多言語対応の問題と解決を考える:XMLを学ぼう(11)
XMLは、最初から英語や日本語などの多言語を扱えるように設計されている。だからこそ、生まれてすぐに日本語でもガンガン活用することができ、世界から遅れることなく、日本のXML界は立ち上がったと言える。今回はそのXML多言語化で重要な役割を持つ、xml:lang属性をとりあげてみよう。
I18N、L10N、M17Nとは?
今回は、主にxml:langという属性と、それにまつわる話題を解説する。前回xml:spaceという属性を紹介したが、実はXML仕様書にはもう1つ、名前を明確に決められた属性が規定されている。それがxml:langである。その役割は、「言語の指定」である。といっても、それだけではピンとこない人も多いだろう。今回は、XMLの基盤技術の1つであるUnicodeのレベルから、xml:lang属性の意味と価値を解説しよう。
さて、本題に入る前に、多言語対応の重要性について書いておこう。多言語対応とは、(あるシステムが)日本語なら日本語という、1つの言語だけに対応しているのではなく、複数の言語が使い分けられることをいう。
多言語対応には、大まかに分けて次の3つの段階がある。I18N(Internationalization)は、システムが多言語に対応するための準備ができていることをいう。L10N(Localization)はI18Nより一歩進んだ段階で、特定の1言語で必要とされる、その言語特有の機能を持っていることをいう。例えば日本語のふりがな(ルビ)や禁則処理がそれにあたる。さらにその次の段階として、M17N(Multilingualization)がある。これは複数の言語に対するL10N(Localization)が行われており、1つのデータの中で次々に言語を切り替えることが可能である状態だ。
XMLという言語は、I18Nの段階をクリアしている。つまり、XMLは入れ物としてどんな言語のデータでも受け入れられる間口の広さを持っている。XMLそのものは特に特定言語特有の機能(日本語ならルビや禁則処理)まで規定しているわけではないので、XMLのレベルでL10NやM17Nに対応しているとは言えない。しかし、そのような機能を与えられた新しい要素を規定して利用するのは容易である。つまり、XMLはL10N(Localization)やM17N(Multilingualization)を達成しやすい言語であるといえる。
だが、達成しやすいからといって、果たしてそれは意味のある機能なのだろうか? 確かに日本語を使う日本人にとって日本語対応は必要だろう。だが、日本語以外に対応する必要があるだろうか?
考えてみれば、国境を越えて人・物・金が移動することは、今後さらに増えることはあっても減ることはなさそうだ。秋葉原などへ行けば、パッケージや商品の説明書などが複数言語併記になっているものも珍しくはない。さらに、パッケージが特定言語だけで書かれている場合でも、メーカー側にある元データは、複数言語併記となっていて、切り替えながら利用している場合もある。どうやら、日本語以外を見ないで済む幸運な時代は終わりつつあるようである。
つまり、昨日までは、多言語を扱うことは特別な立場の人だけの話だったかもしれないが、明日になれば、ぐっと身近になる可能性があるということだ。そのような観点から、今回の内容を読んでいただきたい。
それは何語で書かれたものか
いまから10年ぐらい前の人たちは、多言語という問題をあまり真剣に考えていなかった。考える必要もあまりなかった。意外と、「英語を使うときはUS-ASCIIコード」「日本語を使うときはシフトJISかEUC-JP」というような、とても大ざっぱな考えでも何とかなったのである。アメリカ人相手にシフトJISを使うこともないので、日本国内だけで1つの閉じた世界をつくることができた。
そこに、黒船のごとく迫ってきたのがUnicodeというわけだ。Unicodeは全世界の文字を収録する1つの文字セットを目指している。つまり、文字セットを使い分けるという考え方を取らない。Unicodeを採用すれば、それだけで、世界のすべての文字が使えるようになることが理想である。
しかし、Unicodeは簡単に受け入れられたわけではない。さまざまな批判を受けた。そのうちの1つが、Unicodeで書かれた文字列は、何語で書かれたのか分からないというものだ。なぜ何語で書かれたか分からないことが問題なのだろうか。例えば「骨」という字があるが、日本と中国では文字の形が少々違うのだ。日本語と中国語が入り交じった文章をUnicodeで書くと、どちらの国の文字の形で表示すればいいのか分からない場合がある。具体例を以下に示そう。中国語(簡体字)のサポートをインストールした日本語版Windows 2000上で、この問題を引き起こしてみた。ソフトはお馴染みのメモ帳で、Unicode編集モードで使用している。上の画面は、皆さんおなじみの文字「骨」を、MSゴシックで表示したもの。そして、下は、一切内容を書き換えることなく、メモ帳のフォント指定だけを中国語フォントであるSimHeiに変更したものだ。
