プロが教える、クラウドインフラのトラブルシューティング「4つの原則」とは:「クラウドだからお手上げ」とは言っていられない(1/2 ページ)
クラウドインフラはオンプレミス環境と比べて複雑になりがちで、トラブルの原因特定に時間がかかることが多い。では、どういった点に注意してトラブルに対応していけばいいのか。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
企業システムを支えるインフラをクラウドに切り替える企業は少なくない。OpenStackやKubernetesなどさまざまなソフトウェアが登場し、クラウドサービス登場当初に比べれば簡単にクラウドを活用できるようになったからだ。一方で、インフラの細かい構成が隠蔽(いんぺい)された結果「トラブルが発生したときに自分たちでは対処ができない」という課題が生まれている。
2020年7月29〜30日に実施されたクラウドインフラの運用管理者向けイベント「Cloud Operator Days Tokyo 2020」のセッションにて、レッドハットの梶波崇氏(シニアソフトウェアメンテナンスエンジニア)は「クラウドインフラはオンプレミス環境と比べて構成が複雑になりがちで、トラブルの原因特定が難しくなる」と語る。
こうしたクラウドインフラで発生したトラブルに対し、どのような視点で調査、対応をすればいいのか。レッドハットの梶波氏と井川征幸氏(ソフトウェアメンテナンスエンジニア)のセッション「クラウドインフラ トラブルシュートのすゝめ」からトラブルシューティングを効率化する原則とTipsについて解説する。
本稿で紹介する障害例は以下の4点だ。
- OpenStackの仮想サーバへSSHでログインしようとしたが、失敗した
- OpenStackの仮想マシンが起動しない
- データベース(DB)接続でエラーが発生する
- ボリューム作成に失敗する
インフラが複雑化する3つの理由
「クラウドインフラのトラブルシューティングを考える上で、最も重要なのは複雑性を理解することだ」(梶波氏)
 レッドハットの梶波氏
レッドハットの梶波氏サーバやネットワーク、ストレージといったインフラをクラウド化するに従って、複雑さはどんどん増しているという。梶波氏は3つの理由を挙げた。
1つ目は、サーバやストレージといった「データプレーン」と、それらを構築したり管理したりする「コントロールプレーン」が分離されていること。このため、インフラを2つの方向から捉える必要がある。
2つ目は、仮想化技術が多用されていること。「1台の物理サーバ上に100台の仮想サーバが稼働しており、複雑なネットワークが構成されているというケースはざらだ」(梶波氏)。こうした環境では問題の仮想サーバがどこでどのように動いているかという実態が捉えにくい。
3つ目は「分散」。システムが複数のノードで構成され、それぞれのノードで複数のプロセスが稼働し、冗長化されているといったケースは問題の発生個所を特定することが困難になる。だが「こうしたケースは珍しくない」(梶波氏)という。
「クラウドインフラは、従来のインフラと比べて2段階は複雑になっている。発生した問題を早く解決したり、新しい問題を防いだりするためには、いかにトラブルシューティングを効率良く実行するかという点が非常に重要だ」(梶波氏)
効率的なトラブルシュートを実現する4つの原則
トラブルシューティングを効率化するための考え方として、梶波氏は「4つの原則」を提示する。
1.マクロから捉える
2.コンポーネントの役割を捉える
3.影響範囲を明らかにする
4.リソース監視を怠らない
具体的な障害例を基にそれぞれ解説する。
調査はマクロから始める
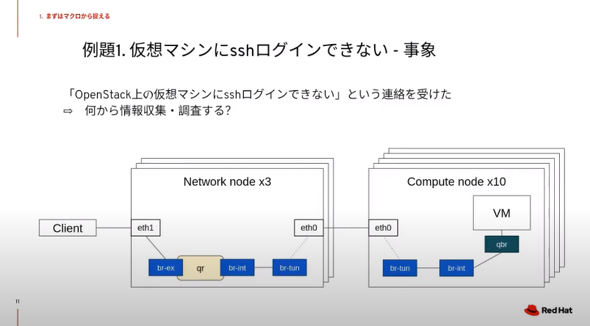 例題1.「OpenStackの仮想サーバへSSHでログインしようとしたが、失敗した」
例題1.「OpenStackの仮想サーバへSSHでログインしようとしたが、失敗した」「OpenStackの仮想サーバへSSHでログインできない」というケースを考えてみよう。このトラブルが発生する可能性は多岐にわたり、どこから情報収集し、何を調査すべきかが分かりにくい。複雑な構成要素を一つ一つ見ていくのは非効率的だから、分析すべき対象を絞り込むことが重要だ。
「問題をマクロ(概要)から捉えることが重要だ。ミクロ(詳細)から見ていくと、間違えたときに手戻りが多くなってしまう。例えば、問題となっている操作やエラーメッセージ。APIに含まれるリソースの定義状況や情報、Ping疎通など動作レベルでの簡単な切り分けなどをチェックして整理する。原因特定までの調査ロジックを説明できるかどうかという点を常に意識する必要がある」(梶波氏)
コンポーネントの役割を学ぶ
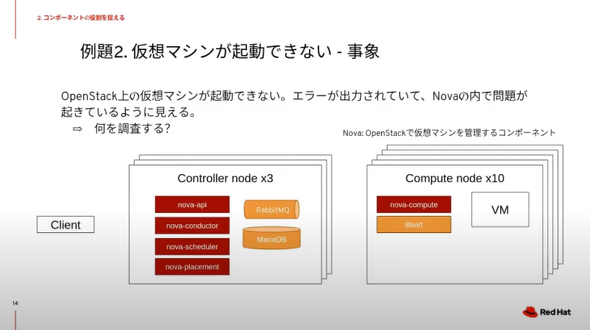 例題2.「OpenStackの仮想マシンが起動しない」
例題2.「OpenStackの仮想マシンが起動しない」次に「OpenStackの仮想マシンが起動しない。『Nova』(仮想マシンの管理コンポーネント)で問題が発生しているようだ」という状況が発生したとする。
単に「Novaの問題」と言っても、OpenStackのNova関連コンポーネントはコンピュートノードにもコントローラーノードにも存在しており、どこに原因があるのかすぐには分からない。調査対象を絞るポイントの1つは、問題のコンポーネントの役割を知っておくことだ。例えばNovaの場合、「nova-api」がAPIを受け付けるプロセス、「nova-compute」が仮想マシンを操作するプロセスだ。そのため、仮想マシンが起動しないという問題に対して、最も関連性が深いプロセスだと考えられる。
「システムが複雑になると、コンポーネントが増えて、理解すべきことも増えるという問題がある。全てを正確に把握することは困難なため、理解を蓄積して少しずつ効率化へつなげていく必要がある。まずは概要を理解して、日々のトラブルシュートの中で学び、ノウハウをシェアするのがいいだろう」(梶波氏)
対象を絞り込んだ後のステップとして、情報収集のためのコマンドやログファイルのパスなど、各コンポーネントの調査方法について学んでおけば、より早い対応が可能になる。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。