第10回 IPパケットの構造とIPフラグメンテーション:基礎から学ぶWindowsネットワーク(3/3 ページ)
「IPフラグメンテーション(IP fragmentation。fragmentとは断片などの意味)」とは、一度に送信することのできない大きなIPパケットを、いくつかに分割して送信するという技術である。IPプロトコルでは最大で64Kbytes(IPヘッダ部分を含んだサイズ)までのパケットを一度に送信できることになっているが、実際にはこのような大きなサイズのIPパケットを1つのパケット(フレーム)で送信することのできる物理ネットワーク媒体はない。例えばイーサネット(および相互互換性を持つ無線LANなど)では最大1500bytesだし、FDDI(光ファイバ)では4352bytesというのが普通である。このように、一度に送信することができるデータのサイズを「MTU(Maximum Transmission Unit)」といい、物理的なネットワーク媒体ごとに固有の値を持っている。
それならば、IPパケットを構築する前に、ネットワーク媒体のMTUサイズに合わせてデータ・サイズを決めるという方法もありそうだが、これは本末転倒であろう。上位層や下位層のプロトコルに依存しないためにネットワークを階層化、独立化したはずなのに、これではせっかくのメリットが損なわれてしまうことになる。常に下位のMTUを意識してネットワーク・パケットを構築したり、プログラムしなければならないからだ。さらに、ルーティング経路の途中にMTUの小さいネットワーク媒体があると、そこから先へ送ることができなくなるという問題もある。またPPPoEのようなプロトコルを利用していると、さらに小さなMTUになる場合もある。
このような問題を解決するため、IPプロトコルには、送信先ネットワークのMTUサイズに合わせて自動的にIPパケットのサイズを調整するという機能が用意されている。それが「IPフラグメンテーション(IPの断片化)」である。
IPフラグメンテーションの原理は簡単である。以下の図のように、IPパケットを送信する場合に、MTUサイズいっぱいになるように元のパケットを分割して送信するだけだ。TCP/IPのプロトコル・スタックでは、システムの起動時などに各インターフェイスのMTUを調べておき(デバイス・ドライバ側から報告するのが普通であるが、MTUを調査するためのプロトコルも定義されている)、そのインターフェイスに送信する場合は、必ずMTUサイズに収まるようにようにパケットを構築する。同じシステムでも、ネットワークのインターフェイスごとにMTUサイズが異なる場合があるので、このMTU属性はインターフェイスごとの属性として内部で保持されている。
MTUのサイズが決まれば、あとはこれに合わせてIPパケットを分割するだけである。IPパケットを受け取ったルータは、そのサイズを調べ、送信先インターフェイスのMTUサイズを超えていないかどうかを確認する。もしMTUサイズよりも大きければ、2つ以上のIPパケットに分割して、順次送信する。分割は各IPパケットのサイズが均等になるようにするわけではなく、通常はなるべくMTUサイズいっぱいのパケットが数多く生成されるように分割される(その方が効率がよい)。例えばサイズ3000bytesのパケットをMTUサイズが2000bytesのネットワークに送出する場合、1500bytesずつ2つに分けるのではなく、2000bytesと1000bytesに分割する(2つ目のパケットにもIPヘッダが付けられるので、実際にはもう少し大きなサイズのパケットになる)。ルーティングの途中でこのようなフラグメンテーションを繰り返し、最終的なあて先のコンピュータには、(MTUの小さなネットワークが途中にあれば)細かく分割されたパケットが届くことになる。
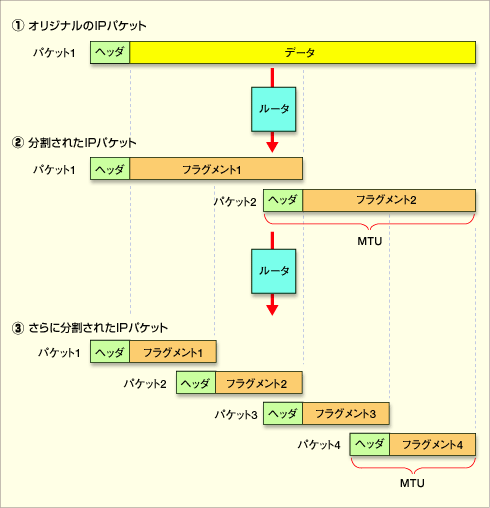 IPフラグメンテーション
IPフラグメンテーション送信先ネットワークのMTUサイズに入りきらないような大きなIPパケットは、図のようにいくつかのフラグメント(断片)に分割されてから送信される。分割されたIPパケットもほかのパケットと同様に、それぞれ独立してルーティングされ、あて先コンピュータにまで届けられる。ただしネットワークの混雑状況などにより、一部のフラグメントの到着時間が入れ替わったり、途中で消失したりするかもしれないが、受信した側ではそれらを考慮してIPパケットの再構成を行う。
