【初心者向け】「Amazon Rekognition Custom Labels」の音符画像解析で分かる、機械学習とラベリングの基本:AWSチートシート
AWS活用における便利な小技を簡潔に紹介する連載「AWSチートシート」。今回はAWSの機械学習サービスで機械学習とラベリングの基本を学ぶ。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
「Amazon Web Services」(AWS)AWS活用における便利な小技を簡潔に紹介する連載「AWSチートシート」。今回はAWSの機械学習サービスの一つ「Amazon Rekognition Custom Labels」の概要、ラベリング方法、API実行方法、解析結果を紹介します。
Amazon Rekognition Custom Labelsとは
AWSが提供する機械学習サービスの一つで、任意の画像の物体を枠で囲み、枠に名前を付けることで、機械学習を行うサービスです。
物体を枠で囲み、名前を付けるという一連の流れのことを「ラベリング」といいます。複数回ラベリングして機械学習を行うことで、画像が何を意味するのか解析することが可能になります。
解析対象
今回は四分音符を対象にしました。前提としては、ト音記号上の音符で、単音のみを扱います。解析結果の音の名前は「ド」「レ」「ミ」「ファ」「ソ」「ラ」「シ」「ド」で表現します。また、調はハ長調(イ短調)で、#や♭などの変化記号は解析対象外です。
解析手順
- プロジェクトの作成
- データセットの作成
- ラベリング
- 学習
- APIを利用して解析
【手順1】プロジェクトの作成
今回は「read_music」という名前でプロジェクトを作成します。「Amazon Rekognition」のトップ画面の左側のバーから「カスタムラベルを使用」を選択します。

Amazon Rekognition Custom Labelsの画面に遷移後、画面左側のバーから「Projects」を選択します。

初めてAmazon Rekognition Custom Labelsを利用するリージョンでは、「Amazon S3」バケットの作成を促されるので、「Create S3 bucket」ボタンをクリックして、バケットを作成します。

プロジェクト一覧画面に遷移後、画面内のオレンジ色のボタン「Create project」をクリックします(画面内に2つボタンがありますが、どちらを選択しても結果は変わりません)。

「Project name」に任意の名前を入力し、「Create project」ボタンをクリックします。

これでプロジェクトの作成は完了です。
【手順2】データセットの作成
データセットとは、機械学習を行う際に使用するデータのことです。今回なら、音符の画像群がデータセットに当たります。プロジェクト作成後の画面で「Create dataset」ボタンをクリックします。

データセットの分割方法について、「Start with a single dataset」と「Start with a training and a test dataset」を選ぶことができます。
「Start with a single dataset」を選択することで、学習する際のtraining datasetとtest datasetを8対2の割合で自動的に振り分けてくれます。
training datasetとtest datasetについて、ここでは説明を割愛しますが、特定の画像をtraining datasetやtest datasetに任意で振り分けたい場合は「Start with a training and a test dataset」を選択しましょう。
今回は「Start with a single dataset」を選択します。

画面下部では、データセットをどのように用意するかを選択できます。4種類の方法がありますが、今回はS3から画像を取得する「Import images from S3 bucket」を選択します。

「S3 URI」欄に、手順1で作成したS3バケットのURIを記入します。指定した場所に画像がない場合はエラーとなってしまうので、事前にデータをバケットにアップロードした上で設定しましょう。「S3 URI」入力後に「Create Dataset」ボタンをクリックします。

【手順3】ラベリング
Amazon Rekognition Custom Labelsの醍醐味(だいごみ)、ラベリングを実施します。データセット作成後の画面で「Start labeling」ボタンをクリックします。

最初にラベリングする際に付けるラベルの名前を設定するために、「Manage labels」ボタンをクリックします。
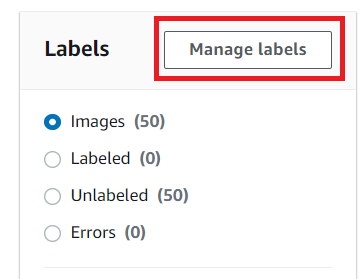
今回は「ド」「レ」「ミ」「ファ」「ソ」「ラ」「シ」の7個を登録します。下図のように追加したいラベル名を入力し、「Add label」をクリックします。この作業を追加したいラベルの数だけ繰り返し、最後に右下の「Save」ボタンをクリックします。

次に、ラベリングする画像を選択した状態で、「Draw bounding boxes」をクリックします。

手動でラベリングします。下記のように、音符を正しいラベル名で囲み、右上の「Done」ボタンをクリックします。

データセットの画面に戻ったら「Save changes」ボタンをクリックします。この作業は毎回する必要はなく、ある程度ラベリングを終えてからまとめて「Save Changes」をクリックしても構いません。

