Eclipseで文字符号化の理解を深める:EclipseでJavaに強くなる(6)(1/3 ページ)
コンピュータは0と1しか理解できないため、文字をそのまま使うことはできません。そこで普通は、文字に数値を割り当てることによりコンピュータで利用できるようにしています。各文字を数値で表現するためには文字符号化を行います。実際の文字符号化は奥が深く難しいのですが、正しく文字を処理するプログラムを作成するには、これを避けて通ることはできません。基本となる概念自体はけっして難しくありませんので、それを理解しておきましょう。
符号化文字集合と文字符号化方式
文字がコンピュータでどのように表現されているのかは、文字符号化を理解できればわかるようになります。文字符号化を理解するためには、符号化文字集合(code character set)と文字符号化方式(character encoding scheme)について理解する必要があります。これらについて、順番に解説をします。
符号化文字集合
まず、コンピュータで文字を使用するためには、対象とする文字を決める必要があります。この文字集合(character set)を決めたら、各文字に対して数値を割り当てます。この数値を割り当てられた文字の集合を符号化文字集合といいます。計算機であるコンピュータでは文字そのものをそのまま扱うことができませんから、数値(code)を割り当てることによって計算対象とすることができるようになるのです。
よく知られている符号化文字集合としてはASCII(American Standard Code for Information Interchange)があります。ISOの規格には、これと互換性があるISO646の国際基準版(International Reference Version, IRV)があります。この符号化文字集合には、Aやbといったアルファベットの大文字小文字、1や2といった数字、@や#などの記号文字、改行やタブを表す制御文字が含まれています。含まれる文字の数が128文字以内に収まるので、7ビットで対象とするすべての文字を表現することができます。
どの文字にどの数値が割り当てられているかを調べるプログラムとしてSample610クラスを作成して実行してみましょう。ただし、ASCIIに含まれるすべての文字を表示するとプログラムが複雑になりますから、一部だけを対象とします。
import java.io.UnsupportedEncodingException;
import java.text.DecimalFormat;
import java.text.NumberFormat;
public class Sample610 {
public static void main(String[] args) {
try {
NumberFormat nf = new DecimalFormat("000 ");
byte[] bs = new byte[1];
for (int code=32 ; code<127 ; code++) {
if (code%8 == 0) {
System.out.println("");
}
bs[0] = (byte)code;
String s;
s = new String(bs, "US-ASCII");
System.out.print(s+":"+nf.format(code));
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
Sample610クラスのプログラムで注目してもらいたいのは、codeの値から文字列を表現するString型オブジェクトを生成している点です。String型オブジェクトの生成をするにあたっては、byte型配列と文字符号化名(JavaのAPIリファレンスでの文字セット名)をコンストラクタへ指定する方法を使っています。文字符号化名には、ASCIIの符号化文字集合を計算対象としている場合は「US-ASCII」を指定します。この処理により、ある数値と対応するASCII文字のString型オブジェクトを取得することができます。参考までに、指定できる文字符号化名はRFC 2278: IANA Charset Registration Procedures(http://ietf.org/rfc/rfc2278.txt)の規則に準拠しています。
これを使って、十進数値32から126までの数値と対応するASCII文字の一覧を表示しています。なお、表示をきれいにするために8文字ごとに改行を入れたり、3桁表示をするためにjava.text.DecimalFormatを使っています。また、java.io.UnsupportedEncodingExceptionのキャッチをしていますが、これはString型オブジェクトの生成時にコンストラクタへサポートされていない文字符号化名を指定してしまった場合への対応になります。
ここで日本語版Microsoft Windows XPで動作するEclipse上で、ASCIIの文字で表示するためには準備が必要です。
- [ウィンドウ]→[設定]→[外観]→[色とフォント]を選びます。
- [テキスト・フォント]を指定します。