IPパケットを分割した場合、分割されたそれぞれのパケットを「フラグメント(fragment。断片)」という。分割するのはデータ部分のみであるが、ヘッダ部分とヘッダのオプション部分は各フラグメント・パケットにもすべてコピーされる(ただしフラグメントされたことが分かるように、一部のヘッダ情報が書き換えられている。詳細は後述)。そのため生成された各フラグメント・パケットは元のIPパケットとほぼ同じように機能する。そして各IPパケットは元と同じようにIPルーティングの対象となり、それぞれが独立して、ルータやネットワークを経由して最終的なあて先コンピュータにまで届けられることになる。一度フラグメント化されたパケットは、例えMTUの大きなネットワークを通過したとしても、ルーティングの途中で再構成されたりはしない。分割されたIPパケットは、分割されたまま最終的なあて先まで「独立して」ルーティングされ、到着することになる。再構成するためにはすべてのパケットの到着を待つ必要があるが、ルータではそのような複雑な処理を実行することなく、あくまでもIPパケットのフォワードのみを処理するだけである。最終的にまた1つにまとめるのは、あて先コンピュータの仕事である。
ここで重要なのは、フラグメント化された各IPパケットは「独立して」ルーティングされるというところにある。一度IPパケットがフラグメント化されると、分割された各パケットは通常の個別のIPパケットと同様に扱われ、お互いに何の関連性もなく、ルーティングの対象となる。そのためネットワークの性質上、各パケットの到着時間や到着順序はまったくばらばらになり、ほかのIPパケットと混ざって順不同で到着するかもしれないし、場合によってはどこかで一部のパケットが消失してしまうかもしれない。だがこれもネットワークの特性上起こりうることであり、IPプロトコルではこのような事態が起こっても問題ないように設計されている(といっても、実際には一部が欠落した場合は、元のIPパケット全体を破棄するだけであるが)。
MTUの最小値
MTUの値はネットワークの媒体によって決まっていると書いたが、ではどんなサイズのMTUでもTCP/IPは正しく機能するかというと、そうではない。フラグメント化されたIPパケットには、データだけでなく、必ずIPヘッダ(のコピー)も付いている。そのため、このサイズよりも小さなMTUしか利用できないとすると、IPパケットそのものを格納することができない。
このような事態を防ぐため、TCP/IPの仕様では、TCP/IPが利用可能な最低限のMTUサイズというものが決められている。この値は、現在では576bytesであるとされている(この値は現在のLAN技術などと照らし合わせるとかなり小さいので、将来はより大きな値に変更されるかもしれない)。576bytesというのは、512bytesのデータにプロトコル・ヘッダ64bytesを加えた値である。この64bytesというサイズは、オプション部も含めたIPヘッダの最大長60bytesにさらに若干の余裕を加えたものとして決められたようだ。つまり、TCP/IPネットワークを構築するための各種ルータやネットワーク機器は、このサイズの最低MTUを保証し、フラグメンテーションを起こすことなく処理できなければならない。逆にいうと、これより大きなサイズのIPパケットは分割されることがあるということでもある。
IPパケットの再構成
フラグメント化されたIPパケットは、フラグメント化された状態のままで、ばらばらにあて先にまで届けられる。これらのフラグメントをすべて集めて元のIPパケットに戻すのは、次図のように、あて先コンピュータの仕事である。
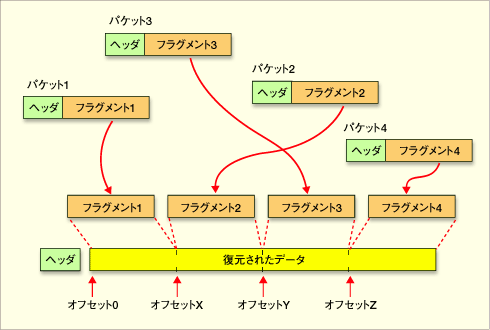 フラグメント化されたパケットの再構成
フラグメント化されたパケットの再構成フラグメント化されたパケットは、フラグメントされた状態のままで最終あて先コンピュータまで届く。そこで元のIPパケットに再構成され、データが取り出されて上位プロトコルへ渡される。各フラグメントのヘッダ内には、オリジナルのIPパケットのうちのどの部分に相当するかの情報が含まれており、それを使って元のパケットを再構成する。しかし一定時間待っても全フラグメントが揃わない場合は、このIPパケット全体が破棄される。
この図では、4つのフラグメント化されたパケットがばらばらに到着した状態を表している。到着順序も順不同であるし、ひょっとしたら一部のパケットが欠落したり、場合によっては重複して到着するかもしれない。
だが到着した各IPパケットのヘッダには、元のIPパケットのうちのどの部分であるかの情報が含まれているため、それを元にしてパケットを再構成することができる。いったん再構成されれば、そこからデータ部分が取り出され、上位のプロトコルへと渡されることになる。
■ID(Identification。識別子)
