VFSとファイルシステムの基礎技術:Linuxファイルシステム技術解説(1)(2/2 ページ)
Linuxのファイルシステム
Linuxのファイルシステムは、ベースとなる部分をUNIXのVFSによっていることを述べた。VFSは図1のように、アプリケーションと記憶装置であるメディアの間に位置する。VFSはアプリケーションからのファイル操作に関する要求を受け付け、それを関連するローカルファイルシステムごとのAPIに変換する。ローカルファイルシステムは、さらにドライバを経由して実際の記憶媒体を読み書きする。
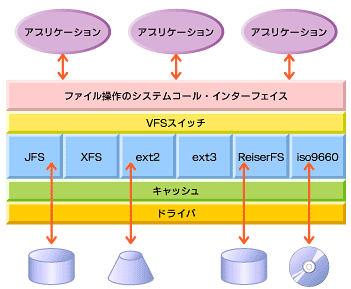 図1 ファイルシステムの位置
図1 ファイルシステムの位置ユーザーにとっては、こうしたVFSでのAPIの変換作業は隠ぺいされているため、単に「ディレクトリ」にある「ファイル」にアクセスするというような意識で媒体のデータを操作できる。つまり、VFSはどのアプリケーションからでも、同じような手順でファイル操作(媒体へのアクセス)が行えるような、単一のインターフェイスを提供している。
さらにVFSは、バックグラウンドでアクセス権の確認や書き込み待ち判断などの汎用的な仕事、キャッシュバッファといったメモリ操作など、ファイル処理に関する一連の操作を行う。また、ドライバやI/Oサブシステムに対しても統一的なインターフェイスを提供している。
VFSによるトランスレーション(変換機能)によって、ユーザーはファイルシステムがext2なのかReiserFSなのかを意識せずに使用できる。例えば、mountコマンドで異なるファイルシステムをシステムのディレクトリツリーの一部として認識させることが可能だ。
VFSオブジェクト
VFSは、統一的なアクセスを提供するために、ファイルシステムの差異を吸収する仕組みを持っている。次に、この仕組みを解説する。解説にあたって、VFSを構成する主なオブジェクトを表にまとめた。
| file_system_type | ローカルファイルシステムを定義する構造体 |
|---|---|
| inode | iノード。ファイルの管理情報を格納する。ファイル種別ごとに異なる操作管理テーブルを持つ |
| super_block | スーパーブロック管理用の構造体 |
| file | ファイルのオープン状態を管理する |
| dentry | ディレクトリエントリ情報を管理する |
| 表 主なVFSオブジェクト | |
ローカルファイルシステムは、システムの起動時にVFSに登録される。このときに「ext2」「ext3」といった「ファイルシステムタイプ」(file_system_type)がVFSに設定される。VFSは、この「ファイルシステムタイプ」の中に設定されている固有の命令をVFSの統一的な命令に置き換える作業を行う。例えば、open()という命令は、ext2_open_file()といったext2固有の命令に変換される。このため、VFSはトランスレータとも呼ばれる。
super_block、inode、dentry、fileなどのオブジェクトは、プロセスとファイルシステムを結び付けたり、ディレクトリやスーパーブロックの管理情報を保持する役割を果たす(これらの解説は後述する)。
iノード
VFSの抽象化の仕組みの基本単位として提供されているのが、「iノード」である。fsckを実行するとiノード情報が表示されるのでご存じの方いると思うが、要するにディスクのインデックスである(iノードはindex nodeの略)。つまり、iノードはファイルとディスクの情報を関連付ける役割を果たす。
iノードは、それぞれが実際の記録媒体であるディスク情報やブロック情報、位置情報を持っており、このiノードによってディスクのジオメトリが一意に識別される。fsckでよく見かける「inodeの整合性が取れなくなったので修正します」というメッセージは、ディスクとノード番号にズレが生じてしまったりした場合に、それを修正する操作を指している。
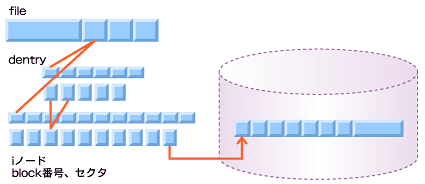 図2 ディスクのジオメトリとiノード
図2 ディスクのジオメトリとiノードiノードは通常、ファイルに対して一意(unique)であり、ファイルが存在する限り同じiノードが利用される。iノードの上限はカーネルによって決められており(/proc/sys/fs/inode-max参照)、file-max数の3〜4倍となっている。これは、標準入力、標準出力、ソケットの作成の際にもiノードが使用されるためである。
