ここが大変だよBigtableとGoogle App Engine:分散Key-Valueストアの本命「Bigtable」(3)(2/2 ページ)
2つのインデックス「シングルプロパティ」「コンポジット」
「シングルプロパティインデックス」がカギ
Datastoreサービスでは、あるテーブルに含まれるすべてのエンティティについて、すべてのプロパティ(テーブルのカラムに相当)の値をキーとして並べた「シングルプロパティインデックス」と呼ばれるインデックステーブルが自動的に作成されます。
例えば、テーブルEmpが備える「name」「age」「dept_key」という3つのプロパティについて、「テーブル名+プロパティ名+プロパティ値」をキーとし、「Empテーブルの各行のキー」を値とする以下のようなインデックステーブルが作成されます。
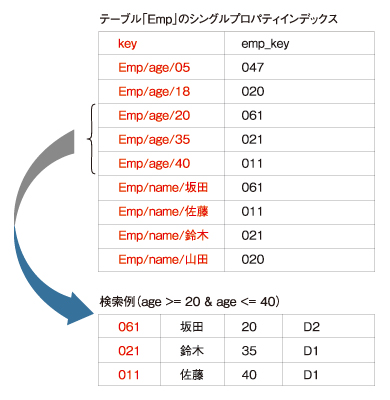 図2 シングルプロパティインデックスによるクエリの例
図2 シングルプロパティインデックスによるクエリの例Datastoreサービスでは、このシングルプロパティインデックスを用いることにより、アプリケーションが実行するクエリを「インデックスとスキャンの組み合わせ」に背後で変換しています。
例えば、上述の「age >= 20 & age <= 40」という範囲検索のクエリは、上記例のシングルプロパティインデックスのキー「Emp/age/20」から「Emp/age/40」までのBigtableスキャンに変換されます。これはいわば、「想定されるすべてのクエリの検索結果をあらかじめインデックステーブルに並べておくようなもの」です。
「コンポジットインデックス」は必要最小限に
しかし、こうしたDatastoreサービスのクエリ機能は、あくまでも「RDB風な条件検索をBigtableでまねたもの」であって、実際のRDBのクエリやジョインが提供する機能に比べて数多くの制約や制限を抱えています。
例えば、シングルプロパティインデックスによるクエリでは、「あるプロパティを対象に不等号(>、>=、<、<=)を使って範囲指定してしまうと、同じクエリ上でほかのプロパティを条件指定に含められない」という制限があります(なお、等号「=」による条件指定のみであれば複数プロパティを同時に使用できます)。
よって、例えばプロパティageの範囲指定だけでは、対象エンティティ数が数千〜数万件に膨らんでしまうような状況であると、実用的な時間内(例えば、数秒程度)でクエリを終了できなくなってしまいます。これがRDBであれば、まずプロパティdept_keyで特定部署に絞り込み、加えてプロパティageの範囲指定を行うことで、対象行を数百行以下に抑えるといった対策が可能です。しかし、シングルプロパティインデックスだけでは、そうした複雑な条件指定に対応できません。
そうした場合は、もう1つの種類のインデックスである「コンポジットインデックス」が利用できます。これは、シングルプロパティインデックスと同様のインデックステーブルを、複数のプロパティ値を組み合わせて作成したものです。なお、コンポジットインデックスを作成するには、App Engineの開発者がXML設定ファイルを通じて明示的に作成を指示する必要があります。
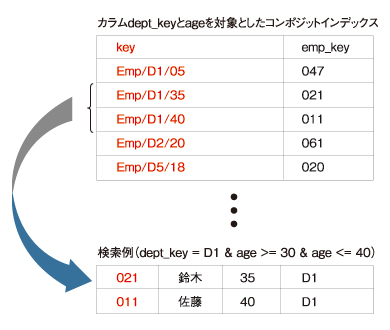 図3 コンポジットインデックスによるクエリの例
図3 コンポジットインデックスによるクエリの例このコンポジットインデックスを用いることで、「dept_key = 'D1' & age >= 30 & age <= 40」といった2つのプロパティを条件指定に利用可能になります。
しかし、コンポジットインデックスの問題点は、「あまり安易に多用はできない」という点です。インデックスであるからには、対象のテーブルの行が更新されるたびにインデックスも更新が必要です。よって、コンポジットインデックスを何十個も作成してしまうと、パフォーマンスの低下が懸念されます。
よって、既存のSQL文に含まれる検索条件を次々とコンポジットインデックスに置き換えていくのではなく、「ここぞ」という重要な用途に絞って使う必要があります。
基本的には、シングルプロパティインデックスによるクエリとプログラムコード上でのフィルタリングやソートを組み合わせるのが定石といえるでしょう。
そのほかのDatastoreクエリの“大変”なトコロ
Datastoreによるクエリには、ほかにも以下のようなさまざまな制約があります。
■テーブルの結合(join)ができない
Datastore APIの最大の制約は、やはりテーブルの結合(join)ができない点です。その対処として、結合対象となる個々のテーブルへのクエリを個別に実行する方法や、テーブル設計を非正規化し結合済みのテーブルとする方法があります。
またDatastore APIでは、エンティティに「List Property」と呼ばれる複数の値を保持するプロパティを持たせることができるので、これを利用して一対多の関連を表現できます。
