いまさらアルゴリズムを学ぶ意味:コーディングに役立つ! アルゴリズムの基本(1)(3/3 ページ)
フローチャートを学ぶ
アルゴリズムの記述にはフローチャートがよく使われます。ここではフローチャートの主要なものを紹介します。
・処理
<処理> フローチャートでは処理は四角形で表します。
<定義済み処理> 関数の呼び出しなど、ほかで定義してあるひとまとまりの処理の呼び出しを表します。
・順次、選択、反復
すべてのプログラムは順次・選択・反復の3つだけで記述できるとされています。今日のプログラム言語も突き詰めればこの3つだけになります。
昔のプログラムには「GOTO文」というものがあり、プログラム中のまったく関係ない部分に飛ぶことができました。しかしそういうプログラムは非常に分かりにくくなってしまうという問題がありました。
そこでGOTO文を使わないで、順次・選択・反復だけでプログラムを作ることが提唱されたのです。今日のプログラム言語ではGOTO文に相当するものがほとんどなく、自然と順次・選択・反復だけでプログラムが作られるようになっています。
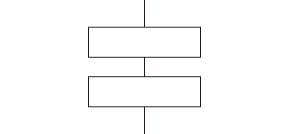
<順次> コンピュータの処理は1つ1つの処理を順に実行していくのが基本です。処理を線で結んで表現します。線の向きが分かりにくい場合は必要に応じて矢印を付けます。
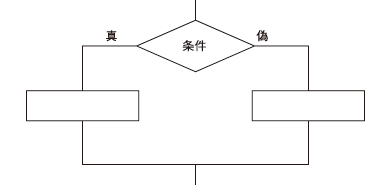
<選択(判断)> 条件を満たしているかどうかで処理を分岐させます。プログラム言語のifやswitch - caseに相当します。
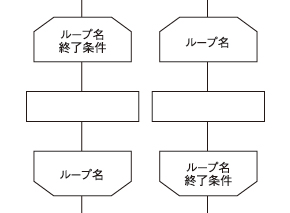
<反復(ループ端)> 繰り返し処理することを表します。プログラム言語のforやwhileに相当します。
・そのほかの記号
<端子> 外部環境からの入り口、出口を表します。プログラムの開始や終了などです。
<結合子> 同じ流れ図中のほかの部分への出口、またはほかの部分からの入り口を表します。1ページに入り切らなくて2ページ目に分かれるときや、見やすさのためにフローチャートを区切る場合などに使います。
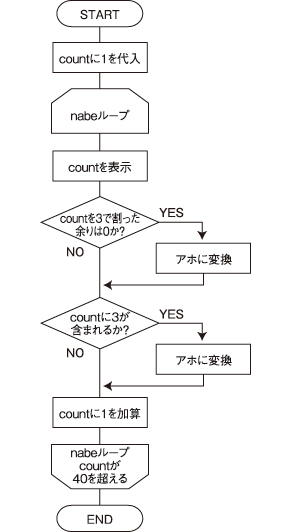
先ほどの世界のナベアツのプログラムをフローチャートで示します。実装ではnabe関数をタイマー呼び出ししているので定義済み処理ですが、意味的には反復なので反復として記述します。
UMLを学ぶ
フローチャートは古くから存在しており、フローチャートの標準を定義しているJIS X0121は制定が1970年4月1日、最終改定年月日は1986年2月1日となっています。そのため今日のオブジェクト指向言語のプログラムの流れを記述するには表現力不足の場合もあります。
オブジェクト指向言語の場合はUML(Unified Modeling Language)を使うケースが増えています。UMLではフローチャートとほぼ同様のダイヤグラムとして「アクティビティ図」があります。また、クラス間をまたがる処理の流れを記述するには「シーケンス図」が便利です。フローチャートをマスターしたら勉強してみるとよいでしょう。
| 関連記事: | |
|---|---|
| 5分で絶対に分かるUML http://www.atmarkit.co.jp/im/carc/serial/01fivemin/fivemin00.html |
|
さまざまなアルゴリズムを知っておこう
アルゴリズムの分野ではさまざまなトピックが取り扱われています。本連載ではその中でもよく知られていて、かつプログラム開発スキル向上に役立つものを紹介していきます。以下のようなトピックがあります。
再帰的アルゴリズム: 再帰という方法を使うと非常に簡単に解決できる問題があります。ほかのアルゴリズムの基礎になる部分でもあります。
ソート: ばらばらなデータを順序に従って並べ替えます。ただそれだけでもさまざまな手法があり、パフォーマンスにも大きな違いがあります。
