MIME(Multipurpose Internet Mail Extensions)〜後編:インターネット・プロトコル詳説(4)
複数ファイルを同時送信するマルチパート・メール
前回(第3回「メールにかけられた呪文〜MIME(前編)」)は、主に単一のファイルをインターネットメールに添付する場合について説明した。しかし、実際にメールを送受信する際には、本文にテキストを記載し、アプリケーションのデータや画像ファイルを複数添付することが多い。このような場合に利用するのが、マルチパート(multipart)メディアタイプというものである。
マルチパート・メディアタイプとは、“マルチパート”という言葉が示すように、複数の添付ファイルをまとめたメディアタイプのことである。ここで次の例を見てほしい。
|
|||||||||||||||||||
(空行) |
|||||||||||||||||||
|
|||||||||||||||||||
まずヘッダ部で、マルチパートであることを宣言している。ボディ部は、複数の「MIMEヘッダ+ボディ」から構成される「ミニ・メッセージ」、すなわち「パート」になっている。これが1つの添付ファイルやメール本文に該当する*1。多くのメーラでは、メール本文にテキストを記載してファイルを添付すると、このマルチパート形式となる。 1つのパートの境界は、「バウンダリ:boundary」と呼ばれる任意の文字列の行で示される。これはContent-Typeのboundaryパラメータで、あらかじめヘッダに示されている。 --バウンダリ文字列 これで、1つのパートの開始を示す。また、次の文字列の場合、全体のマルチパートの終了を意味する。 --バウンダリ文字列-- この境界ごとにパートは分割されると考える。また、マルチパートのパートとして、マルチパート・メッセージが含まれることがある。このような複雑な入れ子状態のメッセージも利用できる。 マルチパートは、単に複数のファイルを送るという意味だけではなく、複数ファイルの組み合わせが変わることで、さまざまな意味をメッセージに持たせることができる。マルチパートのサブタイプとして、RFC2045とRFC2046では、次のような種類を定義している。 ○multipart/mixed最も一般的なマルチパート。個々のパートはそれぞれ別のデータを示す。メーラはそれらすべてを個別に、かつ任意に表示できればよい ○multipart/alternative含まれるパートは同じ内容を示す。例えば、プレーンテキスト(text/plain)とHTML(text/html)に同じ本文が含まれる場合などに使用される。この場合、両方を同時に表示する必要がないため、HTML表示ができる場合にはHTMLを、そうでない場合にはテキストを表示するといった対応がメーラに求められる ○multipart/parallel含まれるパートを複合して同時に表示させる必要がある。例えば、音声ファイルと画像や動画ファイルとの組み合わせなどを想定している ○multipart/digest主にニュースやメール・メッセージを複数含めることを目的としている。例えば、メーリングリストなどで複数のメールをまとめて送りたい場合などに使用できる。そのため、含まれるパートは主にmessage/rfc822となる *1パートのヘッダは省略できる。この場合は、text/plain;charset=US-ASCIIであると見なされる 日本語はテキストではない?〜テキストの送受信MIMEメールで注意する必要があるのは、テキストを送信するときである。この問題は、われわれが日本語を使用していることと関係している。 すでに述べたように、インターネットメールは7ビットデータのみをテキストと見なし、それ以外のデータは、MIMEでのエンコードが必要となる。しかし、多くの日本語文字コードは8ビットコードである。例えば、シフトJIS、JIS、EUCがそうだ。 ここでは詳細な文字コードの解説は省くが、唯一定義されている7ビットの日本語コードは、ISO-2022-JPと呼ばれるコードである。もともとは、JUNETと呼ぶ日本でのインターネット環境の前身であるネットワークで使用されていた文字コード体系である。 このコード体系はJISとほぼ同じである。JISと異なるのは、半角カナなどに該当するコードが空けられている点だ。半角カナが該当するコードは、0x7f以上に該当するためだ。「メールで半角カナを使用してはいけない」というルールは、実はこれを反映している。 ISO-2022-JPを使用してメールを表現すると、次のようになる。