ファイルごとにサイズは異なるため、iノードの消費量とディスク使用量は完全には一致しない。小さいファイルを大量に作成するようなシステムでは、iノードを大量に消費する。そのため、iノードが上限に達すると、たとえディスクの使用量が少なくても、新たなファイルが生成できないという事態が生じる。
確認のために、下記の例のようにdfコマンドでディスク使用率とiノードの使用率を確認してみよう。同じシステムでありながら、ディスク使用率とiノードの消費率は数倍の差がある。
$ df |
$ df -i |
iノードを多く使用している場合、iノードのキャッシュの検索が遅くなり、アクセスに時間がかかるといった問題も生じる。ローカルファイルシステムによっては、B*Treeなどによる効率化アルゴリズムを採用することで、検索の高速化を実現している。
また、iノード番号は連続的に振られるため、(1Tbytes超の)大きなファイルシステムでは、iノード番号があふれる可能性がある。この解決策としては、次回に解説するDynamic inodeシステムやextentといった方式が提案されている。バックアップアプリケーションによっては、32bitでしかiノード番号を許可しないものがあり、非常に大きなファイルシステムのファイルを扱えないので注意が必要である。
スーパーブロック
「スーパーブロック」は、1つのファイルシステムについて1つだけ存在し、マウントされたローカルファイルシステムに対する情報を保存している。通常、iノードは書き込みなどの状態が変化すると、その都度現在の状態を示すフラグ(ビット)を更新する。この更新は、効率化のためにディスクにアクセスせずにメモリ上に保持されているスーパーブロックに対して行われる。
これは、信頼性の面で問題がある。例えば、システムをシャットダウンせずにいきなり電源を切ってしまった場合などは、メモリ上のスーパーブロックとディスク上のスーパーブロック情報で不整合が生じる可能性がある。Linuxでは、書き込みが行われたスーパーブロックを定期的にディスクにコピーし、問題が最小限になるような方法を取っている。しかし、電源遮断時の状況によっては、fsckで回復できない致命的な障害となることもある。
ファイルシステムによっては、このスーパーブロックへの更新以外にも、メタデータの保存やトランザクションのコミットなどといった方法でメモリ上のデータとディスク上のデータとの整合性を失わないようなさまざまな試みがなされている。この方法については、今後各ファイルシステムの特徴の部分で解説する。
プロセスとファイルシステム
iノードが実際のディスクに対応し、ブロック番号やセクタ番号を保持していると説明した。しかし、なぜファイルシステムを経由して読み書き操作ができるのか、いまひとつピンとこない方もいるだろう。もう少しファイルシステムの仕組みに立ち入った話を続けよう。
実際にユーザーがiノードを利用するには、どのようにすればよいのだろうか? その答えは図3に示したように、インターフェイスとなるファイルオブジェクトがディレクトリを管理するオブジェクト(dentry object)を操作し、さらにiノードを管理するという構造で、階層的に抽象化された仕組みで実現されている。
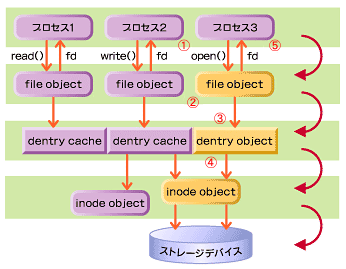 図3 プロセスとiノード間のオブジェクト
図3 プロセスとiノード間のオブジェクト例えば、ユーザー0はエディタなどのアプリケーションを利用してファイルを開いたり、そのファイルに書き込みを行って保存する。このとき、アプリケーションの実行単位であるプロセスは、ファイルに対してopen()、write()、read()といったシステムコールを発行し、カーネルに対してファイル操作を行うためのサービスを要求する(1)。
カーネルはシステムコールを受け付け、その要求に従ってファイルオブジェクトを生成し(2)、それを図中の「fd」(ファイルディスクリプタ)に関連付ける。ファイルオブジェクトはカーネル操作によって、ディレクトリパス情報を持つdentryオブジェクトに関連付けられ(3)、dentryオブジェクトはiノード(ディスクに具体的に結び付けられているビットマップ情報)に関連付けられる(4)。
新しいiノードが参照位置の情報を得られたら、ファイルオブジェクトをインターフェイスとするアドレス情報をポインタとしてプロセスに返す(5)。プロセスはサービスの要求の返答として、ファイルディスクリプタという形でファイルオブジェクトへのポインタを得る。つまり、われわれはファイルディスクリプタを通じて間接的にiノードを操作するのである。
状態の管理
