無料のVBScriptでXMLプログラミング:VBScriptでXMLプログラミング(1)(3/4 ページ)
DOMを使ってXML文書を操作する
Windows Scripting Host(以下、WSH)は、VBScriptやJScriptといったスクリプトの実行環境として用意されているモジュールです。このWSHが導入されていると、拡張子.vbsや.jsといったファイルにスクリプトを記述しておくことで、簡単なアプリケーションを記述していくことができるようになります。ここでは、VBScriptの利用を中心にして、XMLを利用したアプリケーションの作成方法を順に学んでいくことにしましょう。
単純にXMLをWebブラウザ上に表示してみる
Internet Explorerには、XML文書をブラウザ上に表示させることができます。まずは、今回のターゲットとなるデータ(リスト1)を実際に表示させてみることにしましょう。 すると、画面1のようにブラウザ上に表示されます。
これは、これから操作しようとしている実際のXML文書です。XML文書だけを表示しようとすると、このようにツリー上の構造がそのまま表示されます。これでは、データとしての利用価値はあるかもしれませんが、クライアントとなるユーザーから見たときには何を意味しているのかがよく分かりません。これらを意味あるものとするために、プログラミングを行っていく必要があるのです。
<?xml version="1.0" encoding="utf-8" ?> <books> <item> <title>XML入門-第1巻</title> <price>2500</price> <isbn>1-1234-5678-X</isbn> <authors> <author>西谷 亮</author> </authors> <imgfile>1-1234-5678-X.gif</imgfile> </item> <item> <title>XML入門-第2巻</title> <price>2200</price> <isbn>1-1234-5678-0</isbn> <authors> <author>西谷 亮</author> <author>山田 太郎</author> </authors> <imgfile>1-1234-5678-0.gif</imgfile> </item> <item> <title>XML入門-第3巻</title> <price>3600</price> <isbn>1-1234-5678-1</isbn> <authors> <author>西谷 亮</author> <author>鈴木 次郎</author> </authors> <imgfile>1-1234-5678-1.gif</imgfile> </item> </books>
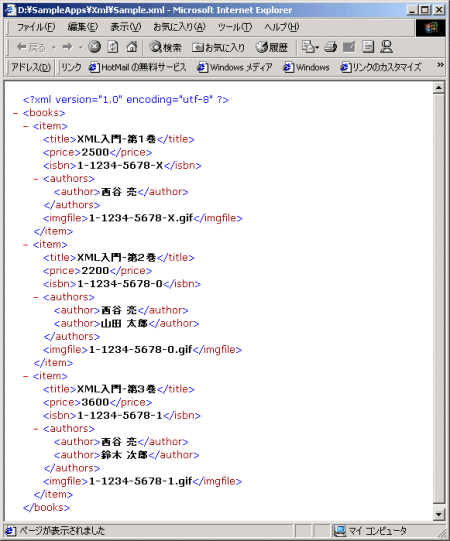 画面1 リスト1をInternet Explorer 5.5で表示
画面1 リスト1をInternet Explorer 5.5で表示XML文書の内容をプログラムから取得する
では、まず、あらかじめ用意したサンプルのデータの内容をプログラムから取り出してみましょう。
XML文書の内容を取得するためには、2つのプログラミング手段が用意されています。1つは、XML DOM(XML Document Object Model)と呼ばれるAPI(Application Programming Interface)、そして、もう1つが、SAX(Simple API for XML)といわれるAPIです。これら双方は、MSXML Parser 3.0において実装されていますので容易に利用することができます。ここでは、DOMによって用意されているAPIを利用して、XML文書の内容を取得していくことにしましょう。なお、DOMを選択するか、SAXを選択するかといった点については、追って解説していきたいと思います。
まずは、XML文書の中にどのような書籍のタイトルがあるのかを表示させることにしましょう。書籍のタイトルは、XML文書(リスト1)の中にtitleというタグによって記述されています。この場合は、以下のようなコードを書いて実行することで実現できます。
なお、コードを記述する際は、メモ帳などのテキストエディタを使用すれば問題ありません。また、完成したら、XML文書と同じディレクトリ上に拡張子vbsというファイル名で保存します。
01 : Dim objDOM, rtResult
02 :
03 : Set objDOM = WScript.CreateObject("MSXML2.DOMDocument")
04 : rtResult = objDOM.load("Sample.xml")
