Eclipseでファイル操作の理解を深める:EclipseでJavaに強くなる(7)(1/3 ページ)
前回はコンピュータで数値、文字をどのように表現しているかについて理解しました。今回はこれらの値をファイルから読み込んだり、ファイルへ書き出したりする方法について理解しましょう。ファイル操作の基本から、バイトストリームと文字ストリームの違い、プリミティブデータ値のファイル入出力、文字符号化を意識した文字データのファイル入出力といった事項について解説します。
ファイル操作
カンマで区切って保存したCSVファイルから計算に使用するデータを読み込んだり、計算した結果をファイルへ保存するといったプログラムが必要になることはよくあります。こういった処理を実現するためには、ファイルの読み込み、ファイルへの書き込みといったファイル操作をする必要があります。今回は、Javaではどうやってファイル操作を実現するのか解説します。
Javaにはjava.io.Fileというクラスが用意されています。このクラスはファイルシステムでサポートされるファイルとフォルダ(ディレクトリ)の両方を表現するように設計されています。new演算子によってFileクラスから生成されるFileオブジェクトは、ファイルシステム上のファイルそのものではありませんから、Fileオブジェクトが生成されても実際にファイルシステム上のファイルが作成されるわけではないという点には注意してください。
Fileクラスにはファイルを操作するに当たって便利なメソッドがあります。ファイルもしくはフォルダがファイルシステム上に存在していることを確認するためにはexistsメソッドを使います。ファイルを新規作成する場合にはcreateNewFileメソッドを使い、フォルダを新規作成する場合にはmkdirメソッドを使います。使用しているFileオブジェクトと対応するものがファイルかフォルダかを判定するには、isFileメソッド、isDirectoryメソッドを使います。削除する場合は、ファイルとフォルダの区別はなくdeleteメソッドを使います。これらのメソッドの動作を確認するプログラムは次のようになります。なお、完全なサンプルプログラムはSample710.javaとして別途表示します。ほかのサンプルプログラムについても同様に完全なものは別途表示します。
// sample.directoryを表現するFileオブジェクトを生成
// 実際のファイルシステム上にsample.directoryが作成されるわけではない
File d = new File("sample.directory");
// sample.directoryが存在していなくて、これが作成できたときに、dの情報を表示
if (!d.exists() && d.mkdir()) {
System.out.println("d.isDirectory():"+d.isDirectory());
System.out.println("d.getPath():"+d.getPath());
(略)
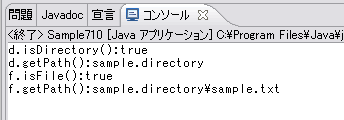 実行結果1
実行結果1基本的なファイル操作としては、作成(create)、削除(delete)、使用開始(open)、使用終了(close)、読み込み(read)、書き出し(write)という6つの操作があります。このうち、作成に対応するcreateNewFileメソッドとmkdirメソッド、削除に対応するdeleteメソッドについてはすでに見ました。残りの4つの操作については、Fileと対応するストリームオブジェクトを用意して行います。ストリームの基本については「第2回 EclipseでJavaの入出力を理解する」で解説しました。
Fileオブジェクトを使ったストリームオブジェクトをnew演算子で生成すると、ファイルの使用開始となります。ストリームオブジェクトのcloseメソッドを使うことによって、ファイルの使用終了になります。データの読み込みにはreadメソッド、データの書き出しにはwriteメソッドを使います。flushメソッドはデータを完全に書き出す効果があります。エラー処理と例外処理を考慮せずにファイル操作に注目してプログラムを作成すると次のようになります。最初の4行でsample.txtファイルへ「abcdefg」という文字列を書き込んでいます。残りの6行でsample.txtファイルから文字列を読み込んでコンソール画面へ出力しています。この結果、コンソール画面には「abcdefg」が出力されます。なお、例外処理も含めた場合のサンプルプログラムはSample720.javaとして示します。ファイルを操作する場合には、「第3回 EclipseでJavaの例外を理解する」や「第4回 Javaの例外テクニックを知る」で説明したとおり、ファイルの使用終了を確実に行い、リソースを解放することを忘れないようにしましょう。
Writer writer = new FileWriter(new File("sample.txt"));
writer.write("abcdefg");
writer.flush();
writer.close();
Reader reader = new FileReader(new File("sample.txt"));
int c;
while ((c = reader.read()) != -1) {
System.out.print((char)c);
}
reader.close();
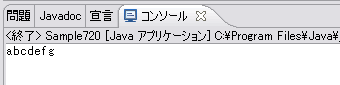 実行結果2
実行結果2ここで、データ型を考えると、文字データをint型の変数へ代入して、コンソール出力時にchar型へ型変換(キャスト)をしているのは不思議な感じがするかもしれません。しかし、データの終了を表す値は?1であること、Javaの内部では文字データは符号なしの整数値である16ビットのUnicodeで基本的に表現されることを考え合わせると、これらの値を表現できる32ビットのint型を返すようにreadメソッドが設計されているのは納得できるはずです。
コラム
Java2 SE 5.0 からはUnicode 4.0のサポートにより、「補助文字」といわれる16ビットでは単純に表現できない文字も扱えるようになりました。この影響により、自作アプリケーションで「補助文字」も対象とするプログラムを作成する場合には、文字を表すための型としてはchar型の配列、java.lang.Stringクラスのようなjava.lang.CharSequenceインターフェイスを実装するクラスを使う必要があります。このため、Java2 SE 5.0では、public String(int[] codePoints, int offset, int count)というコンストラクタがjava.lang.Stringクラスに新しく導入されたり、java.lang.StringBufferクラスのpublic appendCodePoint(int codePoint)メソッドやjava.lang.Characterクラスのpublic static int toChars(int codePoint, char[] dst, int dstIndex)メソッドなどが追加されています。つまり、Java2 SE 1.4までのように、char型の変数は1つの文字データを表すという前提でプログラムは記述できなくなってしまったのです。とはいっても、文字を扱うに当たって、java.lang.String型、java.lang.StringBuffer型などを使っている分には基本的に気にすることはありません。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。