探索: データの集合の中から特定のデータを探索します。ソートと同様にさまざまな手法があります。
文字列検索: 文字列の中から部分文字列を探し出します。一般的なプログラム言語のindexOfなどに相当する処理です。
データ圧縮: データの容量を減らします。例えばファイルをZIP形式に圧縮することなどが挙げられます。高度なデータ圧縮技術は難解ですが、基本的なものはそれほど難しくはありません。
本連載では扱いませんが、ほかにもアルゴリズムのトピックがあります。難解なものはプログラムの入門には向きませんが、知識として知っておくとよいものを紹介します。
暗号化アルゴリズム: WebでもHTTPSプロトコルで利用されていたりと身近にもよく利用されています。RSA、DES、トリプルDESといった手法があります。
並列・分散アルゴリズム: コンピュータは基本的にはある1時点で1つのことしかできず、1つ1つの処理を順に実行していきます。
しかし、現在のコンピュータではマルチプロセッサ、OSのマルチタスクなど同時に複数の処理を進めることが可能になっています。これを利用してより効率的に処理できるようにしたアルゴリズムを並列アルゴリズムと呼びます。
また、ネットワークを利用して複数のコンピュータで1つの処理を行うことで高いパフォーマンスを実現することもできます。グリッドコンピューティングという用語もよく使われます。ネットワーク上で複数のコンピュータで処理を行うことを実現するアルゴリズムを分散アルゴリズムと呼びます。
近似アルゴリズム・ヒューリスティックアルゴリズム: コンピュータで答えを出す場合に、計算量が多くなって現実的な時間内に答えが出せない場合があります。そういった問題でも、完全な正解でなくてもある程度正解に近い答えを出すことは、現実的な時間内にできる場合があります。このようなアルゴリズムは近似アルゴリズムと呼ばれます。
発見的・探索的に近似解を求めるアルゴリズムはヒューリスティックアルゴリズム(ヒューリスティクス)と呼ばれます。
ヒューリスティックアルゴリズムの中には、遺伝的アルゴリズムと呼ばれるものがあります。遺伝的アルゴリズムは、生物の進化に見立てたアルゴリズムです。解の候補を生成させて、より解に近いものを選択し、交叉・突然変異などの操作を繰り返しながら解を探索していきます。
遺伝的アルゴリズムが適用される問題の代表的なものに、巡回セールスマン問題があります。都市がいくつかあり、その都市の間の距離が与えられたとき、すべての都市を1回ずつ回って元の都市に戻る経路で最短のものを求める問題です。
一見総当たりで簡単に解けそうですが、少し都市が増えただけで計算量が莫大に増えてしまいます。そこで遺伝的アルゴリズムなど近似アルゴリズムで解く方法がよく用いられます。
次回は、さまざまなアルゴリズムの前提となるデータ構造について解説します。
関連記事
- いまさらアルゴリズムを学ぶ意味
コーディングに役立つ! アルゴリズムの基本(1) コンピュータに「3の倍数と3の付く数字」を判断させるにはどうしたらいいか。発想力を鍛えよう - Zope 3の魅力に迫る
Zope 3とは何ぞや?(1) Pythonで書かれたWebアプリケーションフレームワーク「Zope 3」。ほかのソフトウェアとは一体何が違っているのか? - 貧弱環境プログラミングのススメ
柴田 淳のコーディング天国 高性能なIT機器に囲まれた環境でコンピュータの動作原理に触れることは可能だろうか。貧弱なPC上にビットマップの直線をどうやって引く? - Haskellプログラミングの楽しみ方
のんびりHaskell(1) 関数型言語に分類されるHaskell。C言語などの手続き型言語とまったく異なるプログラミングの世界に踏み出してみよう - ちょっと変わったLisp入門
Gaucheでメタプログラミング(1) Lispの一種であるScheme。いくつかある処理系の中でも気軽にスクリプトを書けるGaucheでLispの世界を体験してみよう
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。