上位のアプリケーションが、複数のオブジェクトを介してiノードを操作していると述べた。iノードはこうしたユーザーの要求に素早く応じることができるように、カーネルのメモリ内に常時確保され管理されている。このようにカーネルメモリ内に確保されたオブジェクトは、通常「キャッシュ」と呼ばれる(コラム「キャッシュ」参照)。
実際に書き込みや読み込みが行われた場合、このiノードに対して書き込みがなされたことを示すフラグ(ビットマップ)が記される。これが「ダーティビット」である。このダーティビットが付けられたiノードは、書き込みがなされている=「汚れた」バッファであり、「ディスクに書き込まれる」ためのキュー(列)である、汚れた(DIRTY)リストにつながれる。
カーネルは、このようなキューを効率化のためにハッシュを先頭とした「双方向リスト」で管理している。キューはそれぞれiノードの状態によってUSED(使用(参照)中)、UNSED(未使用)、DIRTY(書き込み中)の状態で別リストにつながれる。
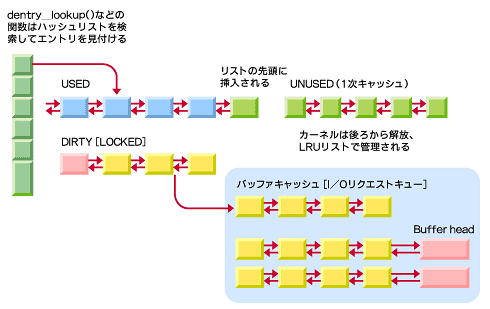 図4 オブジェクトの管理
図4 オブジェクトの管理さらに、汚れた(DIRTY)リストにつながれたデータは、バッファキャッシュとしてI/O待ちのI/Oリクエストキューに入れられる(図中黄色い部分)。最終的に、このI/O待ちのキューに入れられたiノードは、順次対応するディスクブロックに書き込まれる。書き込みが終了したリストは使用(USED)に戻され、参照が終了したら未使用(UNUSED)に入れられて、適当な時期に解放される。このように、iノードオブジェクトはVFS内の状態遷移で表すことができる。
コラム キャッシュ
「キャッシュ」は本来、一度呼び出したデータをメモリ上に保存することで、次にそのデータを利用する際に高速処理するための機能である。ファイルシステムでは特に、ディスクに保存された情報をカーネルがメモリに置く仕組みとして理解される。iノードなどのVFSオブジェクトは、キャッシュとしてカーネルのメモリに常時確保されている。
キャッシュの量は常時変化する。その統計情報が/proc以下に記されている。/proc/meminfoには、カーネルが現在確保しているメモリオブジェクトがcached(オブジェクトの内訳は/proc/slabinfoに表示)、I/O用に確保されているメモリがbuffersとして表示される。
cat /proc/meminfo |
# cat /proc/slabinfo
signal_act 119 126 1344 40 42 1 |
|
| カーネル内で使用されているメモリオブジェクトの内訳 slabinfo:スタブアロケーション方式で確保されているメモリ 赤枠内はファイル関係のキャッシュ 赤字は、iノードキャッシュとディレクトリエントリのキャッシュ |
非同期処理
アプリケーション側で行われた書き込み操作などは、実際にはカーネルのキャッシュに対して行われる。カーネルはユーザーの書き込み要求に対しては、メモリに「書き込んだ」というビットフラグを立ててすぐにリターンを返す。この書き込み要求はキャッシュバッファに蓄えられて、updateデーモンが定期的にディスクに書き込む(フラッシュ)。
カーネル内部の処理としては、ビットの付いたデータをDIRTYバッファとしてキャッシュに保存し、バックグラウンドでバスの転送速度に合わせてデータディスクに転送する。読み込み時は、ディスクから読み込む場合は非常に時間がかかるので、一度読み込んだものをキャッシュに置いておき、そこから読み込むという方法が取られる。
初めに述べたように、ディスクの書き込み速度はメモリの書き込み速度に対して約100万倍遅い。遅延をユーザーから隠ぺいし、CPUの処理能力を最大限に活用するための仕組みを持つことで、ユーザーのレスポンスタイムが向上するという成果を得た。しかし、これは同時にリスクを背負うことでもあった。
つまり、キャッシュ(RAM)に置いてあるデータは、揮発性の情報であり電源を遮断すると同時に消えてしまうのである。これを防ぐために、updateデーモンがディスクに定期的にフラッシュするのであるが、ディスクにバッファをフラッシュする前にシステムダウンが発生すると、バッファに蓄えられていたデータを損失してしまう。最悪の場合は、メタデータ(ファイルの管理情報)まで損失し、ファイルシステムの破壊へとつながることもある。
VFSを中心としたカーネルのファイル管理部分は汎用的に作られていることが多く、この課題は個々のファイルシステムがジャーナリングシステムの導入などにより管理能力を高めることで解決が図られている。
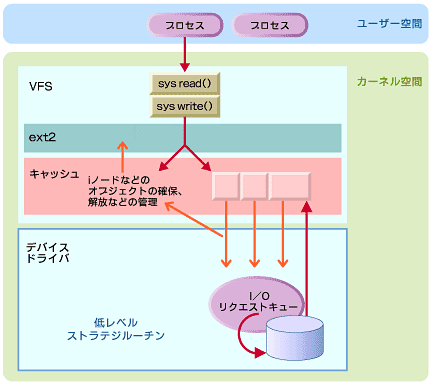 図5 書き込み時の流れ