- [変更]ボタンをクリックしてフォント選択ダイアログを表示します。
- 現在設定されている値をメモします。
- フォント名に[Courie]を指定して[OK]ボタンをクリックします。
- [色とフォント]ダイアログに戻るので、そこで[適用]ボタンをクリックします。
以上の準備ができたらEclipseで実行します。すると、次のような結果がEclipseのコンソールに表示されます。実行が終わったら[テキスト・フォント]の設定を元へ戻すのを忘れないようにしましょう。
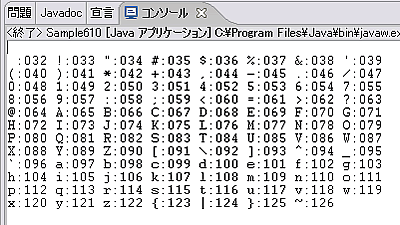
または、Eclipseで実行するのではなく、コマンドプロンプトを起動してからUSモードへ切り替えてからプログラムを実行するという方法もあります。ここではSample610クラスをC:\eclipse\workspace\Sampleのディレクトリと対応するSampleプロジェクトで作成した場合の例を示しています。
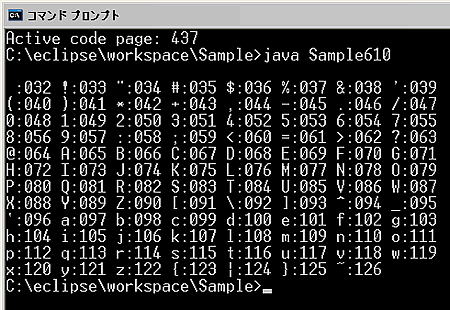
この結果から48から57の数値に数字の0から9が対応していることや、65から90の数値に英大文字が対応していることがわかります。
ASCIIは基本中の基本ですが、ウムラウトやアクセント付きの文字が含まれていません。こういったラテン文字系用の符号化文字集合としては8ビットで文字を表現するISO8859があります。ISO8859にはいくつかの種類がありますが、その1つであるISO8859-1はHTMLやHTTP関係でよく見かけます。
次に、日本語でよく使われる符号化文字集合ですが、これはJIS(日本工業規格)によって定められています。基本としては、7ビットで表現されるローマ字と8ビットで表現されるカタカナが含まれるJIS X 0201があります。ローマ字はISO646を基に作成されたためほとんどの文字はASCIIと同じですが、「REVERSE SOLIDUS(\の幅が小さいもの)」は「YEN SIGN(¥)」へ、「TILDE(˜)」は「OVERLINE(¯)」へ置き換わっているという違いがあります。
ひらがな、カタカナ、数字、英字、よく使われる漢字を含む符号化文字集合としては、JIS X 0208といった規格があります。これには日本語の第一水準、第二水準で規定されている文字が含まれていて、16ビットで文字を表現しています。なお、各文字に割り当てられている数値は区点コードと呼ばれています。上位8ビットで区コードを表し、下位8ビットで点コードを表します。ひとつの区には94文字が含まれていて、これが94区あります。例えば、区点コードの「0402(16)」は4区の2点を意味し、これには「あ」が対応しています。なお、JIS X 0208-1997のように年号つきで正確に表すこともあります。
ちなみに、JIS X 0201に含まれるローマ字とカタカナはいわゆる半角文字になります。JIS X 0208に含まれる文字はいわゆる全角文字になります。また、JIS X 0208には①のようないわゆる機種依存文字は含まれていません。
コラム
JIS X 0201のローマ字日本語版Windows XPを使っている場合、準備をせずにSample610クラスをEclipseで実行すると、結果は次のようになります。結果が微妙に違っているのがわかるでしょうか。これは、日本語版Windows XPではASCIIではなくJIS X 0201のローマ字の符号化文字集合が使われているために起きています。
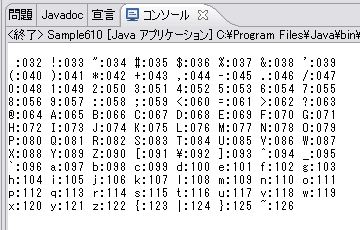
ASCIIでは92が割り当てられているのは「REVERSE SOLIDUS(\の幅が小さいもの)」ですが、JIS X 0201のローマ字では「YEN SIGN(¥)」なので、こちらが表示されています。しかし、JIS X 0201のローマ字では126が割り当てられているのは「OVERLINE(¯)」のはずですが、「TILDE(˜)」が表示されています。この文字だけは「TILDE(˜)」を表示しても良いという規格であるJIS X 0201-1997付属書2があり、それが適用されているのでしょう。
文字符号化方式
符号化文字集合によってコンピュータで対象とする文字と対応する数値の組み合わせが決まるのですが、日本語の場合にはその数値がそのまま使われることはほとんどなく、コンピュータでこれらを効率良く扱うために、色々な文字符号化方式(character encoding scheme)が考えだされて使われています。
一方、ASCIIのように単純な符号化文字集合の場合は、単純に「文字と対応する数値」をそのまま使うという文字符号化方式を使うことができます。すると、例えば「ABC」という文字列を表現するバイト列は「65 66 67」となります。実際にプログラムを使って確認をしてみましょう。
import java.io.UnsupportedEncodingException;
import java.text.DecimalFormat;
import java.text.NumberFormat;
public class Sample620 {
public static void main(String[] args) {