05 : If rtResult = True Then
06 : procDispDatas objDOM.childNodes
07 : End If
08 : Set objDOM = Nothing
09 :
10 : Sub procDispDatas(objNode)
11 : Dim obj
12 : For Each obj In objNode
13 : If obj.nodeType = 3 and obj.parentNode.nodeName = "title" Then
14 : MsgBox obj.parentNode.nodeName & " : " & obj.nodeValue
15 : End If
16 : If obj.hasChildNodes Then
17 : procDispDatas obj.childNodes
18 : End If
19 : Next
20 : End Sub
実際に実行すると、画面2のようなメッセージが表示されます(実行するには、保存した拡張子vbsファイル(この例では、GetTitle.vbs)をマウスでダブルクリックしてください)。これで、XML文書の中から書籍のタイトルにあたるデータだけを取り出すことに成功しました。
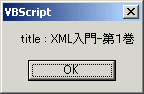 図2 リスト2(GetTitle.vbs)の実行画面
図2 リスト2(GetTitle.vbs)の実行画面では、このコードの内容を順に解説していきます。
1行目:Dim objDOM, rtResult
使用される変数の宣言をしています。WSHでは、この変数の宣言を省略することもできます。
3行目:Set objDOM = WScript.CreateObject("MSXML2.DOMDocument")
DOMのAPIを利用できるようにする準備です。CreateObjectメソッドによってDOMのインターフェイスをメモリ上にロード(インスタンスの生成)しています。この命令の後は、Set文によって指定されている変数(ここでは、objDOM)を利用していくことでDOMのAPIの利用が可能となります。
4行目:rtResult = objDOM.Load("Sample.xml")
5・7行目:If rtResult = True Then ... End If
DOMに実装されているloadメソッドを実行することで、ファイルとして存在しているXML文書を読み取ることができます。ここでは、スクリプトのファイルと同じディレクトリにファイルがあることを想定していますが、http://〜/Data.xmlのように引数を設定することで、インターネット上のXML文書をロードすることができます。また、文字列データとしてXML文書が与えられているときには、loadXMLメソッドを用いて引数を与えると同じようにロードすることができるようになっています。
なお、このメソッドが実行された結果、読み取りが成功したときは、rtResultという変数にTrueの値がセットされます。読み取りに失敗したときは、逆にFalseがセットされますので、5行目の条件分岐で、結果に応じた処理を実行できるようになります。
6行目:procDispDatas objDOM.childNodes
XML文書の読み取り(loadメソッド)が成功しているときに呼び出される関数です。このprocDispDatasという関数は、10行目から実装されているものでDOMのAPIではありません。呼び出す際には、読み取られたXML文書のchildNodeオブジェクトが引数として必要となります。
なお、childNodeオブジェクトとは、子のNodeを取得するために使用されます。XML文書内の木構造を親子関係に見立てているため(XML文書上の枝の節という意味と考えると分かりやすいでしょう)にこのような名称が付けられています。例えば、今回のサンプルXML文書でいうと、itemエレメント(属性)の子としてtitleエレメントやpriceエレメントなどが存在していることになります。なお、この逆を操作するときには、親のNodeを操作するという意味でparentNodeオブジェクトというものが用意されています。詳細なDOMのオブジェクトモデルに関しては、次回紹介する予定です。
8行目:Set objDOM = Nothing
この行は、終了処理のために用意されています。オブジェクト変数に対してNothingを代入することによって、メモリ上に用意されたDOMのインスタンスを開放することができます。
10行目:Sub procDispDatas(objNode)
