Open Images Dataset:Googleによる膨大な画像データセット:AI・機械学習のデータセット辞典
データセット「Open Images Dataset」について説明。物体検知用の境界ボックスや、セグメンテーション用のマスク、視覚的な関係性、Localized Narrativesといったアノテーションが施された、約900万枚と非常に膨大な数の画像データセット。その概要と使い方を紹介する。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
データセット解説
Open Images Dataset(以下、Open Images)は主に、
- 物体検知(Object detection)用の境界ボックス(Bounding box、図1)
- セグメンテーション(Segmentation=領域の切り出し)用のマスク(Mask、図2)
- 視覚的な関係性(Visual relationship、詳細後述、図3)
- 位置表示させた口頭説明(Localized Narratives、詳細後述、図4)
といった種類のアノテーション(=教師ラベル付け)が施された画像データセットである。
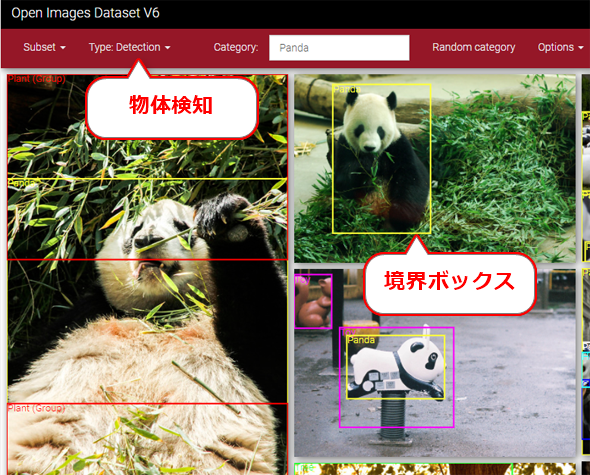 図1 Open Imagesデータセットが提供する「物体検知用の境界ボックス」データの例
図1 Open Imagesデータセットが提供する「物体検知用の境界ボックス」データの例※データセットの配布元: 「Open Images」。アノテーションはCC BY 4.0ライセンスで、画像はCC BY 2.0ライセンス。以下、図2〜図4も同じなので注記を割愛する。
※なお、本稿における画像内のフキダシは、全て筆者が説明のために入れたものである。
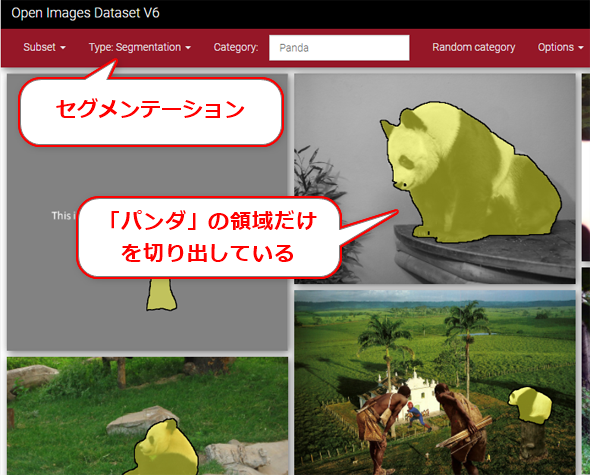 図2 Open Imagesデータセットが提供する「セグメンテーション用のマスク」データの例
図2 Open Imagesデータセットが提供する「セグメンテーション用のマスク」データの例 図3 Open Imagesデータセットが提供する「視覚的な関係性」データの例
図3 Open Imagesデータセットが提供する「視覚的な関係性」データの例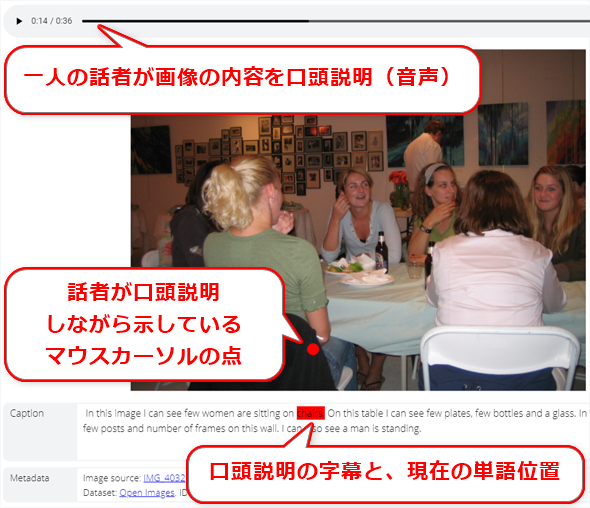 図4 Open Imagesデータセットが提供する「位置表示させた口頭説明」データの例
図4 Open Imagesデータセットが提供する「位置表示させた口頭説明」データの例物体検知用の境界ボックスと、セグメンテーション用のマスクは、画像認識でよくあるアノテーション種別なので、説明不要だろう。
視覚的な関係性(Visual relationship)とは、あるオブジェクト(※「投げる」などの行為を含む)と視覚的な関係性があるオブジェクトをペアにするアノテーションが付与されたデータである。例えば[Category](カテゴリー)として「throw(投げる)」オブジェクトを選択した場合、それと視覚的な関係性がある「Cricket ball(クリケットボール)」や「Volleyball(バレーボール)」、「Football(フットボール)」といったオブジェクトが含まれる画像群がデータセットとして取得できる。このアノテーション種別は、例えば「ギターを弾く女性」「テーブルの上のビール」といったように、関連性のある2つのオブジェクトに対するキャプションを生成するといった目的などで役立つだろう。なお、ペアとなる2つのオブジェクトは、境界ボックスで示される(前掲の図2を参照)。
物体検知/セグメンテーション/視覚的な関係性は、Exploreページから閲覧/体験できる。
また、位置表示させた口頭説明(Localized Narratives)とは、Open Images V6(後述)で新たに提案されたアノテーション種別で、「一人の話者が対象画像の内容を、マウスカーソルによって位置を示しながら口頭で説明する」というアノテーションが付与された画像データである。ちなみにNarratives(ナラティブ)は、口頭で説明する物語のことで、例えば「今日、お買い物中に起こった珍事」を一人の話者が主体性を持って友人/知人に説明することなどである。Localized(ローカライズド)は、通常は文章内容を翻訳で地域化することだが、ここでは口頭説明している内容をマウスカーソルで位置表示することを示している。厳密には、元論文「Connecting Vision and Language with Localized Narratives」(arXiv:1912.03098 [cs.CV])を参照してほしい。
位置表示させた口頭説明がなかなかイメージできない場合は、専用のExploreページで体験してみてほしい。
以上、4種類のアノテーションがあるわけだが、これは2020年2月26日に公開された「Open Images V6」の内容である点に注意してほしい(※V6は、2020年11月9日の執筆時点で最新のバージョン)。最初のV1が2016年に登場してから、V1〜V6と6つのバージョンが既に公開されている。各バージョンの内容については、下記のリンク先を参照してほしい。