NumberFormat nf = new DecimalFormat("000 ");
try {
String s = new String("ABC");
byte[] bs = s.getBytes("US-ASCII");
for (int i=0 ; i<bs.length ; i++) {
System.out.print(nf.format(bs[i]));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
今度はSample610とは逆で、先にString型オブジェクトを生成してから、byte型配列を取得して表示しています。byte型配列を取得するにあたっては、Stringクラスのメソッドで文字符号化名を引数としてとるgetBytesメソッドを使っています。実行結果は次のようになり、確かに「ABC」という文字列を表現するバイト列は「65 66 67」となっていることがわかります。
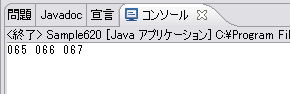
それでは次に、符号化文字集合と文字符号化方式の関係を理解するために、日本語でよく使われる文字符号化方式のひとつであるISO-2022-JPを見てみましょう。これはJIS X 0208:1997付属書2やRFC 1468で規定されています。また、ISO 2022で定められている7ビットで文字を表現するための符号化方式を使っています。
詳しく説明をする前に、この文字符号化方式を使った場合に、「あいうABC」という文字列がどんなバイト列で表現されているのかをプログラムを使って調べてみましょう。基本的にはSample620と同じプログラムですが、文字列sの値を「あいうABC」とし、StringクラスのgetBytesメソッドへは「US-ASCII」の代わりに「ISO-2022-JP」という文字符号化名を指定する点が違います。
import java.io.UnsupportedEncodingException;
import java.text.DecimalFormat;
import java.text.NumberFormat;
public class Sample621 {
public static void main(String[] args) {
NumberFormat nf = new DecimalFormat("000 ");
try {
String s = new String("あいうABC");
byte[] bs = s.getBytes("ISO-2022-JP");
for (int i=0 ; i<bs.length ; i++) {
System.out.print(nf.format(bs[i]));
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
実行結果を見ると、次のように15バイト使っていることがわかります。これまでの符号化文字集合についての説明を単純にあてはめると、「あいう」で6バイト(16ビットの3倍)、「ABC」で3バイト(8ビットの2倍)、合計9バイトあれば足りるはずですが、6バイトも余計に使っています。

実はISO-2022-JPでは、エスケープシーケンスという特別なバイト列を使うことにより、処理対象の符号化文字集合を切り替えるようになっています。ISO-2022-JPでは符号化文字集合としてASCII、JIS X 0201-1976のローマ字、JIS X 0208-1978、JIS X 0208-1983を対象としています。これらの各集合ごとにエスケープシーケンスが決まっています。対象とするすべての文字を7ビットで符号化するという要求に応えるために、このようになっています。ただし、文字を7ビットで表現していますが、処理単位は8ビットである点には注意が必要です。
最初の「027 036 066」は後に続くバイト列はJIS X 0208-1983に含まれる文字であることを意味するエスケープシーケンスです。次に続く「036 034 036 036 036 038」は「あいう」を表しています。ここで、区コード、点コードを表す値には32を加算して符号化がされています。従って、各バイトの値から32を引き算することにより、区点コードの値を得ることができます。最初の2バイト「036 034」について確認すると、各バイトから32を引き算すると確かに「あ」の区点コード「0402(16)」と一致していることがわかります。
続いて、「027 040 066」というバイト列がありますが、これは後に続くバイト列はASCIIに含まれる文字であることを意味するエスケープシーケンスになります。Sample620で出力した「ABC」と対応するバイト列「065 066 067」が続いていることが確認できます。整理すると次の図のようになります。
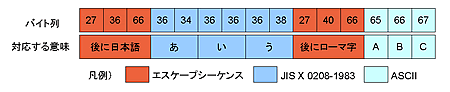
以上、説明したことからわかるように、対象とする符号化文字集合と文字符号化方式の組み合わせにより、どのように文字符号化がされるか、ということが決まります。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。