図5 書き込み時の流れ図5は、こうした非同期処理の全体の流れを示している。ここでは、ext2を例にして流れを確認しよう。
アプリケーションがread()、write()などのシステムコールを発行すると、カーネルはカーネル内のシステムコールであるsys_read()、sys_write()を呼び出す。これらはさらに、VFSの機能であるトランスレーション(前出)によって、ext2固有の関数に置き換えられる。
さらに、ext2はキャッシュにたまったデータを、固有の命令を使用して対応するブロックに転送する。転送が完了すると、割り込み命令が発行される。それによって起動されたドライバの低レベルなストラテジルーチンがディスクコントローラに適切な命令を発行し、I/Oリクエストキューにたまったデータを順次処理する。
高レベル、低レベルな呼び出しの処理は、要求を発行した直後に処理を終了させることができるので、この時点で上位のアプリケーションは次の操作に移ることができる。このように、カーネルはVFSを通じて一連の操作を非同期で行っている。
コラム ページキャッシュとバッファキャッシュ
Linuxのバッファキャッシュは主にブロック型デバイスのI/O操作に使用されるキャッシュ、ページキャッシュはプロセス側から見てCPUの仮想アドレス空間を共有するキャッシュとされている。つまり、プロセスのインターフェイスとなるページ機構のキャッシュが「ページキャッシュ」、I/Oに近い部分が「バッファキャッシュ」と大まかに分類できる。
カーネル2.2では、伝統的に読み込みは「ページキャッシュ」、書き込みは「バッファキャッシュ」という2つの方針が取られてきたが、2.4からは読み込み/書き込みともに「ページキャッシュ」→「バッファキャッシュ」という流れに統合された。これがI/Oサブシステムの基本的なパフォーマンスを向上させたといわれる。
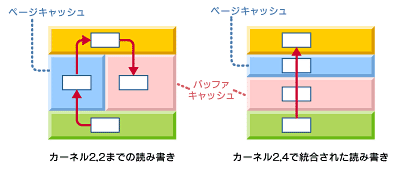 図6 カーネル2.2とカーネル2.4のページキャッシュとバッファキャッシュ
図6 カーネル2.2とカーネル2.4のページキャッシュとバッファキャッシュ今回は、主にカーネル内のファイルシステムの基礎となる仕組みについて述べた。次回は、ジャーナリングやB-Treeなど、現在のファイルシステムで主に使用されている手法を取り上げ、データ保持のための問題を解決し、効率的な管理を行うためのファイルシステムの仕組みについて解説する。
カーネル2.4から、Linuxは本格的にエンタープライズを意識したOSとしての機能を備えるようになった。その特徴の1つがファイルシステムの信頼性である。Linuxの場合、当初に実装されたext2からジャーナリングファイルシステムであるext3やReiserFS、そして商用ファイルシステムとして発展してきたJFSやXFSが取り込まれ、複数のファイルシステムが選択できるようになっている。
本連載は、これらのファイルシステムの違いを把握し、ファイルシステムを選択するための指針となるような情報を提供する。
関連記事
- 連載:Linux Kernel Watch(連載中)
Linuxカーネル開発の現場ではさまざまな提案や議論が交わされています。その中からいくつかのトピックをピックアップしてお伝えします - 連載:Linuxファイルシステム技術解説
ファイルシステムにはそれぞれ特性がある。本連載では、基礎技術から各ファイルシステムの特徴、パフォーマンスを検証する - 特集:全貌を現したLinuxカーネル2.6[第1章] エンタープライズ向けに刷新されたカーネル・コア
ついに全貌が明らかになったカーネル2.6。6月に正式リリースされる予定の次期安定版カーネルの改良点や新機能を詳しく解説する - 特集:/procによるLinuxチューニング[前編] /procで理解するOSの状態
Linuxの状態確認や挙動の変更で重要なのが/procファイルシステムである。/procの概念や/procを利用したOSの状態確認方法を解説する - 特集:仮想OS「User Mode Linux」活用法
Linux上で仮想的なLinuxを動かすUMLの仕組みからインストール/管理方法やIPv6などに対応させるカーネル構築までを徹底解説 - Linuxのカーネルメンテナは柔軟なシステム カーネルメンテナが語るコミュニティとIA-64 Linux
IA-64 LinuxのカーネルメンテナであるBjorn Helgaas氏。同氏にLinuxカーネルの開発体制などについて伺った
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。