■クエリ構文の制約
クエリの構文には多数の制約があり、その代表が「LIKEによる部分一致検索ができない」というものです(前方一致検索はサポートする)。よって全文検索を実施したい場合は、検索対象の文字列からキーワードを切り出した転置インデックスをアプリケーション側で作成して利用する必要があります。
またクエリでは、「OR」「!=」が使えないほか、不等式条件(「<」「<=」「>=」「>」)を同時に複数のプロパティに適用できない、不等式条件に指定したプロパティが最優先でソートされるといった制約があります。
■HTTPリクエストの処理時間は30秒まで
これはDatastore APIの制約ではなく、App Engine全体の制約です。1つのHTTPリクエストに対しては30秒以内にHTTPレスポンスを返す必要があり、その時間を超えると例外が発生する仕組みです。よって、Datastore APIを介して大量のデータにアクセスしたり、バッチ処理を実行したりする場合には、個々の処理を25秒程度で切り上げて、次のリクエストで処理の続きを再開するようなロジックが必要となります。
■集約関数や組み込み関数がない
「min()」「max()」「sum()」といった、SQLの集約関数、およびgroup byの機能がサポートされていません。よって、例えば「あるプロパティの最大値」を得るには、そのプロパティの降順でソートするクエリを実行し、最初の1行を得るといった工夫が必要です。
逆に「複雑なクエリやジョインなんていらないさ」
このように、Datastore APIでは従来のRDBでは「当たり前」にできたことがまったくサポートされていないことも少なくなく、相当なワークアラウンドを強いられることもしばしばです。
実際に筆者の開発案件でも、RDB上に構築された既存のスキーマをそのままDatastore APIに載せただけでは、クエリ構文の制約が障害となって要件を満たせない状況が発生しました。そこで、「テーブル結合の代用としてインデックス的に使用するテーブルを新たに追加する」というワークアラウンドで対処しています。
しかし、これらの制約を前向き受け止め、「逆に考えるんだ、複雑なクエリやジョインなんていらないさ」という発想で、「分散KVS時代の新たなデザインパターン」を構築していけるかが、冒頭で紹介した事例のような2けたレベルの劇的なコストダウンを可能にする発想の転換への近道ではないかと筆者は考えます。
結局、DatastoreのAPIはどれがいいの?
App Engineをこれから使おうと考えるJava開発者は、Datastoreサービスが提供するJDO、JPA、そしてLLという3種類のAPIのうちどれを選択すべきかが、悩ましいポイントです。これら3つのAPIのうち、グーグルが最も豊富なドキュメントやサンプルを提供しているのはJDOベースの実装です。
一方、JPAやLLについては、APIドキュメント以外にあまり豊富なドキュメントは用意されていません。そのため、筆者を含め、Datastoreサービスを使い始める方の多くは、まずJDO実装から学んでいます。しかし実はここ数カ月の間に、App Engine Java版の利用者の間からは、JDO実装について、以下のように指摘されるようになりました。
- パフォーマンスが低い(LLのおよそ1/3)
- Bigtable本来の機能から離れ過ぎていて理解しにくい
- バグがある
そのため、App Engineを使いこなす中級者は試行錯誤しながらLLを使い始める方もいます。また、ひがやすを氏が提供するApp Engine対応のMVCフレームワーク「Slim3」に備わる、「Slim3 Datastore」は、LLと同等のパフォーマンスを維持しながら、簡潔で使いやすく理解しやすいAPIを提供しており、急速に導入事例が増えつつある状況です。
| パフォーマンス | 書きやすさ・ 理解しやすさ |
ドキュメント | 事例の豊富さ | |
|---|---|---|---|---|
| JDO | × | △ | ◎ | ○ |
| JPA | × | △ | △ | △ |
| LL | ◎ | △ | × | △ |
| Slim3 | ◎ | ◎ | ○ | △ |
また、Slim3のサイトで公開されているパフォーマンステストツールを使うと、JDOに比べてLLおよびSlim3が3〜4倍ほど高速なことを実際に確認できるので、参考にしてみてはいかがでしょうか。
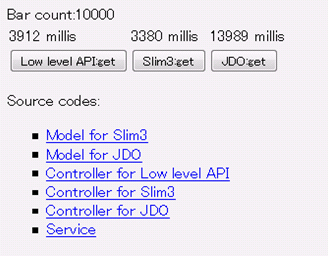 図4 LL、Slim3、JDOのパフォーマンス比較結果
図4 LL、Slim3、JDOのパフォーマンス比較結果著者プロフィール
吉川 和巳(よしかわ かずみ)
スティルハウス
Adobe AIR/Flex、Ruby on Rails、Google App Engine for Javaを主軸とする開発業務に従事しています。
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。