Pythonで操作するブロックチェーンベースのデータストアBigchainDBとは:ブロックチェーンの検証現場で何が起きているのか(3)(2/2 ページ)
履歴書DBにおける「トランザクション」データの取り扱い方
前述の通り、BigchainDBでのデータは全て「トランザクション」として取り扱われるため、実際にascribe側で管理していた(であろう)データを以下のように分類し、「トランザクション」の内容に分類用のキーを付与し、識別できるようにしました。
- ユーザー情報(表示名と公開鍵と秘密鍵のペア)
- 承認要求情報(誰が、どの企業に対して、どのような経歴データの承認を要求しているのか)
- 経歴情報(誰が、どの企業に、いつからいつまで在籍していたのか)
- 公開情報(どの経歴情報を、誰に、いつからいつまで公開するのか)
データを取り出す際にはBigchainDBが現在持っている以下、2つのクエリの機能を用いて、自身の保持している「トランザクション」の内容を全て取得し、さらに登録時に付与したキーでデータをフィルタリングして取得します。
- 自身の保持している「トランザクション」のID一覧を取り出す
- 「トランザクション」IDから「トランザクション」の内容を取り出す
例えば自身の経歴情報を取ってくるような場合は、一度「トランザクション」の内容を全て取ってきてから分類用のキー(経歴情報など)でフィルタリングする、といった形になっています。
履歴書DBにおける「トランザクション」の登録方法
前述のようなポイントを軸に、ascribe APIからBigchainDBへ、データの登録先を変更しましたが、履歴書DBの動き自体は変わっていません。よって、ここからは、前回の図を参考にそれぞれのオペレーションで「トランザクション」がどのように登録、移転していくのかを見ていきます。
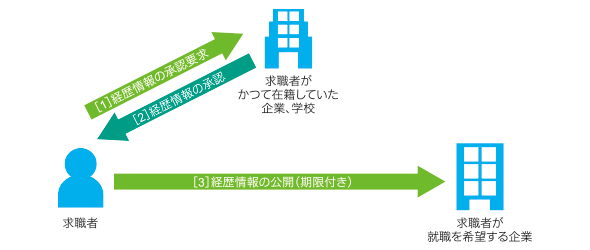 前回記事図4の再掲
前回記事図4の再掲【1】求職者が自身の経歴を登録し、企業、学校に対して承認要求を行う
「承認」の「トランザクション」(デジタルアセット)を作成し、所有者を「求職者がかつて在籍していた企業、学校」としています。これにより、「求職者がかつて在籍していた企業、学校」側が承認要求を確認できるようになります。
また、「承認要求」の「トランザクション」も同時に作成し、所有者を求職者自身としています。これは、求職者側からも現在出している承認要求はどれかを確認するためです。
【2】「求職者が所属していた企業、学校」が受け取った要求を承認する
【1】で作成された「承認」の「トランザクション」の所有権を、求職者に移転する「トランザクション」、また、【1】で作成された「承認要求」の「トランザクション」の所有権を、承認要求回収用のユーザー(あらかじめシステム側で定義)に移転する「トランザクション」を作成しています。
これにより、「求職者がかつて在籍していた企業、学校」の承認要求一覧から今回承認した「トランザクション」が見えなくなり、求職者側からもこの承認要求が見えなくなります。
【3】「求職者が就職を希望する企業」に対し、【2】で求職者がかつて在籍していた企業、学校に承認してもらった経歴を公開する
新たに「公開」の「トランザクション」を作成し、所有権を「求職者が就職を希望する企業」にしています。
【4】就職を希望された企業側が求職者に公開してもらった経歴を閲覧する
「求職者が就職を希望する企業」が自身の保持している「トランザクション」の一覧を取得し、「公開」の「トランザクション」だけを取り出すことで求職者の経歴を確認できます。公開日時の設定も経歴と同時に書き込まれているので、対象期間から外れたら一覧から外し、企業側に見えないようにしています。