IDにはIPパケットを送信するたびに(送信側で)異なる値がセットされるが、同じIPパケットを元とするIPフラグメント・パケットは、すべて同じIDをコピーして持っている。そのため受信したコンピュータ側では、同じIDを持つIPパケットをすべて集めれば、オリジナルのIPパケットが再構成できる。ただしID番号だけでは重複する可能性があるので、IPアドレス情報なども組み合わせてユニーク性を確認する。
■フラグメント・フラグ
IPヘッダ中のフラグ・フィールドには、このIPパケットがフラグメントの一部であるかどうかを表すMF(More Fragment)ビットが用意されている。この値が1ならば、後続のIPパケットが存在するので、その到着を待つ必要がある。このMFビットが0ならばれよりも後ろにはデータが存在しないということが分かる。上の図でいえば、フラグメント1、2、3ではMFフラグが1になっているが、最後のフラグメント4ではMFは0となっている。
■フラグメント・オフセット
フラグメント・オフセットは、到着したフラグメント・パケットが、元のIPパケット中のどの位置にあったかを表す。例えばフラグメント・オフセットが「2000(10進数)」だとすると、到着したフラグメントのデータ部分は、分割されていないオリジナルのIPパケットのデータ(ペイロード)部分のうち、2000bytes目からに一致する、という意味になる。先頭のフラグメントの場合はオフセットは0である。なおフラグメントは8bytes単位で分割することになっているので、オフセットとして使用できる値は8ずつ増加する。IPヘッダ中のオフセット・フィールドは13bit幅しかないが、その値を8倍することで、最大で約64Kbytesまでのオフセットを表現できる。例えばフラグメント・オフセットが「2000」なら、実際にはその8分の1である「250」が、フラグメント・オフセット・フィールドにセットされる。
受信したパケットがIPフラグメント・パケットであることが分かれば、それを元にして元のIPパケット全体を再構成する準備を行う。具体的には、IPパケット全体が受信するためのバッファを用意し、パケットを受信するたびに該当するフラグメントの部分を特定して、データを埋め込む。そしてすべてのパケットが揃った時点で上位のプロトコル(TCPやUDP)に引き渡すわけだ。
しかし全部のIPフラグメントが揃わず、一部が欠落したまま一定時間が経過すれば(数十秒程度)、そのIPパケットの再構成は失敗したものとして、すべて破棄する。すでに述べてきたように、IPプロトコルは、受信確認や送信失敗時の再送処理などを行わない軽いプロトコルなので、再構成に失敗してパケット全体を破棄したとしても、送信元に通知したりはしない。このような場合に必要ならば再送処理を行うのは、送信側の上位プロトコルや上位アプリケーションの責任である。
TTL
IPヘッダには、「TTL(Time To Live)」という8bitのフィールドがあるが、これはIPパケットの「寿命」を表すための数値フィールドである。IPパケットを送信するコンピュータは、このフィールドに適当な数値をセットしてからネットワークへ向けて送信を行う。するとこのIPパケットは、そこで指定された寿命の間しか生存できず、それを過ぎると破棄されることになっている。
具体的にはこのTTLは、「ルータを通過できる最大回数」を表す(ここでいう「Time」とは「秒」や「時間」ではなく「回数」という意味)。TTLの初期値はプロトコル・スタックの実装によって異なるが、一般的には255とか128、64などが多いようだ。昔は16とか8などという、いまと比べると非常に少ない数値が使われることもあったが、インターネットが普及した現在では大きな値が使われるのが一般的になっている。
TTLの利用方法は次の図のように非常に単純である。ルータは、IPパケットをフォワード(あるネットワーク・インターフェイスから受信したパケットを別のインターフェイスから再送信すること。詳細は前回を参照)するたびにこのTTLの値を1つ減らし、TTLが0になればIPパケットを「破棄」する。
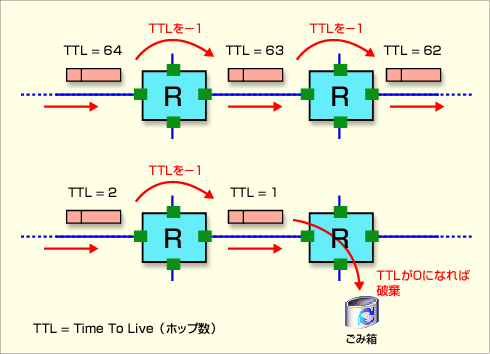 TTLによるパケットの寿命の管理
TTLによるパケットの寿命の管理ネットワークの配線やルーティング・テーブルの設定ミスなどによって、どこかにループが発生したとしても、ルータを通るたびにTTLを1減らすことになるので、ループの途中で必ずTTLが0になり、パケットが破棄されることになる。これによって、IPパケットがいつまでもネットワーク上に残ることを防ぐことができる。だがあまりにも小さ過ぎると(8とか16など)、目的のコンピュータに届く前にパケットが捨てられてしまい、通信ができなくなってしまう。インターネット上でTCP/IPプロトコルを利用するなら、やはり64とかそれ以上の初期値が必要だろう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。