いまさら聞けない「Webブラウザ」超入門:いまさら聞けないリッチクライアント技術(11)(3/3 ページ)
Webページを表示するまで
Webページが表示されるまでに、WebブラウザがHTMLファイルを読み取ってから表示するまで、3つのステップがあります。
■(1)HTMLファイルの属性を解析(HTMLパーサー)
まずはWebブラウザが情報の属性を解析します。Webページは基本的にHTMLで書かれたファイルです。HTMLはHyperText Markup Language(ハイパーテキストマークアップラングエージ)の略です。
「ハイパーテキスト」は一言でまとめると文章と文章を結び付ける「リンク」のことで、「マークアアップランゲージ」は「文章構造の指定」を意味します。もともと「マークアップ」は印刷用語で「組版指示」という意味です。「ここは大きな見出し」とか「ここは本文なのでフォントはこの大きさ」という属性の指示を与えていきます。
いま皆さんが見ているこのページも、Webブラウザの[表示]→[ソース]から選べば、HTMLのソースが直接見られますので、どんな情報が文章構造として書かれていたり、リンクされたりしているのか確認してみましょう。
![画面7 [表示]→[ソース]から選べば以下のようなHTMLのソースコードが見られる](https://image.itmedia.co.jp/ait/articles/0804/14/r20gamen05s.jpg) 画面7 [表示]→[ソース]から選べば以下のようなHTMLのソースコードが見られる
画面7 [表示]→[ソース]から選べば以下のようなHTMLのソースコードが見られる!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html lang="ja"> <head> <title>リッチクライアント & 帳票 − @IT</title> <meta http-equiv="Content-Type" content="text/html;CHARSET=SHIFT_JIS"> <meta http-equiv="content-script-type" content="text/javascript"> <meta http-equiv="content-style-type" content="text/css"> <meta http-equiv="Set-Cookie" content="cookie=set; path=/"> <meta name="description" content="リッチクライアント、帳票テクノロジの総合情報フォーラム。魅力的で直感的なUI開発の情報が満載"> <meta name="keywords" content="Ajax,JavaScript,Flash,Flex,Adobe AIR,Silverlight,Aptana,Firebug,Webオーサリングツール,Web2.0,マッシュアップ,リッチクライアント,RIA,Laszlo,Curl,帳票,PDF,Webデザイン,ユーザーインターフェイス"> <script type="text/javascript" src="/javascript/newmark.js"></script> <link rel="stylesheet" href="/stylesheet/ftop.css" type="text/css" media="all"> <link rel="stylesheet" href="/fwcr/stylesheet/fwcr.css" type="text/css" media="all"> <link rel="alternate" type="application/rss+xml" title="@IT RSS 0.91" href="http://www.atmarkit.co.jp/rss/rss091.xml"> <link rel="alternate" type="application/rss+xml" title="@IT RSS 1.0" href="http://www.atmarkit.co.jp/rss/rss2dc.xml"> <link rel="alternate" type="application/rss+xml" title="@IT RSS 2.0" href="http://www.atmarkit.co.jp/rss/rss.xml"> </head> <body> …… ……
HTMLファイルを読み込んだWebブラウザは、きちんとHTMLの文法に沿って書かれているかチェックをしながら本文・見出し、脚注や画像といった要素を解析しています。このHTMLを解析するパートを「HTMLパーサー」と呼びます。
パーサーは「parse」(パース)に「er」が付いて擬人化したもので、parseは「文法・構文を解剖する」という意味です。余談になりますが、parseはHTMLだけでなく、XMLやJavaScriptといったほかの言語に対しても利用します。
 図2 パーシング(解析)→整理→レンダリング(表示)
図2 パーシング(解析)→整理→レンダリング(表示)■(2)解析したデータを整理する
Webページが表示されるまでのWebブラウザの2つめのステップは、解析したデータを整理することです。HTMLを解析したデータは、要素ごとに分類されてWebブラウザ内に取り込まれます。
■(3)画面に表示する(レンダリング)
Webページが表示されるまでのWebブラウザの3つめの最後のステップは、見出しや本文の大きさや位置、画像を、取り込んだデータのとおりに画面に表示(レンダリング・rendering)します。
どんなファイルが読み取れるの
では、Webブラウザには読み取れる情報とそうでない情報があるのでしょうか。
HTMLファイルには、ファイル内にリンクとして動画や画像が張られることがあり、これらのリンクしている画像もWebブラウザは読み取らなければなりません。
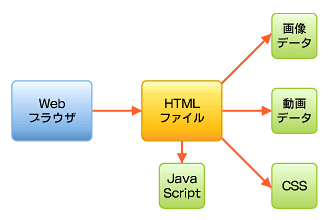 図3 HTMLファイルはいろいろなデータにリンクしている
図3 HTMLファイルはいろいろなデータにリンクしているテキストファイルや画像ファイルなら、Webブラウザのみの機能でなんとか表示できます。が、Flashや各種動画はWebブラウザ単体では表示できません。そこで、「プラグイン」という外部からの拡張機能のプログラムを導入してそれらのデータを再生します。
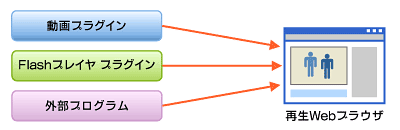 図4 リッチコンテンツはプラグインや外部プログラムを使って再生する
図4 リッチコンテンツはプラグインや外部プログラムを使って再生する動画だけでなくPDF、WordやExcelといった実行可能形式のコンピュータプログラムも同様に表示できます。以下のようにPDFファイルをブラウザ内で表示できます。
 画面8 PDFやワードの画面表示例(表示したデータは、文部科学省の
画面8 PDFやワードの画面表示例(表示したデータは、文部科学省の■表示だけでなく、動的にプログラムを実行できる
上述のような画像や動画は「表示する」ことがメインでしたが、もちろん、それだけではありません。
Webブラウザ上でPerlやPHPといった取り扱いが容易なプログラミング言語を用いて、Webサーバ上でプログラムを動かし、動的な情報を読み込んで、目的のプログラムを実行することもできます。
例えば、JavaScriptというプログラミング言語はWebブラウザ上で読み込んで、以下のようなリアルタイム表示などを実行します。

Webブラウザが単なるビューアではなく、指令された文書構造を「解析・整理して表示」したり、「Webサーバ上でプログラムを動かすことができる」ソフトウェアであることがお分かりいただけましたか。
WebサーバとWebブラウザの関係、Webブラウザの役割といったインターネットブラウジングの基本的な技術について説明しました。次回後編では、WebブラウザやHTMLの歴史と未来について解説をします。お楽しみに!
- 開発現場のUIトラブルを解決!? 画面プロトタイプ入門
- いまさら聞けない「Curl」入門(お菓子じゃない方)
- いまさら聞けない「オフラインWeb」入門──オフラインでも使えます
- いまさら聞けない「SEO」入門──検索結果の最適化
- いまさら聞けない「Webブラウザ」超入門 後編
- いまさら聞けない「Webブラウザ」超入門
- いまさら聞けない「マッシュアップ」超入門
- いまさら聞けないSVG、なぜ知られていないのか?
- いまさら聞けないActiveX&デジタル証明書入門
- いまさら聞けないウィジェット/ガジェットで気分転換
- “リッチクライアント”に至るまでの軌跡と現在(いま)
- いまさら聞けない! FlashとActionScriptについて
- いまさら聞けない“Web標準”、そしてXHTML+CSS
- いまさら聞けない、“Ajax”とは何なのか?
- いまさら聞けないJavaScript入門
- いまさら聞けないWeb2.0時代のXML入門
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。