可用性を高めるOpen HA Cluster:OpenSolarisで始めるブログサーバ構築(5)(3/3 ページ)
クラスタリング故に起こる障害
クラスタリングのノードに障害が起こった場合、「split brain(スプリットブレイン)」「amnesia(アムネジア)」という2つの問題が起こる可能性があります。
split brainとは、クラスタノード間のインターコネクト(ハートビート)が遮断され、クラスタノードが分割され、唯一のクラスタになってしまった場合のことをいいます。遮断されたクラスタは、自分自身がクラスタとして成立しているかどうかも分からない状態になります。この結果、各ノードが同時に共有リソースへアクセスし、データを破損させるおそれがあるため、問題となります。
一方amnesiaとは、すべてのノードがそのクラスタ内で不安定な状態になっている場合に起こります。
例えば、クラスタノード1とクラスタノード2からなる2ノードのクラスタがあるとします。ノード1が停止すると、クラスタ構成リポジトリのデータはノード2のものだけが更新され、ノード1では更新されません。この後でノード2が停止し、ノード1が再起動されると、今度はノード1は古い内容のクラスタ構成リポジトリに基づいて動作することになってしまいます。
このような問題を回避するために利用されるのが、定足数デバイスです。定足数デバイスでは、各ノードの投票数を1票として、過半数の投票がないとクラスタが動作しないようにする仕組みを取っています。その投票を行うために、あらかじめ当該デバイスを定足数デバイスとして登録しておきます。これは共有デバイス上に、もしくはサーバとして設定する必要があります。
Solaris Clusterで利用できるサービス
クラスタリング上で動作しているアプリケーションは、「フェイルオーバーサービス」または「スケーラブルサービス」のどちらかのサービスを取ります。
フェイルオーバーサービスとは、片方のノードが障害などでダウンした場合、もう片方のノードに移るサービスのことをいいます。その際に、サービス提供に必要な論理IPアドレスもクラスタノードのフェイルオーバーを行い、もう一方のノードへ移動します。
一方スケーラブルサービスでは、前回紹介したサーバのロードバランシングのように、クラスタ各ノードが同時実行できるクラスタサービスのことをいいます。
Solaris Clusterにおけるリソースグループ
Solaris Clusterにおけるサービスは、1つのリソースグループに属しています。そのリソースグループは、例えば図3のような2ノードクラスタ構成の場合、どちらか片方のノードをプライマリのノードとしています。
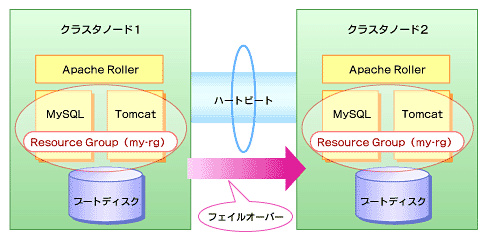 図3 リソースグループにおけるフェイルオーバー
図3 リソースグループにおけるフェイルオーバーここでは、プライマリノードをクラスタノード1とします。そして、クラスタノードには、my-rgというリソースグループがあると仮定します。そのリソースグループには、MySQL用のリソースとTomcat用のリソースが登録されています。
もし、プライマリノードであるクラスタノード1が何らかの障害によりダウンしたとすると、すべてのリソースはクラスタノード2に移り、リソースグループmy-rgはクラスタノード2から立ち上がります。
この例のように、Solaris Clusterにおいては、リソースやサービスはすべてリソースグループ単位で扱われる仕組みになっています。
これで一通り、Solaris Clusterのアーキテクチャについて解説しました。次回は、このSolaris Clusterをインストールし、ブログサービスを冗長化する手順を紹介しましょう。
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。