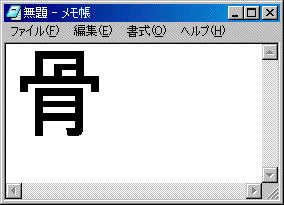 画面1 Windows 2000のを使い、Unicode編集モードで「骨」という文字を入力。MSゴシックで表示したもの。日本語のおなじみの文字が表示される
画面1 Windows 2000のを使い、Unicode編集モードで「骨」という文字を入力。MSゴシックで表示したもの。日本語のおなじみの文字が表示される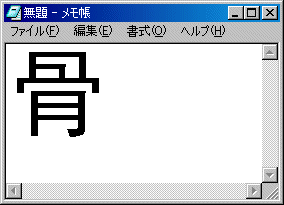 画面2 上記の内容をまったく変更せずに、表示するフォントを中国語フォントであるSimHeiに変更したもの。Unicode上では同じ文字コードであっても、中国語用のフォントでは微妙に文字の形状が異なる
画面2 上記の内容をまったく変更せずに、表示するフォントを中国語フォントであるSimHeiに変更したもの。Unicode上では同じ文字コードであっても、中国語用のフォントでは微妙に文字の形状が異なるいうまでもなくメモ帳のフォント指定はメモ帳に対して作用するものであって、保存されるテキストファイルには、どんなフォントを設定したかという情報は入らない。そのため、このテキストファイルをだれかに渡したときに、テキストの中にはどちらの「骨」を意図して書かれた文書なのか、それを知るためのヒントは何もない。そのため、Unicodeは欠陥品であるという意見があった。
だが、このような考え方は、よく考えると短絡的すぎる。細かいデザインの再現にこだわり始めると、すぐに何語か分かるだけでは不十分ということになる。もっと詳細なデザインに関する情報を付け加えねばならない。付加する情報として最も手っ取り早いのは、文字列をどのフォントで表示するべきかという情報である。つまり、文字の微妙なデザインの問題と、言語指定の問題の混同こそが、この批判の正体であるといえる。
しかし、フォントさえ指定できればよいのかというと、そうではない。言語の違いは、禁則処理などのルールにも影響を及ぼす。そのため、本当にM17N(Multilingualization)を目指すなら、その文字列がどんな言語で書かれているかという情報を入れる必要がある。
その上、厳密な意味で文字列がどんな言語で書かれているかという情報は、Unicode以前からもあったとは言い難い。なぜなら、シフトJISやEUC-JPには、英語で使うアルファベット一式が入っているのだから、日本語だけでなく英語も書ける。さらに、ロシア語の文字も一式入っているので、ロシア語も書ける。つまり、日本人は日本人しか使わないシフトJISは日本語用のもの、と思い込んでいたが、内容の実体からすれば、英語、ロシア語、日本語に対応する多言語文字セットを構成していたといえるわけである。つまり、Unicodeになったからどの言語か分からなくなったというわけではない。ということは、言語指定は、文字セットという範疇とはまったく別個に、明示的に指定可能である方がよい。それがあってこそ、完全に言語を扱うことができる。
2種類の言語指定
XMLにおける文字セットの指定(厳密には文字符号化方式)は、XML宣言に書き込むことができる。だが、これは、文字セットの指定であって言語の指定としては機能しないことに注意が必要だ。つまり、<?xml version="1.0" encoding="Shift_JIS"?>とシフトJISの名前が書かれていたとしても、そのXML文書が日本語であるという保証は何もない。そもそも、XMLでは、文字参照を用いてUnicodeに含まれるすべての文字を記述できるわけで、文字セットでシフトJISを指定しながらハングル文字で文書を書くことも不可能ではない。
では、純粋に文字セットとは関係なく、言語を指定する方法はあるのだろうか。ここで重要なのは、2つの考え方が対立して出てくることだ。
- 言語指定は必要な機能だからUnicodeが用意すべき
- XMLの要素か属性で指定すれば済む話
この背景には、さらに個人個人の世界観の違いがある。XMLが世の中に多数あるデータ表現の1つと考える者なら、XMLでだけ利用できる指定方法は便利に見えないだろう。だが、XMLを次世代のプレーンテキストととらえて、今後はどんなデータもXMLで書いていけばよいと考えるなら、XMLで容易に解決できることはXMLで解決すればよいだろう、と考えることになる。
この2つの考え方が対立したまま、UnicodeとXMLの進化が進行した。その結果、Unicodeには言語タグというものが導入され、XMLにはxml:lang属性というものが導入されてしまった。
だが、この状況は極めて不幸である。例えばUnicodeの言語タグで英語と指定されているのに、XMLのxml:lang属性では日本語と指定されたら、いったいどちらを信じたらよいのだろうか?
