OSSのJavaバッチフレームワークでHello World!:Javaバッチ処理は本当に業務で“使える”の?(2)(2/3 ページ)
Javaバッチアプリケーション作成のための準備
TERAバッチを利用した簡単なアプリケーションを作成していきましょう。
TERAバッチで必要な実装
TERAバッチで、実装しなければならないソースコードは以下のとおりです。
| 表1 TERAバッチで必要なソースコード | |||||||||||||||||||||||||||
|
HelloWorld!アプリケーションの仕様
今回作成するHelloWorld!アプリケーションの仕様は以下のとおりとします。
1.以下のデータ形式のCSVファイルから、データを読み込む
| 表2 読み込むCSVファイルの形式 | ||||||||||||
|
2.CSVの内容をパースし、標準出力に、「{$ID}:{$名前}さん、こんにちは。{$メッセージ}」と表示
開発環境の準備
TERAバッチを利用したアプリケーションを構築する環境を準備します。
本アプリケーション開発の前提として、Eclipse 3.2以降の利用が必須となります。作業効率を上げるため、プロパティエディタやXMLエディタも導入してください。Eclipseのプラグインについては、連載「CoolなEclipseプラグイン」が参考になります。
また、TERバッチの動作には、JDK 1.5が必要です。プログラムのコンパイルおよび実行環境をEclipseの設定でJDK 1.5にしてください。なお、この説明の中では、Windows上での開発を想定しています。
開発ホスティングサービスのSourceForgeのサイトから、バッチフレームワークのブランクプロジェクトをダウンロードします。「TERASOLUNAフレームワーク リリースファイル・リスト」から、「terasoluna-batch4j-blank_2.0.0.1.zip」(2008年4月17日現在)をダウンロードし、Eclipseの「Workspace」フォルダ配下に展開してください。
ブランクプロジェクトを、Eclipseにインポートします。Eclipseメニューの[ファイル]→[インポート]から、[インポート]ウィザードを開き、[一般]→[既存プロジェクトをワークスペースへ]から、[ルートディレクトリの選択]を選んで、[参照]ダイアログから、先ほど展開したブランクプロジェクトを選択してください。
ここまでで、TERAバッチを利用したアプリケーションを開発するための準備完了です。
読み込むCSVファイルを作成
続いて、アプリケーションが読み込むCSVファイルを作成します。[パッケージエクスプローラ]ビューで、「terasoluna-batch-blank」プロジェクトを右クリックし、[新規]→[フォルダ]で新規フォルダを作成します。フォルダ名は「inputfile」とします。配下に、「inputdata.csv」を作成します。データは以下のとおりとします。
1,出田太郎,ほげほげ |
ジョブBean定義ファイルを作成
右下の図3に、TERAバッチプロジェクトのディレクトリ構成例を示します。
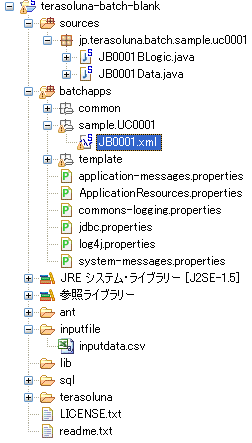 図3 ディレクトリ構成例
図3 ディレクトリ構成例- 設定ファイル
設定ファイル(ジョブBean定義ファイル)は、1ジョブについて1つ作成。配置場所は、batchapps\[任意の名称(今回は、「sample」)]\[業務ID]配下になる - Javaファイル
Javaソースファイルは、「sources」フォルダ配下に配置。パッケージ名は任意だが、通常は業務IDもしくは、業務ID+ジョブIDといった名前にする(今回の説明では、業務IDする)
ジョブBean定義ファイルを格納するフォルダを作成します。[パッケージエクスプローラ]ビューで、「terasoluna-batch-blank\batchapps」フォルダを右クリックし、[新規]→[フォルダ]から「sample\UC0001」フォルダを作成してください。
ジョブBean定義ファイルを作成します。「batchapps\sample\UC0001」フォルダ配下に、「JB0001.xml」を作成し、以下のとおり入力します。
<?xml version="1.0" encoding="UTF-8" ?> |
ひな型ファイルのインポート
TERAバッチでは、バッチ処理において想定される処理形態(DB to DB、ファイル to DBといった入出力や、トランザクション制御をどのようにするか、ジョブを多重実行するのか、など)に必要なJavaBean定義の記述を「ひな型ファイル」として提供しています。「batchapps\templete」配下にあるファイル群がひな型ファイルです。適切なひな型ファイルをインポートすれば、設定ファイルの記載を大きく減らすことができます。
今回は、「ファイルを読み込み、標準出力に出力する」というパターンなので、「トランザクションなし」モデルのひな型をインポートします。先ほど作成したジョブBean定義ファイルの<beans></beans>ネスト内に以下の定義を追加します。
<import resource="classpath:template/NoTransactionBean.xml"/> |
また上記に加えて、ファイルアクセス共通機能を利用するために、ファイルアクセスBean定義ファイルをインポートします。以下の定義を、同じく<beans></beans>ネスト内に追加します。
<import resource="classpath:template/FileAccessBean.xml" /> |
以上で、基本となる設定ファイル(ジョブBean定義ファイル)の記述が完了となります。
いよいよ次ページではロジックを実装し実際に動かしてみます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。