Content-Typeでは、コードがISO-2022-JPであることをcharsetによって示している。Content-Transfer-Encodingは、ISO-2022-JPが7ビットコードなので、当然7ビットである。ただし、この記述は省略してもよい(Content-Transfer-Encodingのデフォルト値が7ビットのため)。これで通常のテキストメールが完成する。 多くの場合は、以上の方法で問題ない。しかし、シフトJISやほかのコードで表現したい場合もあるだろう。例えば、半角カナや機種依存コード(丸付き数字や単位記号など)を含んでいるため、ISO-2022-JPに変換できない場合や、正確に送信する必要のある原稿などを添付ファイルにする場合だ。 こうした場合は、以下のように格納されることがある。 (中略) MIME-Version: 1.0 Content-Type: text/plain; charset="SJIS" Content-Transfer-Encoding: base64 (中略) (中略) MIME-Version: 1.0 Content-Type: application/octet-stream Content-Transfer-Encoding: base64 (中略) つまり、テキストファイルをバイナリファイルのように添付ファイルとして扱うのである。つまり、テキストファイルをMIME化すればよい(この方法は複数ある)。 MIME化するメリットとしては、コードを変換することなく、そのまま相手に伝えることができる点にある。しかし、現在この方法に対応したメーラの中には、ユーザーが指定しない場合も日本語テキストを自動的にファイルにして添付できる製品が存在する。 ややこしいのは、いずれも現在のMIMEの規格上、間違っていない点だ。つまり、さまざまな議論があるために明快な標準仕様がなく、その間にメーラでの実装が進んでしまったのである。さらに問題をさかのぼると、7ビットコードしか認めていなかったインターネットメール仕様に行き着いてしまう。 こうした事情も、メールの歴史を考えると興味深いものがある。 ヘッダでの日本語の利用メール本文で日本語(非ASCII文字)を利用する場合は以上のとおりだ。これは、ボディのエンコードをヘッダで定義する考え方だと言い換えることもできるだろう。しかし、ヘッダでも日本語など、非ASCII文字を使用したい場合もあるはずだ。 一般的なヘッダでの利用主にSubjectやメールアドレスのコメント、フレーズ部分での非ASCIIテキストの利用方法は、RFC2047に定義されている。ここでは、前回で解説したエンコード方法のBase64やQuoted Printableを用いてエンコードして格納する。以下の例を見てほしい。
これらは、「ヘッダ値」だけで行われるエンコード形式だと考えてほしい。 エンコード部分は「=?」と「?=」で囲まれた部分になる。それが「?(クエスチョンマーク)」によって3つのブロックに分かれている。先頭のブロックは、エンコードされたデータの文字コードを示している。次のブロックは、元データのエンコード形式を示している。ここでは、Base64かQuoted Printable形式のいずれかが用いられる。最後のブロックは、エンコードされたデータだ。 エンコードされたデータをエンコード方式に従ってデコードすると、文字コードで表現された非ASCII文字が現れる。 また、エンコードする文字列が長すぎて複数行になることがある。こうした場合は、ほかのヘッダのように続く行は空白か水平タブで始めるとともに、同じ行内で「=?」と「?=」 で閉じなければならない。 添付ファイル名添付ファイル名は、通常Content-Dispositionヘッダのfilenameパラメータで表される。多くの場合、次の例のようにほかのヘッダ部分とまったく同じ表記になる。 MIMEエンコードをそのまま適用した例 Content-Disposition: attachment; filename="=?ISO-2022-JP?B?GyRCIXcjSSNUJW0lNCVeITwlLxsoQi5naQ==?= =?ISO-2022-JP?B?Zg==?=" ところが、一般的に使用されているこの方式はMIME違反に当たる。RFC2047では、このようなエンコードされた文字列は、Content-Dispositionなどの「パラメータ」に現れてはいけないことになっている。実は、RFC2047での仕様は非ASCII文字を想定していないだけという可能性もあるが、このままでは大半の日本語対応メーラはMIME違反のままとなる。 そこで、RFC2231では、以下のような方法で非ASCII文字の添付ファイル名を示すこととしている。上記の例をRFC2231形式で表してみよう。 RFC2231を適用した例
|
|||||||||||||||||||
|
または
|
|||||||||||||||||||
|
|||||||||||||||||||
|
filenameパラメータ名の最後に付く「*(アスタリスク)」は、値が非ASCII文字を含むことを示している。ASCII文字だけで構成される場合には付かない。また、複数行になる場合には、「*」に続けて行連番号を示さなければならない。
文字コードと言語コードによって、エンコードされている文字を示す。なお、言語コードはRFC1766で定義されている。エンコード文字は、「%」に続く2文字が16進で文字を表した際のコードで示される。もちろんこのコード番号は、文字コードと合致していなくてはならない。
いやはや、なんとも複雑である。このように、日本を含む非英語圏の言葉をメールで利用することは、とても面倒なことなのだ。