この問題に関しては、XMLのようなマークアップ言語に存在する機能を使った場合、それを優先する、ということで問題は決着を見ている。つまり、XMLで言語指定を入れたい場合はxml:lang属性で指定し、Unicodeの言語タグは使わない。そのようなわけで、ここではUnicodeの言語タグの詳細の説明は行わず、xml:lang属性を解説したい。
XMLではxml:lang属性を使う
xml:lang属性は、XML 1.0勧告の中で規定されている。基本的にXMLのどの要素にも付けることができる属性である。
xml:というのが名前空間接頭辞のように見えるが、XML 1.0勧告単体で使用する場合は「xml:lang」全体で1つの名前となる属性であり、xml:は名前空間接頭辞ではない。名前空間を併用する場合は、xml:という名前空間接頭辞はhttp://www.w3.org/XML/1998/namespaceという名前空間に結びつけられていて、xml:は宣言することなく利用できる。
ただ、DTDなどと併用する場合は、xml:lang属性を付ける要素の属性リストに、xml:lang属性も書き加えておく必要がある。以下は、pという要素が英語であると指定した一例である。
<p xml:lang="en">This is a pen!</p>
xml:lang属性の内容は、IETFのRFC 3066で規定された書式に従うのだが、実はRFC 3066そのものには具体的にどの文字列が何語なのかという肝心の情報が書かれていない。RFC 3066は、さらにISO 639というISO規格を参照している。これが、各言語に対応する文字列を規定している。このほかに、IANAに登録されたi-で始まる言語名や、x-で始まるユーザー定義の名前も使用できるが、利用頻度は多くないだろう。
筆者注:XML 1.0 Recommendationでは、RFC 3066ではなくRFC 1766を参照している。しかしこれは、XML 1.0 Rercommendationが勧告された時点で、まだRFC 3066が存在しなかったためだ。現在は、RFC 3066がRFC 1766の置き換えとして存在するので、RFC 3066を参照する方が望ましい
| 日本語 | ja | |
| 英語 | en | |
| フランス語 | fr | |
| ドイツ語 | de | |
主要な言語指定文字列は右の表のようになっている。ISO 639で規定された名前の一覧はインターネット上で幾つか公開されており、これは一例である。
これらの文字列を属性値として指定すれば、その言語を指定したことになる。しかし、さらに情報を付け加えることもできる。これらのキーワードの後ろにハイフン(-)を付けて、さらに国名を付け加えることができる。国名はISO 3166で規定される2文字の名前を付ける。例えば、アメリカ合衆国はUSという2文字になる。国指定文字列には2文字のもののほかに3文字のものもあるが、ここで使うのは2文字のものである。これを付けると、en-USとなるが、これは「アメリカ合衆国の英語」という意味になる。つまり、英語は英語でも、イギリス英語と区別することもできる。
以下は実際に「アメリカ合衆国の英語」を指定した例である。
<p xml:lang="en-US">This is a pen!</p>
| 日本国 | JP | |
| アメリカ合衆国 | US | |
| イギリス | GB | |
| フランス | FR | |
| ドイツ | DE | |
主要な国指定文字列は右のようになっている。ISO 3166で規定された名前の一覧はインターネット上で幾つか公開されている。これは一例である。
さて、このルールにより、日本国で使われる日本語という指定もできる。つまり、ja-JPと書けばよいわけだ。事実上、日本国以外に日本語を国家の言語として使用している例はないので、ここまで明確化する意義はあまりないかもしれない。だが、ひょっとすると100年後ぐらいには宇宙各地に日本人の植民地が生まれ、日本語を公用語として使う別の国家が生まれるかもしれない。そのときには、意味を持つ表記となるかもしれない。もちろん、同じ言語が別の国で話されている場合は、現在でも意味のある表記として機能するのはいうまでもない。
言語指定をどう利用するか
言語指定の利用方法は主に2つ考えられる。
1つは、同じ文字列の別言語バージョンを1つのXML文書に入れてしまう方法だ。例えば、Webサイトを構築する際に、自動的に応答するメッセージを、相手のWebブラウザの言語指定によって切り替えたいとしよう。その場合に、以下のようなXML文書を用意して、言語指定によってメッセージを選択することができる。
<応答メッセージ> <朝の挨拶> <メッセージ xml:lang="ja">おはようございます</メッセージ> <メッセージ xml:lang="en">Good Morning</メッセージ> </朝の挨拶> <昼の挨拶> <メッセージ xml:lang="ja">こんにちは</メッセージ> <メッセージ xml:lang="en">Good Afternoon</メッセージ> </昼の挨拶> <夜の挨拶> <メッセージ xml:lang="ja">こんばんわ</メッセージ> <メッセージ xml:lang="en">Good Evening</メッセージ> </夜の挨拶> </応答メッセージ>