今回は、データのバリエーションを増やすために、印刷した楽譜をカメラで撮影したものもラベリングしました。

最終的に下記のようなラベリング量となりました。データ量にはバラつきがありますが、ここでは「各ラベル十分なデータ量が整った」と判断してラベリングを終了しました。
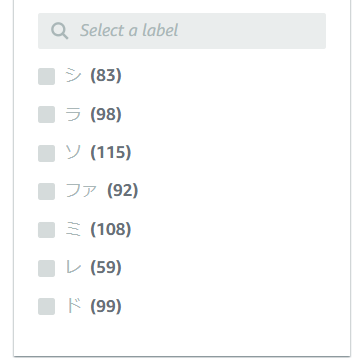
【手順4】学習
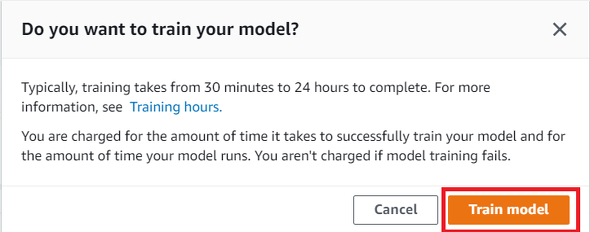
ラベリングが完了したら、学習を実行します。データセットの画面で「Train model」ボタンをクリックします。

デフォルト値のまま「Train Model」をクリックします。

ポップアップ上の「Train model」をクリックすると、学習が始まります。今回のデータセットでは、学習が完了するまで2時間以上かかりました。また、学習に成功すると、学習時間に応じて課金が発生します。2022年10月現在、東京リージョンでは1時間当たり1.37ドルの課金が発生します。
AWS側で追加のコンピューティングリソースを使用して学習を進めた場合、さらに追加料金が発生します。ここはユーザーが制御できる部分ではありません。ある程度コストが発生することを念頭に置いた上で実行するようにしましょう。
学習が完了すると、プロジェクトの一覧画面の「Model status」が「TRAINING_COMPLETED」になります。

【手順5】APIを利用して解析
作成したモデルを利用して、画像を解析します。プロジェクト一覧画面で使用したいモデルの「Name」をクリックし、「Use model」タブを選択します。「Start or stop model」の「Start」ボタンをクリックします。

表示されたポップアップ内の「Start」をクリックすると、モデルが起動します。今回のモデルの場合、立ち上がるまで10分ほどかかりました。モデルが開始すると、課金が発生します。
2022年10月現在、東京リージョンでは1時間当たり4ドルの課金が発生します。こちらもAWS側で追加のリソースを使用して学習を進めた場合、さらに追加料金が発生します。モデルを使用しない場合は、必ずモデルを停止するようにしましょう。

モデルが正常に開始すると「Running」と表示されます。

モデルが開始したら「API Code」の折り畳みを解除して「Analyze image」に記載されているコマンドを実行します。

今回は「AWS CloudShell」を利用してコマンドを実行します。コマンド内の「MY_BUCKET」には解析対象の画像を格納しているバケット名を入力し、「PATH_TO_MY_IMAGE」には解析対象の画像のバケット以降のパスとファイル名を入力します。解析結果は後述します。
解析が終了したら、モデルを停止させます。「Start or stop model」の「Stop」ボタンを選択します。

入力欄に「stop」と入力し、再度「Stop」ボタンを押下することで、モデルを停止できます。モデルが停止することで課金が停止します。

解析結果
今回はド〜シまでの四分音符のみの画像を用意し、それぞれを解析しました。候補が複数示されるものもありましたが、1番上に表示された候補のみ公開します。「Confidence」の数値が高いほど、解析結果に自信を持って出力していることになります。解析した画像と解析結果は下記の通りです。














全ての音符に対してConfidenceが99.99%以上の数値で検知できた上に、正しい値を出力できました。今回は検証していませんが、和音や臨時記号なども、ラベリング方法を変えて学習を重ねることで対応できる可能性も高いように感じます。うまく使えば、楽譜の画像データやPDFをAPIで処理し、自動で楽譜上に階名を振ってくれるようなシステムも作れそうです。
本記事がAmazon Rekognition Custom Labelsの利用を検討している方や、ラベリングに苦戦している方の参考になれば幸いです。
筆者紹介
杉本健太
株式会社システムシェアード
ITの力で社会を豊かにするために日々勉強中。
クラウドの知識を深めるためにAWSのアソシエイト資格を全て取得。現在はAWSを利用したサービスの開発に従事しながら開発現場の知識、経験を研さん中。
将来的にはAIを活用しながら、多くの人に喜んでもらえるサービスを作りたいという夢を胸に抱いている。
関連記事
 「うちの子の写真、少なくない?」を防止 千が卒園アルバム制作サービスに「AIによる人物集計機能」を追加
「うちの子の写真、少なくない?」を防止 千が卒園アルバム制作サービスに「AIによる人物集計機能」を追加
千は、卒園アルバム制作サービス「はいチーズ!アルバム」に「人物集計表」機能を追加した。AWSの「Amazon Rekognition」を活用して、アルバムの各ページに何回園児が登場したのかを集計する。 ディープラーニングなどに活用可能なカメラ「VRK-C301」を発表 パナソニック
ディープラーニングなどに活用可能なカメラ「VRK-C301」を発表 パナソニック
パナソニックはディープラーニングなど高度な画像解析を活用したサービス展開が可能となるカメラ「VRK-C301」の提供を開始する。CPUを搭載し、多様なアプリケーションに対応できるという。 AI画像解析で「顔が映っていない画像」から人物特定、追跡が可能に 日立製作所
AI画像解析で「顔が映っていない画像」から人物特定、追跡が可能に 日立製作所
日立製作所と日立産業制御ソリューションズは、防犯カメラなどの映像から全身特徴によって特定の人物を高速検索する「高速人物発見・追跡ソリューション」を販売する。後ろ姿など、顔が映っていない映像からでも全身特徴を判別する。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。