わが社はいかにしてHadoopクラスター環境を構築したか:となりのアドテク(2)(4/5 ページ)
CMを使ってHadoop環境を構築する
ここまでの事前準備が済んだら、いよいよCMを使ってHadoop環境の操作を行ってみます。CMにログインし、エディション「Cloudera Standard」(Standard Editionのこと)を選び「続行」をクリックします。
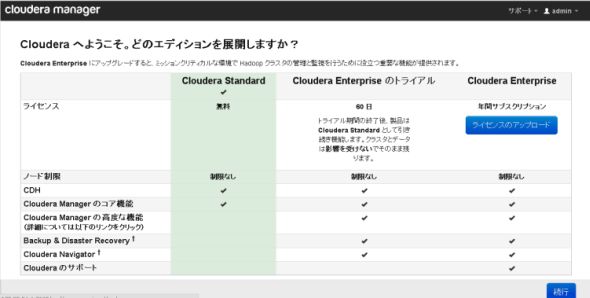 図6 エディションの選択
図6 エディションの選択Hadoopに使うサーバーのIPアドレス、またはホスト名を入力し検索をクリックします。対象ノードが検出されるので全て選択し「続行」をクリックします。
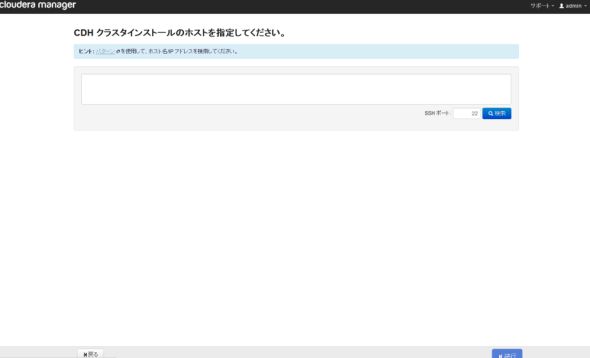 図7 サーバー情報の指定
図7 サーバー情報の指定リポジトリは「Parcel」を選択します。今回、「Solr」と「Impala」は使わないので「なし」を選択し「続行」をクリックします。
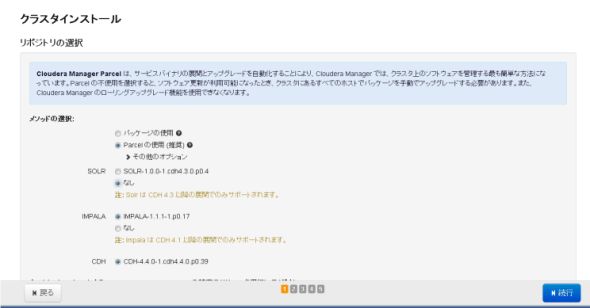 図8 コンポーネントを選択する
図8 コンポーネントを選択する各サーバーにrootでSSHログインする為の認証情報を入力し「続行」をクリックします。
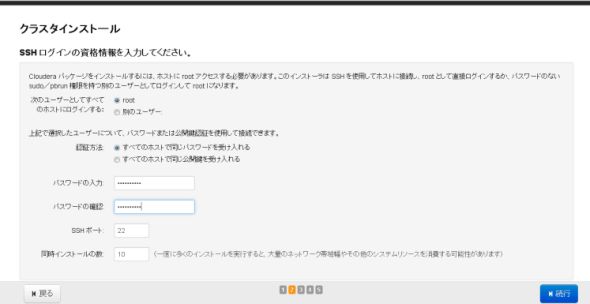 図9 認証情報の入力
図9 認証情報の入力CDHの各パッケージやCMエージェントのインストールが実行されます。
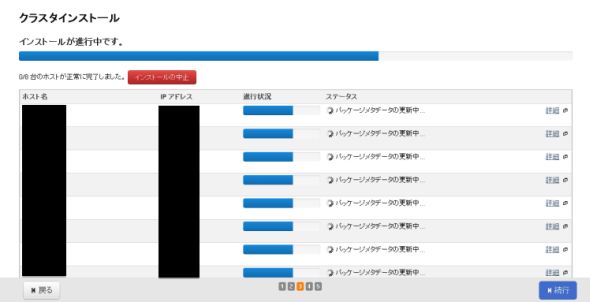
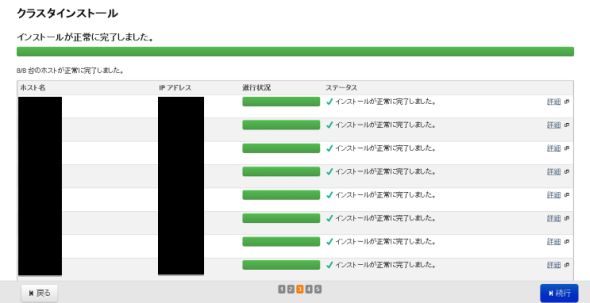 図10-1、10-2 パッケージ、エージェント類のインストール
図10-1、10-2 パッケージ、エージェント類のインストールホストが正常かどうかをチェックする「ホストインスペクタ」が実行されます。
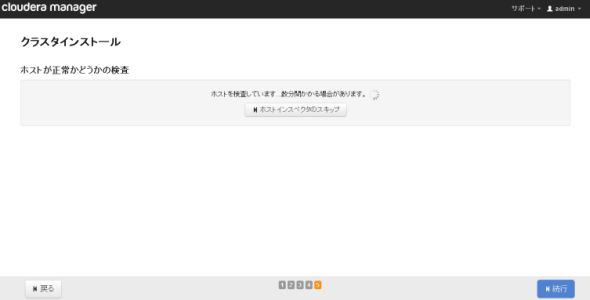
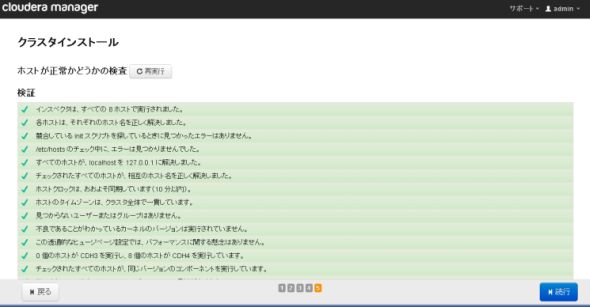 図11-1、11-2 「ホストインスペクタ」の実行
図11-1、11-2 「ホストインスペクタ」の実行CDHの利用サービスを選択します。サービスを指定した後にロールの割り当てを行います。
