[Python入門]文字列の操作:Python入門(3/4 ページ)
文字列の分割:splitメソッド
1つの文字列を分割して、「リスト」と呼ばれるデータ構造の要素にできる(リストとは、複数個のデータを一括して保存、管理、操作するためのオブジェクト。第16回「リストの基本」などを参照されたい)。これには、文字列のsplitメソッドを使用する。
- 元の文字列.split(sep)
引数:sep 文字列を分割する区切りとなる文字(separator)
戻り値:区切り文字で文字列を分割したものを格納したリスト
splitメソッドは「'文字列'.split('区切り文字')」という形式で呼び出すのが基本形だ。例えば、「'abc def ghi'」という文字列を空白文字を区切り文字として分割してみよう。分割後に区切り文字はなくなる。
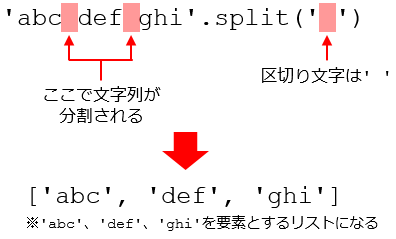 splitメソッドの動作
splitメソッドの動作これを行うには次のようなコードを書く(ただし、実際にはsplitメソッドの引数に区切り文字を記述しなかったときには空白文字が区切り文字として使われるので、以下は「'abc def ghi'.split()」と同じ意味になる)。
'abc def ghi'.split(' ')
実行すると、その結果は次のようになる。
 空白文字を区切りとして文字列が'abc'、'def'、'ghi'に分割され、それらを格納するリストが作られた
空白文字を区切りとして文字列が'abc'、'def'、'ghi'に分割され、それらを格納するリストが作られた実行結果にある角かっこ「[]」を使って表現されているのが「リスト」だ。[]の中には、カンマを区切り文字として分割された'abc'、'def'、'ghi'の3つの文字列があるのが分かるはずだ。これらを「リストの要素」と呼ぶ(それぞれの要素はカンマで区切って表示されている)。
分割を行う回数を指定することも可能だ。それには「'abc def ghi'.split(' ', 1)」などのように分割する回数を指定すればよい。以下に例を示す。
 分割回数に「1」を指定した場合
分割回数に「1」を指定した場合先ほどと同じ例で、分割回数を「1」に指定したので、2つ目の空白文字での分割が行われていないことが分かるはずだ。
CSVファイル(カンマや空白文字を区切りとしてデータを並べたテキストファイル)から定形的なデータを読み込んだ後に、splitメソッドを使うことで、複数のデータを含む文字列を個別のデータに分割するといった使い方ができる。また、分割を文字列の右側から行っていくrsplitメソッドもあるが、これについては説明を省略する。
リストの要素を文字列へ結合:joinメソッド
joinメソッドは、splitメソッドとは反対方向の処理を行うものだ。つまり、リストの各要素を1つの文字列に結合するのにこれが使える。
- '区切り文字'.join(リストなど)
引数:iterable その要素をまとめて文字列化したいもの(リストなど)
戻り値:各要素を「'区切り文字'」で区切って並べた文字列
例えば、上の例で分割したリストを文字列に再度結合してみよう。ここでは区切り文字をカンマ「,」にしてみる。
alpha_list = 'abc def ghi'.split()
print(alpha_list)
alpha_str = ','.join(alpha_list)
print(alpha_str)
実行結果は次のようになる。

区切り文字に指定したカンマ「,」を挟んでリストの各要素が結合されているのが分かるはずだ。なお、区切り文字には空文字列を指定することもできる。この場合には、リストの要素が区切り文字なしで一気に結合される。以下に例を示す。

なお、結合できるのは、文字列を要素とするものだけなので、そこには注意しよう。
空白文字の削除:strip/lstrip/rstripメソッド
文字列の先頭や行末には、不要な空白文字が含まれることもある。例えば、上で見たsplitメソッドでカンマ区切りのデータを分割することを考えてみよう。
data = 'abc, def, ghi'
data_list = data.split(',')
print(data_list)
やっていることは、splitメソッドの説明で見たのと同じだ。これを実行すると、カンマの後の空白文字を含んだ文字列を要素とするリストができる。

問題は、見やすさを考えて元データ(変数dataに代入した文字列)にはカンマの後に区切り文字が含まれている点だ。実際、CSVファイルからデータを読み込む場合などには、カンマの後に空白文字が含まれているのはよくあることだ。これらは不要なものなので、実際に処理をするにはそれらをあらかじめ削除しておく必要がある。そこで使えるのが、strip/lstrip/rstripの各メソッドだ。
- 元の文字列.strip()
戻り値:文字列の先頭/末尾にある空白文字を削除したもの - 元の文字列.lstrip()
戻り値:文字列の先頭にある空白文字を削除したもの - 元の文字列.rstrip()
戻り値:文字列の末尾にある空白文字を削除したもの
以下に例を示す。変数sample_strには先頭に空白文字が3つ、末尾に空白文字が2つ含まれている。これらを上記の3つのメソッドで削除してみる。
sample_str = ' sample '
print('begin:' + sample_str.strip() + ':end')
print('begin:' + sample_str.lstrip() + ':end')
print('begin:' + sample_str.rstrip() + ':end')
print(sample_str)
実行結果を以下に示す。