なお、RFC2231はヘッダ値でのエンコード形式にも言語コードを含めるように提唱している。実際、RFC2231への対応は徐々に主要メーラでの実装が進んでいるので、あと数年もすれば、RFC2231による方法が主流となるだろう。
メール・メッセージで使用されるさまざまな書式
本文で触れなかったが、メール・メッセージに共通して用いられる書式が存在する。多くの場合「見れば分かる」だろうが、メールに限らずほかのプロトコルでも多用される書式でもある。そこで、ここではそれらをまとめて解説しよう。
●RFC822時刻形式
日付/時刻は、プロトコルによってさまざまな書式が並列して使用されることがある。その中にあってRFC822形式と呼ばれる形式は、ほぼ標準として最も頻出する書式だろう。
曜日, 日 月 年 時:分:秒 タイムゾーン
曜日: "Mon" | "Tue" | "Wed" | "Thu" | "Fri" | "Sat" | "Sun"
月: "Jan" | "Feb" | "Mar" | "Apr" | "May" | "Jun" | "Jul" | "Aug" | "Sep" | "Oct" | "Nov" | "Dec"
タイムゾーン: GMTとの時差(HHMM)か、またはタイムゾーンを示す以下のような予約文字列
"UT" | "GMT" | "EST" | "EDT" | "CST" | "CDT" | "MST" | "MDT" | "PST" | "PDT"
ただし、現在ではタイムゾーンを使用することはあまり推奨されていない。
(例) Sun, 18 Feb 2001 01:10:15 +0900
厳密に説明すれば、RFC822では年を2けたとしている。つまり、2000年問題に対応していなかったわけだ。RFC1123において、これを4けたに修正している。
●アドレス形式
いわゆるメールアドレスの書式だが、「ユーザー名@ドメイン名またはサーバ名」であることはよく知られている。
なお、アドレスにはコメントなどを含めることもできる。
"フレーズ" ユーザー名@ドメイン名またはサーバ名 >
この形式は、フレーズパートという名前で知られている。「"(ダブルクオーテーション)」でくくっているが、これがない場合もある。アドレスをくくっている <>によって、実際のアドレスは<>内にあることを示す。
ユーザー名@ドメイン名またはサーバ名(コメント)
ヘッダの ( ) 内には、コメントを記述できるので、それ以外がアドレスを示すと解釈できる。
メール・フォーマットをメーラで確認する
ここまで説明したようなメールの構造は、手元のメーラで簡単に確認することができる。
Outlook Expressを利用している場合、メールのプロパティを選択すると、そのメールのヘッダ情報を確認できる。また、メッセージ全体のソースを表示することも可能だ。ほかのメーラにも同様の機能があるので、ぜひ一度試してほしい。
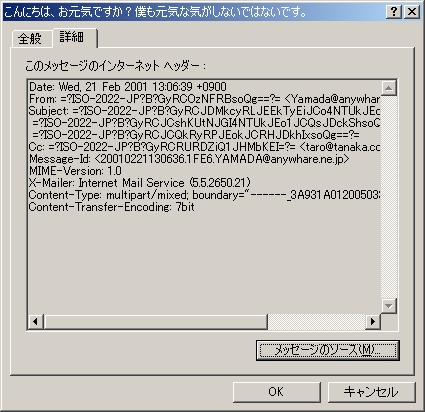 画面1 Outlook Expressのプロパティで、メールのヘッダ部分を確認できる
画面1 Outlook Expressのプロパティで、メールのヘッダ部分を確認できるこのように、MIMEはテキストの呪縛に縛られたインターネットメールを解き放つ素晴らしい呪文だ。しかし、符号化と構造化の呪文には、やや複雑な印象を受けるだろう。
だが、MIMEやメール・フォーマットがこうした構造化を受け持つことで、実際にメールを送受信するほかのプロトコルでは、メールの内容をほとんど意識することなく、送受信にのみ集中できるというメリットになっているのも事実である。
次回は、こうしたメリットがどのように生かされているのかを含めて、SMTPについて考えてみよう。
- インターネット・プロトコルをインターネットから探ろう
- FTP(File Transfer Protocol)〜後編
- FTP(File Transfer Protocol)〜前編
- IMAP4(Internet Mail Access Protocol version 4)〜後編
- IMAP4(Internet Mail Access Protocol version 4)〜前編
- POP3(Post Office Protocol version 3)
- SMTP(Simple Mail Transfer Protocol)〜後編
- SMTP(Simple Mail Transfer Protocol)〜前編
- MIME(Multipurpose Internet Mail Extensions)〜後編
- MIME(Multipurpose Internet Mail Extensions)〜前編
- HTTP(Hyper Text Transfer Protocol)〜後編
- HTTP(Hyper Text Transfer Protocol)〜前編
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。