AI・機械学習のデータセット辞典
全データセットを一覧表示しています。データセット名をクリックすると、データセットの解説を参照できます。今後も粛々とデータセットを拡充していきます。
AI・機械学習のデータセット辞典:
データセット「GLUE」について説明。英語で自然言語処理モデルの性能を評価するための標準ベンチマーク。英語文法の正しさ判定などの9つのタスク(CoLA/SST-2/MRPC/STS-B/QQP/MNLI/QNLI/RTE/WNLI)に対応するデータセットのコレクション。

AI・機械学習のデータセット辞典:
データセット「LAION-5B」について説明。約58億5000万個のカラー画像データとテキストのペアのデータセットが無料でダウンロードでき、テキストから画像を生成する大規模なマルチモーダルAIの研究開発などに利用できる。

AI・機械学習のデータセット辞典:
データセット「Wine」について説明。178件のワインの「表形式データ(アルコール度数/色の濃さなどの13項目)」+「ラベル(3種類のワインの分類)」が無料でダウンロードでき、多クラス分類問題などのディープラーニングや統計学/データサイエンスに利用できる。scikit-learnにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「Diabetes」について説明。442件の糖尿病の「表形式データ(年齢/血圧/血糖値などの10項目)」+「ラベル(1年後の糖尿病進行度)」が無料でダウンロードでき、回帰問題などのディープラーニングや統計学/データサイエンスに利用できる。scikit-learnにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「Iris」について説明。150件のあやめの「表形式データ(花びら/がく片の長さと幅の4項目)」+「ラベル(3種類のあやめの分類)」が無料でダウンロードでき、多クラス分類問題などのディープラーニングや統計学/データサイエンスに利用できる。scikit-learnとTensorFlowにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「California Housing」について説明。2万640件のカリフォルニアの住宅価格の「表形式データ(部屋数や築年数などの8項目)」+「ラベル(住宅価格)」が無料でダウンロードでき、回帰問題などのディープラーニングや統計学/データサイエンスに利用できる。scikit-learnにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「SVHN」について説明。約10万枚(難易度が低いサンプルを含めると約63万枚)の「Googleストリートビューから切り抜いた家の番地における1文字分の数字」の「画像+ラベル」データが無料でダウンロードでき、画像認識などのディープラーニングに利用できる。TensorFlow、PyTorchにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
自然言語処理系のデータセットが簡単に使えるHugging FaceのDatasetsを紹介。データセット一覧ページでは、フィルタリングしながら人気順でデータセットを探せる。各データセットページでは、データセットの概要説明が掲載されているだけでなく、データセット内容を表示する機能や、データセットを使うための基本コードを取得する機能もある。

AI・機械学習のデータセット辞典:
データセット「COCO」について説明。約33万枚のカラー写真(教師ラベル付きは20万枚以上)の画像データとアノテーション(=教師ラベル)が無料でダウンロードでき、物体検知/セグメンテーションや、キーポイント検出/姿勢推定、キャプション作成などに利用できる。

AI・機械学習のデータセット辞典:
データセットが効率よく見つけられるPapers With CodeのDatasetsを紹介。各データセットのページでは、データセット利用に向くタスクや、ベストな性能を発揮するモデル、コードありの論文、各ライブラリのデータローダー、データセットの人気傾向などを確認できる。

AI・機械学習のデータセット辞典:
データセット「浮世絵顔」(v1.0)について説明。1万6653枚の浮世絵の「顔画像データ+メタデータ(作品名や役者などの書誌情報)+アノテーションデータ(顔パーツと顔領域の座標データ)」が無料でダウンロードでき、画像認識などに利用できる。データセットをダウンロードできるPythonファイルについても紹介。

AI・機械学習のデータセット辞典:
4つの人気クラウドプラットフォームで手軽に利用できるオープンなデータセットの一覧ページである「Registry of Open Data on AWS」「Azure Open Datasets」「Google Cloud 一般公開データセット」「IBM Developerの『データセット』カテゴリー」を紹介する。

AI・機械学習のデータセット辞典:
データセット「Wiki-40B」について説明。高品質に加工された、英語や日本語を含む40以上の言語におけるWikipediaテキストが無料でダウンロードでき、自然言語処理の言語モデルの作成などに利用できる。TensorFlowにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「Food-101N」について説明。31万9枚、101種類の料理カラー写真(アップルパイや餃子など)の「画像+ラベル」データが無料でダウンロードでき、ラベルノイズ問題の研究や画像認識などのディープラーニングに利用できる。

AI・機械学習のデータセット辞典:
データセット「Food-101」について説明。10万1000枚、101種類の料理カラー写真(アップルパイや餃子など)の「画像+ラベル」データが無料でダウンロードでき、画像認識などのディープラーニングに利用できる。TensorFlowにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「Open Images Dataset」について説明。物体検知用の境界ボックスや、セグメンテーション用のマスク、視覚的な関係性、Localized Narrativesといったアノテーションが施された、約900万枚と非常に膨大な数の画像データセット。その概要と使い方を紹介する。

AI・機械学習のデータセット辞典:
Bingキーワード検索による画像データの収集を、Pythonライブラリのicrawlerを使って簡単に行う方法を紹介する。たった3行のコードで非常にシンプル。