出力を見れば、各メソッドの動作が分かるはずだ。また、コードの最後にある「print(sample_str)」行の出力結果を見ると、元の文字列(' sample ')がそのまま残っている(変更されていない)ことにも注意しよう。先ほども「文字列は変更できない」と述べたが、ここで紹介した3つのメソッドは「元の文字列に対する変更操作を反映した新しい文字列」を作成して返すものだ。この後で紹介するreplaceメソッドなどの文字列の内容を変更するメソッドは、基本的にこれら3つのメソッドと同様に、「変更操作を反映した新しい文字列」を返す。
なお、これらのメソッドでは、引数を与えることで、削除対象を空白文字から任意の文字に変更できる。引数には、削除したい文字(1文字以上)を記した文字列を指定する。
sample_str = '**++**sample**++**'
print(sample_str.strip('*'))
print(sample_str.strip('+*se'))
1つ目のstripメソッド呼び出しでは、引数に「*」だけを指定し、その次のstripメソッド呼び出しでは「+」「*」「s」「e」を削除するように伝えている。実行結果を以下に示す。

指定した文字が、それぞれの呼び出しで削除されていることを確認してほしい。注意すべきは、1つ目の呼び出しは文字列の先頭と末尾にある「*」を削除することを意味しているので、「++」で囲まれた部分は削除されないことだ。2つ目の呼び出しでは「+」「*」「s」「e」を削除対象としているので、それらが連なった「**++**s」(文字列先頭)と「e**++**」(文字列末尾)が削除されている。
文字種の判定
文字列が特定の種類の文字でのみ構成されていることを確認したいこともある。例えば、input関数はユーザー入力を受け取るために使えるが、その結果は常に文字列となる。それを数値に変換したいとしよう*1。以下のコードではint関数を使って、文字列を整数値に変換している。
*1 第2回「Hello Python」の「もう少し難しいHello Worldプログラム」で触れているように、「Try Jupyter」ページの「Jupyter Notebook」リンクから起動するPython環境では以下のコードがうまく動作しない。対処策としては上記ページにあるように、Binderを使う方法がある。以下では、Binderを使って起動した環境で話を続けることにしよう。
num = 'not a number!'
user_input = input('input number: ')
num = int(user_input)
print(num)
ユーザーが数字だけを入力すれば、このコードはもちろん問題なく動作する。だが、英小文字など数字ではない文字を入力すると、エラーが発生する。

そこで、役立つのがisdigitメソッドだ。
- 元の文字列.isdigit()
戻り値:元の文字列が1文字以上あり、全て数字で構成されていればTrue、そうでなければFalse
これは文字列が数字のみで構成されているかを調べて、そうであればTrueを、そうでなければFalseを返す。以下はif文(第9回「if文による条件分岐」を参照)での条件判定にisdigitメソッドを使い、数字だけが入力されたら、それを整数値に変換したものを、そうでなければ「not a number」と表示するコードだ。
num = 'not a number'
user_input = input('input number: ')
if user_input.isdigit():
num = int(user_input)
print(num)
if文が「if user_input.isdigit():」となっていて、日本語にすると「もし、user_inputが数字なら」と素直に読み下せるようになっていることにも注目しよう(このように、True/Falseを演算結果として、何らかの条件判断に使えるメソッドは「is」で始まることが多い。そのようにすることで、上で見たように素直にコードを素直に読み下せるからだ)。
これを実行して、数字以外を入力した結果を以下に示す。

このような文字種の判別に使えるメソッドとしては、以下のようなものがある(抜粋)。使用例で矢印「→」の隣にあるTrue/Falseは使用例の戻り値である。
| メソッド | 説明 | 使用例 |
|---|---|---|
| isdigit | 文字列が数字だけで構成されているかを調べる | "1234".isdigit()→True |
| isupper | 文字列が大文字だけで構成されているかを調べる | "abc".isupper()→False |
| islower | 文字列が小文字だけで構成されているかを調べる | "abc".islower()→True |
| isalnum | 文字列が英数字だけで構成されているかを調べる | "2020 Aug.".isalnum()→False |
| isalpha | 文字列が英字だけで構成されているかを調べる | "August".isalpha()→True |
| isascii | 文字列がASCIIコードに含まれる範囲の文字だけで構成されているかを調べる(Python 3.7以降のみ) | "ほげほげ".isascii()→False |
| 文字種の判別に使えるメソッド(一部) | ||
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。