Open Imagesデータセットの画像枚数(V6時点)は、上記リンク先ページの説明に基づくと、以下の通りだ(※1枚の画像に複数のシーンが含まれている場合が多々あるため、画像枚数とアノテーション数は、一致するとは限らない)。
- データセット全体: 最大900万枚(アノテーション数:約5990万個、教師ラベルの分類数:約1万9957クラス)
- Boxes(物体検知用の境界ボックス): 約190万枚の画像上に、合計約1600万個(オブジェクト分類数は約600クラス)
- Segmentations(セグメンテーション): 約280万個(オブジェクト分類数は約350クラス)
- Relationships(視覚的な関係性): 約330万個(視覚的な関係性ペアの分類数は約1466クラス)
- Localized Narratives(位置表示させた口頭説明): 約50万7000個
引用のための情報
このデータセットは、基本的に自由に使用できる(※アノテーションはCC BY 4.0ライセンスで、画像自体はCC BY 2.0ライセンス。厳密には各バージョンの公式ページの「Licenses」欄を確認してほしい)。
引用情報を以下にまとめておく。厳密には公式ページの「Publications」欄を参照してほしい。
物体検知用の境界ボックスや視覚的な関係性を利用する場合は、引用内容は次のようになる。なお、V4となっているが、V5やV6でも同じとのこと。
- 作成者: Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, Tom Duerig and Vittorio Ferrari
- タイトル: The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale
- カンファレンス: IJCV 2020
- 公開日: [v1]2018年11月2日、[v2]2020年2月21日
- URL: http://arxiv.org/abs/1811.00982
セグメンテーションを使用する場合は、下記のように。
- 作成者: Rodrigo Benenson, Stefan Popov and Vittorio Ferrari
- タイトル: Large-scale interactive object segmentation with human annotators
- カンファレンス: CVPR 2019
- 公開日: [v1]2019年3月26日、[v2]2019年4月17日
- URL: http://arxiv.org/abs/1903.10830
Localized Narratives(位置表示させた口頭説明)を使う場合は以下のようになる。
- 作成者: Jordi Pont-Tuset, Jasper Uijlings, Soravit Changpinyo, Radu Soricut and Vittorio Ferrari
- タイトル: Connecting Vision and Language with Localized Narratives
- カンファレンス: ECCV 2020 Camera Ready
- 公開日: [v1]2019年12月6日、[v2]2020年2月25日、[v3]2020年3月17日、[v4]2020年7月20日
- URL: http://arxiv.org/abs/1912.03098
利用方法
Open Imagesの各バージョンのデータセットは、下記のリンク先でダウンロードできる。
TensorFlow Datasets
TensorFlow Datasetsでは、
- open_images_v4(565.11GB)
- open_images_challenge2019_detection(534.63GB)
という2種類のデータセットが提供されている(※2020年11月9日の執筆時点)。そこで実際にデータセットをロードするためのコード例をリスト1に示しておく。
# !pip install tensorflow tensorflow-datasets # ライブラリ「TensorFlow」と「TensorFlow Datasets」をインストール
import tensorflow_datasets as tfds
openimages_train = tfds.load(name="open_images_v4", split="train")
load()メソッドの引数nameに'open_images_v4'や'open_images_challenge2019_detection'を指定すればよい。
ただし、それぞれ500GB超えと、ダウンロードするデータセット全体の容量が非常に大きい点に注意してほしい。例えばGoogle Colab環境では、ディスクの空き領域が足りずにエラーになってしまう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。