パーティショニングとデータ圧縮を併用するメリット:Oracleパーティショニング実践講座(5)(3/3 ページ)
データ圧縮とパーティショニング併用の検証結果
それでは実際の検索への影響を確認してみましょう。今回の検証では、図4のように圧縮された表に対するSQL実行時間は、非パーティショニングの場合もパーティショニングの場合も20%程度向上しており、データ圧縮による効果が確認できました。ただ、SQLでアクセスするブロックは圧縮率と同等程度の効果が出ていますが、その効果がSQL実行時間に反映されていないことも分かります。
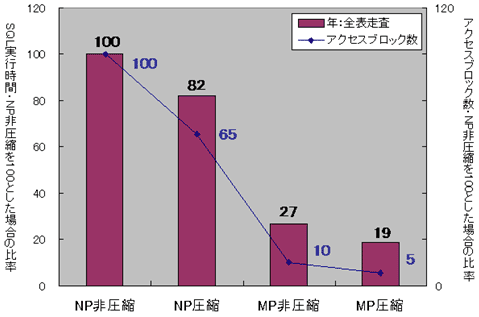 図4 ある特定の年の全商品の売上実績表を検索した場合の圧縮効果
図4 ある特定の年の全商品の売上実績表を検索した場合の圧縮効果図5は、図4のSQL実行時のCPU使用率を表したグラフです。データ圧縮を実施した場合の方がCPUリソースの使用率が高くなっていることが分かります。圧縮されたブロックからデータを取り出す際に少なからずCPUリソースを消費しており、この影響がアクセスブロック減少の効果を打ち消していたのではないでしょうか。
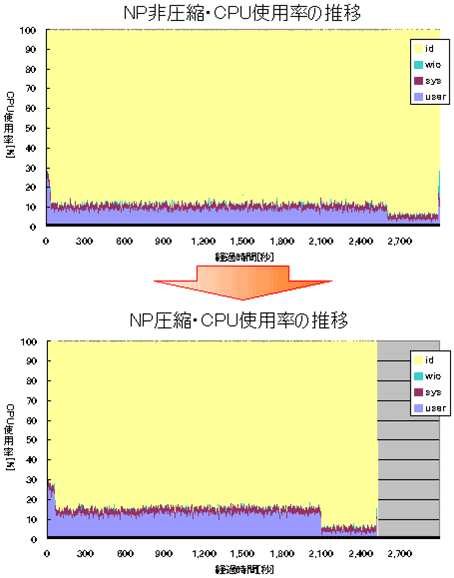 図5 データ圧縮時のCPUリソースの使用率
図5 データ圧縮時のCPUリソースの使用率以上のように、圧縮した表を検索する場合、圧縮されたブロックを解凍するために使用されるCPU負荷は若干増えるものの、圧縮によるアクセスブロックの減少効果が高くSQL実行時間が短縮されることが確認できました。
また、データ圧縮はパーティションとの併用により、
- 圧縮時の一時的に増加する領域問題の解消
- メンテナンス時間の軽減
- 更新が発生するパーティションと過去データを保持するパーティションの分割によるオンライン業務での利用が可能
といった効果が得られます。
連載のおわりに
全5回にわたって大規模データを取り扱うために、パーティショニング、パラレル、データ圧縮の機能について、その特徴と有効性について紹介しましたが、いかがだったでしょうか。
パーティショニングは大規模データだけではなく小規模なデータ量でも効果を発揮すること、パラレル処理は大規模データへのアクセスでサーバリソース(CPU、メモリ、ディスクI/O)に余裕がある場合に、データ圧縮は全表走査や範囲走査といった多くのブロックにアクセスする場合に効果を発揮することが分かりました。また、図6のようにそれぞれを組み合わせて利用することで相乗効果を発揮します。
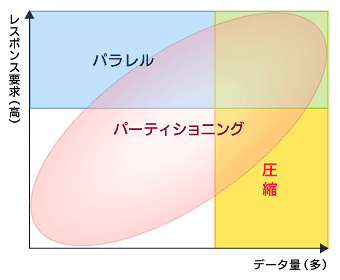 図6 パーティショニング、パラレル、圧縮の関係
図6 パーティショニング、パラレル、圧縮の関係本連載が皆さんのOracleデータベースを構築するうえでの一助になれば幸いです。(連載完)
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。