この場合は、このXML文書を読み込んで利用するプログラム側で一工夫してやる必要がある。メッセージを選択するときに、xml:lang属性の値を調べて、適切な言語のメッセージを選択するよう、プログラミングする。もちろん、この構造なら、新しい言語のメッセージを追加するのも容易だ。
もう1つは、複数の言語が1つの文書中に混在する場合だ。例えば、英語の文章を日本語で解説したり、学習用の対訳文書を作成する場合がこれにあたる。以下のような文書を書く場合に、言語指定が利用できるだろう。
<p xml:lang="ja">僕らは、突然闖入してきた金髪の少年に驚いた。</p> <p xml:lang="en">"Hey Guys, What are you doing here?"</p> <p xml:lang="ja">と彼は叫んだ。</p> <p xml:lang="ja">僕は慌てて言った。「別に怪しいものではないんだ。いや、<span xml:lang="en">We are searching Mr.Smith. Do you know something about him?</span></p>
この場合、このXML文書を利用するプログラムはxml:lang属性の情報を手がかりに、禁則処理などのルールを日本語と英語で切り替えることができる。
あるいは、以下のような例も可能だ。
<title>XML勧告の対訳で学ぶ英語教室</title> <p xml:lang="en">The Extensible Markup Language (XML) is a subset of SGML that is completely described in this document. Its goal is to enable generic SGML to be served, received, and processed on the Web in the way that is now possible with HTML. XML has been designed for ease of implementation and for interoperability with both SGML and HTML.</p> <p xml:lang="ja">拡張可能なマーク付け言語(XML)はSGMLのサブセットであって、この標準情報(TR)で、そのすべてを規定する。XMLの目標は、現在のHTMLと同様に、任意の文書型を持つSGML文書をWWW上で配布、受信及び処理できることとする。XMLは実装が容易であって、SGML及びHTMLのどちらに対しても相互運用性を保つ設計がなされている。</p>
この場合も同様に、xml:lang属性を禁則処理などのルールを切り替えるために使用できるが、それだけでなく、XSLTスタイルシートから言語情報を調べて、色やフォントを日本語と英語で切り替えることもできるだろう。
xml:langは地球人のもの
今回は、xml:lang属性という難物を説明したが、これは1つの言語だけで生活している人には極めて分かりにくい機能だろう。現在の日本では、日本語以外は使わなくても問題なく生きていける。その意味で、自分の問題としてピンとくる人は少ないかもしれない。しかし、一方で、いきなり海外勤務を命じられたり、海外向け商品を扱う部署に送り込まれるサラリーマンというのも、いまや珍しい話ではない。もう、海外はエリートだけが行く職場ではないのである。
逆の立場から見てみよう。XMLはI18N(Internationalization)のことを最初から考えて設計されている。xml:lang属性の存在がその証拠の1つだ。だからこそ、生まれてすぐに日本語でもガンガン活用することができ、世界から遅れることなく、日本のXML界は立ち上がったと言える。その意味で、xml:lang属性の存在は、XMLがアメリカ人のものではなく、地球人のものであるという証拠と言える。そういう象徴的な意味として、たとえ日本語しか使わない利用者であっても、xml:lang属性の存在を知っておく価値があるのではないだろうか?
さて、次回は、ちょうど連載の12回目となり、この連載も一区切りとなる。そこで、ここまでの連載を総括し、これまで読んでくださった読者の方々がこれからどこへ向かうことになるのか、XMLの前に広がる可能性を解説してみたい。
それでは次回、また会おう。
■訂正
2001年4月10日 xml:lang属性の内容について、「RFC 1766で規定された書式に従う」との記述を、「RFC 3066で規定された書式に従う」に変更しました。
2001年11月15日 「XMLではxml:lang属性を使う」の内容を、より適切な表現に改めました。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。