サブプロシージャ、つまり、関数の定義を行っています。このprocDispDatasという関数では、Nodeオブジェクトが渡されてくることを前提として記述されます。なお、この関数は、6行目で呼び出しているものです。
11行目:Dim obj
この関数の中で使用する変数を宣言しています。
12・19行目:For Each obj In objNode ... Next
For Each...Nextという構文を用いて、Nodeに含まれている要素を順に検査していきます。実行されると、ループが実行されるたびに次の要素へと進んでいきます。この例では、検査するNodeがなくなった時点でこのループから脱出して終了処理が実行されるようになります。
13・15行目:If obj.nodeType = 3 and obj.parentNode.nodeName = "title" Then.. End If
あらかじめ、書籍の名称が含まれているエレメントが「title」であると分かっているので、直接その名称を指定しています。If文の条件としてこのように記述しておくことによって、目的としているデータを確実に取得できます。
なお、nodeTypeというプロパティは、現在アクティブになっているNodeのタイプを指定することができます。
14行目:MsgBox obj.parentNode.nodeName & ":" & obj.parentNode.nodeValue
前述の条件分岐の結果、書籍の名称を取得することがこの段階でできています。内容を確認するためにメッセージボックスを表示させ、その内容を画面上に表示させています。前述の画面イメージは、この行が実行されることによって表示されているものです。
nodeNameやnodeValueといったプロパティは、Nodeの名前(実質上、エレメントの名称)やその値を取得することができるものです。
16・18行目:If obj.hasChildNodes Then ... End If
次の行で再帰呼び出しを行うように実装します。そのためにあらかじめ脱出条件が必要です。ここでは、現在アクティブになっているエレメントに子のエレメントがあるかないかを判断し、その結果によって再帰呼び出しを行うかを判断しています。
hasChildNodesというメソッドは、子のエレメントを持っているか否かを判断するためのメソッドで、Trueが返ってくれば、子のエレメントを持っており、Falseが返ってくれば、持っていないということになります。
17行目:procDispDatas obj.childNodes
子のNodeを持っている場合には、その中にターゲットとしているデータがないかを検査します。この検査処理は、同じこの関数を再帰的に呼び出すことによって実現できます。再帰呼び出しを利用する場合は、無限ループに入らないように脱出条件に注意が必要です。このサンプルでは、子のNodeが存在しなければ呼び出されないように前述のように条件分岐が設定されているので問題ありません。
20行目:End Sub
この関数の終了を宣言しています。
このように記述することで、XML文書の中にあるデータを取得することができるようになります。このコードはWSHの利用を前提に記述されていますが、HTMLにクライアントサイドスクリプトとして記述しておくことで、XML文書の解釈と表示といったことも同様に実行できます。
このサンプルの拡張を行うとすれば
ここで紹介したサンプルアプリケーションの拡張を考えてみましょう。
例えば、XML ドキュメントのすべての内容を取得したいということであれば、13行目に記述された条件文を変更することで可能です。nodeName ="title"としてフィルタをかけてしまっているので、and以下を削除し、以下のようなコードにしてみましょう。
If obj.nodeType = 3 Then ...以下続く
すると、titleエレメントの内容だけではなく、それ以外のエレメントに関しても順に表示されていくことが分かるでしょう。
プログラムからXML文書の内容を取得するためにはこのようなコードを少し記述するだけで簡単に実行することができるようになっています。DOMを使用するときは、図1のように XML文書が木構造になっていることを意識しながらプログラミングしていくことで、その中に含まれているデータへ容易にアクセスしていくことができるようになっています。
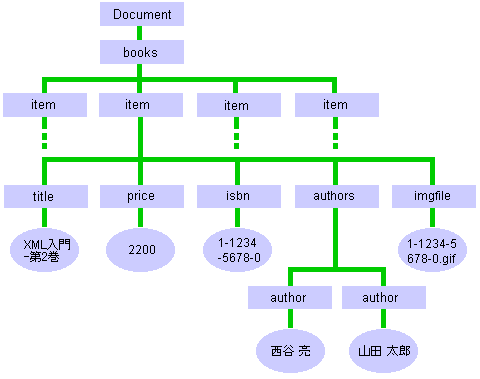 図1 リスト1のXML文書をツリー構造で表現したもの(一部省略)
図1 リスト1のXML文書をツリー構造で表現したもの(一部省略) Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。