることができました。好循環を回し続けるには、忍耐が必要です。実際に費やした時間の8割以上は、ひたすら地道な作業でした。既存のデータと数字が合わないのです。蓋を開けてみると課題だらけでした。
- システム連携の途中で四捨五入が積み重なった結果全く違う数字になってしまう
- 小数点の影響でExcelの計算結果が「5 x 2000 = 9999」となっている(※数字はダミーです)
- 集計タイミングで結果が変わる(=冪等性がない)ため、既存の数値は誰にも再現できない
このような課題を一つ一つつぶしながら、データクレンジングを推し進めていきました。
開発プロセスを磨き込むことの意義
これらの開発プロセスは現在も日々磨きこんでいます。今回紹介した内容はデザイン思考、ジョブ理論、アジャイル開発手法を参考にしました。
データ基盤を磨き込むためのプラクティスはまだまだあります。例えば最近ですと、UXデザインの専門部隊と連携して、データ基盤を対象としたユーザーテストやインタビューを実施しています。
お伝えしたいことは「使われるデータ基盤」を作るには多様な観点を検討しないといけないということです。「ダッシュボードを作れば皆が見るだろう」「データ部署を立ち上げれば皆が頼ってくれるだろう」「システムを構築すれば解決するだろう」――残念ながら、そう簡単ではありません。
その一方で、何もかも一気にできるわけではありません。だからこそ、イテレーションを回して少しずつ進化させたり、既存の業務を改善するところから始めたり、案件の優先順位を定義したり、地道なクレンジングで精度と信頼を積み重ねたり、テストコードやJupyter Notebookなどのツールを使いこなして作業を効率化させたりすることが大事なのです。
これらの手法は何1つ革新的ではありません。開発プロセスにおけるボトルネックに対して、既存のソフトウェア開発手法を適用することで、「使われるデータ基盤」構築におけるムダ、ムリ、ムラを愚直に取り除いただけの話です。筆者が構築した「使われるデータ基盤」に革新性があるとしたら、それは「何一つ革新的ではない知見と実践をひたすら積み重ね続けた」ことだと思っています。
以上のような取り組みを経て、各部署へのデータ提供を実現していきました。連載最終回となる次回は「使われるデータ基盤」を通して、組織にデータ活用文化を装着するための取り組みを紹介します。
参考リンク
筆者紹介
横山翔
リクルートテクノロジーズ プロダクトエンジニアリング部所属
途上国から限界集落まで各地放浪、ベンチャーキャピタルから投資を受けての起業や会社経営、リクルートグループ会社における複数の新規事業の立ち上げを経て、現職。
現在は急成長プロダクトを対象に、システムアーキテクチャの再構築やエンジニアチームの立ち上げ、立て直しに従事。
関連記事
 ネット広告のデータ分析プロジェクトはどのように行われるのか
ネット広告のデータ分析プロジェクトはどのように行われるのか
広告宣伝費を各宣伝媒体へのコスト配分を調整することで効率化したいという事業部の課題に対してデータ分析のプロジェクトはどう進められるものなのか。筆者の経験を基に紹介する。 CVRをあと10%アップする、ビッグデータ分析とアダプティブUXの使い方
CVRをあと10%アップする、ビッグデータ分析とアダプティブUXの使い方
ABテストを利用したサイト改善の限界にぶつかっている人たちに向けて、リクルートグループ内で実践している改善ノウハウをお伝えする連載。今回は、中古車販売サイト「カーセンサー」を例に「検討フェーズ」を軸とした個別最適化やビッグデータ分析の有効な生かし方について解説する。 Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み
Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。今回は、ログデータの分析および可視化の基盤を構成する5つの主なOSSや集計データを活用したキーワードサジェストの事例を紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。