AI・機械学習のデータセット辞典:
データセット「QMNIST」について説明。MNISTを改良してテストデータを1万から6万に増やし、合計12万枚となった手書き数字の「画像+ラベル」データが無料でダウンロードでき、画像認識などのディープラーニングに利用できる。PyTorchにおける利用コードやTensorFlowにおける情報も紹介。

AI・機械学習のデータセット辞典:
データセット「EMNIST」について説明。81万枚〜7万枚の手書きアルファベットおよび数字の「画像+ラベル」データが無料でダウンロードでき、画像認識などのディープラーニングに利用できる。PyPIパッケージ、TensorFlow、PyTorchにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「Reuters newswire」について説明。1万1228件のロイターニュース配信テキストに対するトピック分類問題が扱えるデータセットについて説明する。TensorFlow/Kerasにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「ImageNet」について説明。1400万枚以上のカラー写真(教師ラベルは2万カテゴリー)の画像データ(のURLなど)が無料でダウンロードでき、画像認識などに利用できる。主に研究/教育目的で用いられてきた歴史的に有名なデータセットであるが、現在では多くの問題も指摘されている。

AI・機械学習のデータセット辞典:
日本政府が公開するオープンデータの中でも、機械学習/データサイエンスに活用できるお勧めのデータセットを厳選して紹介する。具体的には「e-Stat(政府統計の総合窓口)」「Tellus(衛星データプラットフォーム)」「過去の気象データ(気象庁)」の3つ。

AI・機械学習のデータセット辞典:
「300個以上のデータセットを紹介している大型サイト」「毎週/毎月のようにアクティブに更新されているサイト」という条件に該当するお勧めのデータセット一覧サイトとして「arXivTimes/DataSets」「Awesome Public Datasets」「UCI Machine Learning Repository」の3つを紹介する。

AI・機械学習のデータセット辞典:
機械学習やディープラーニング用の主要ライブラリが提供する「画像/音声/テキストなどのデータセット」の名前とリンクを表にまとめ、典型的な使い方を簡単に紹介する。
AI・機械学習のデータセット辞典:
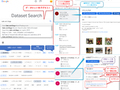
世界中のデータセットがググれる(=Google検索できる)「Dataset Search」を紹介。検索結果のフィルタリングや、日本語対応、対象ページを開く方法、内容記載などについて言及する。

AI・機械学習のデータセット辞典:
データセット「Large Movie Review」について説明。IMDbサイト上での5万件の「テキスト(映画レビューコメント)」+「ラベル(ポジティブ/ネガティブの感情)」が無料でダウンロードでき、二値分類問題などのディープラーニングや機械学習に利用できる。元データの内容や、TensorFlow、Keras、PyTorchなどにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「Titanic」について説明。1309件の「タイタニック号乗客者の生存状況」の「表形式データ(年齢や性別などの13項目)」+「ラベル(生存状況)」が無料でダウンロードでき、分類問題などのディープラーニングや統計学/データサイエンスに利用できる。scikit-learn、TensorFlow、Kaggleにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「Boston Housing」について説明。506件のボストンの住宅価格の「表形式データ(部屋数や犯罪率などの13項目)」+「ラベル(住宅価格)」が無料でダウンロードでき、回帰問題などのディープラーニングや統計学/データサイエンスに利用できる。scikit-learn、Keras/tf.keras、TensorFlowにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「CIFAR-100」について説明。6万枚の物体カラー写真(動植物や機器、乗り物など100種類)の「画像+ラベル」データが無料でダウンロードでき、画像認識などのディープラーニングに利用できる。Keras/tf.keras、TensorFlow、PyTorchにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「CIFAR-10」について説明。6万枚の物体カラー写真(乗り物や動物など)の「画像+ラベル」データが無料でダウンロードでき、画像認識などのディープラーニングに利用できる。scikit-learn、Keras/tf.keras、TensorFlow、PyTorchにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「Fashion-MNIST」について説明。7万枚の写真(ファッション商品)の「画像+ラベル」データが無料でダウンロードでき、画像認識などのディープラーニングに利用できる。scikit-learn、Keras/tf.keras、TensorFlow、PyTorchにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「KMNIST」について説明。7万枚の手書き文字(くずし字)の「画像+ラベル」データが無料でダウンロードでき、画像認識などのディープラーニングに利用できる。データセットをダウンロードできるPythonファイルについても紹介。

AI・機械学習のデータセット辞典:
データセット「MNIST」について説明。7万枚の手書き数字の「画像+ラベル」データが無料でダウンロードでき、画像認識などのディープラーニングに利用できる。scikit-learn、Keras/tf.keras、TensorFlow、PyTorchにおける利用コードも紹介。

AI・機械学習のデータセット辞典:
データセット「fastMRI」について説明。1500枚以上の膝MRIの画像データや、6970枚の脳MRIの画像データが無料でダウンロードできる(契約と申請が必要)。
編集部からのお知らせ

2026年3月23日(月)〜 3月24日(火)にオンラインセミナー「@IT Architect Live AI時代のエンジニアリングを再定義する」を開催します。
注目のテーマ

![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。