※サービスとロールについて CMで使う言葉の定義は、サービスはHDFSやMapReduceのことで、ロールはNameNodeやDatanodeやJobTrackerやTaskTrackerのことです。
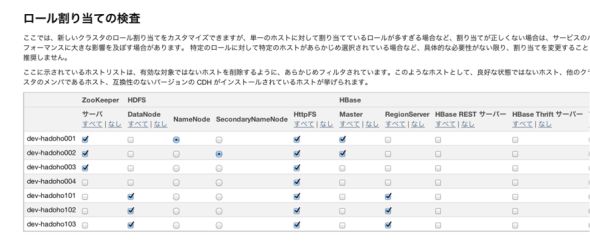 図12-1、12-2 サービスとロール
図12-1、12-2 サービスとロールCMの構成情報やモニター情報やジョブ履歴情報などを格納するDBのセットアップを行います。Hiveサービスを使う場合はHiveのメタデータ格納DBのセットアップも行います。DBはMySQL、PostgreSQL、Oracleから選択できます。
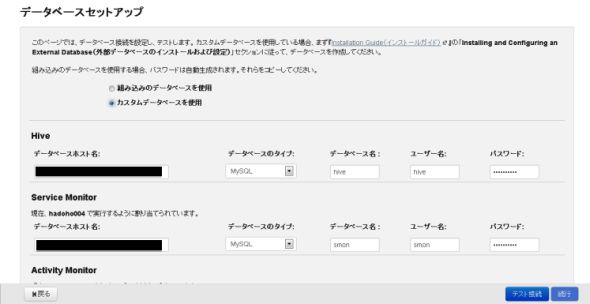 図13 DBのセットアップ
図13 DBのセットアップHadoopクラスターの起動が始まります。CMを使わない場合は各サービスの起動順序を考慮する必要がありますが、CMを使った場合は起動順を考慮した形で各サービスの起動が行われます。
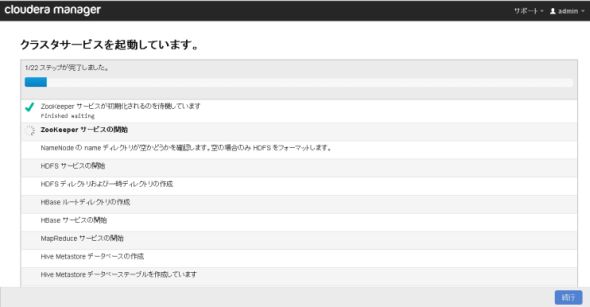 図14 クラスターの起動
図14 クラスターの起動ここまでの作業が完了して、以下の、“おめでたい”画面が表示されればクラスター構築と起動が完了しています。
 図15 この画像が出たら、「おめでとう」
図15 この画像が出たら、「おめでとう」クラスター構築が完了したあと、NamenodeとJobTrackerはSPOFの状態なのでHA構成にします。HAタイプは「NFS」か「Quorumベース」が選択できますが、もはやNFSを選択する理由はないので「Quorumベース」を選択します。ロールの割り当てで「StanbyNamenode」「JounalNode」「ZKFC」を適宜各サーバーに割り当てます。
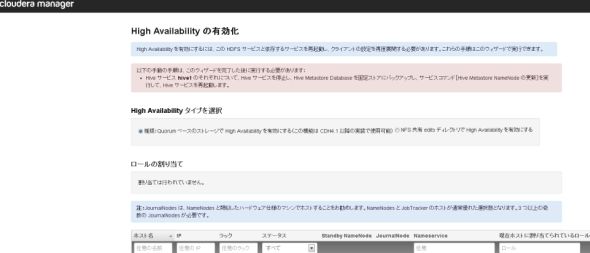 図16 HA構成の設定
図16 HA構成の設定以上で、NamenodeとJobtrackerを冗長化したクラスター構築作業および起動が完了になります。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。