なお、ユーザーの「トランザクション」については、求職者、学校、企業の登録時に入力した表示名と一緒に公開鍵、秘密鍵を作成し、「求職者管理用のユーザー」「企業、学校管理用のユーザー」(両方共あらかじめシステム側で定義済み)のそれぞれの持ち物として「トランザクション」を作成し、新たに作成された「トランザクション」のIDと一緒にブラウザのCookieに保存しておきます。ログイン時には「トランザクション」IDをキーにBigchainDBに「トランザクション」の内容を問い合わせ、「見つかったらログイン成功」となります。
BigchainDB版で解決できたこと
ascribe(など外部エンティティ)への依存を解消
下図のように、履歴書DBに必要なデータは全てBigchainDBへ移行できたたため、ascribe(API)へは依存しなくなりました。

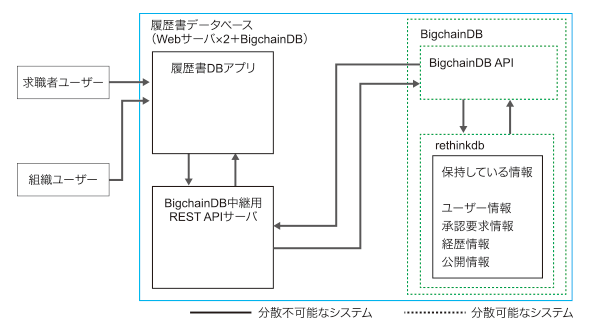 BigchainDB版概要
BigchainDB版概要BigchainDBに全てのデータが入っているため、改ざんが困難に
「アプリケーションが利用する全てのデータを入れること自体が良いか悪いか」を考える必要はあるものの、履歴書DBに利用する全データをBigchainDB(ブロックチェーン管理)上に置いたため、以前のようにデータがascribeや、ローカルのRDBに入っていた時に比べ、十分にデータの改ざんが困難になったといえます。
問題点、次への課題
今回のBigchainDB版では、先の通り幾つかの課題を解消できました。この中で得られた知見や、残った課題をまとめます。
クエリ機能が未完成
前述の「トランザクション」データの取り扱いにも書きましたが、「データを取り出す機能として自身の保持している『トランザクション』IDの一覧を取り出すもの」と、「『トランザクション』IDから『トランザクション』の中身を取り出すもの」の2つしか現状は実装されていません。このため、複雑なクエリが必要になるようなアプリケーションへの適用はなかなか難しいことが分かります。
この点は、BigchainDBのページにもまだ記載はなく(2016年8月末現在)、今後改善される可能性は十分にありそうです。
「トランザクション」の反映に若干時間がかかる
「トランザクション」の作成(その後の署名、書き込みまで)が終わった後に、自身の保持している「トランザクション」の一覧を取得する処理を行いますが、このとき、反映までに数秒〜十数秒かかっていました。この辺りはブロックチェーンの「集団合意」を行う必要などがあり、なかなか解決は難しいため、反映は遅いことを前提としてアプリケーション側で見せ方を工夫する必要があると感じました。
REST API用のサーバを別途立てる必要がある
BigchainDB自体がPythonで作成されており、履歴書DBから直接APIを実行できなかったため、履歴書DBとBigchainDBをつなぐためにPython(Django)で作成したREST API用のWebサーバを立てる必要がありました。
なお、BigchainDB自身もREST APIを持ってはいますが、こちらもクエリの機能と同様、まだ開発途中で機能が不足しており、今回の検証では利用できませんでした。
分散できていない部分が残る
先のREST APIでもそうですが、REST APIのサーバ、および履歴書DBが動いているサーバがダウンした際にシステムが利用できなくなる欠点はascribe版から引き続き残ってしまいます。
次回は、分散アプリケーションをEthereumベースに
次回は、本連載がベースとしている、ビットコインが実現しているシステムアーキテクチャの参考方法をメインに、分散アプリケーション(dapps)をEthereumベースで作成した検証について説明します。
筆者紹介
中野 猛(なかの たけし)
リクルートテクノロジーズ ITソリューション統括部 アドバンスドテクノロジーラボ
シニアリサーチエンジニア。リクルートテクノロジーズの技術開拓&検証機関であるATLで、主に欧州、イスラエルのテクノロジースタートアップとの提携および共同開発を推進中。
これまでに日本では検索エンジン(Apache Solr)やビッグデータ処理(Hadoop)などでの共著、ベルリンでは某スタートアップハブ、イスラエルではテクニオン大学でのメンタリングなど、積極的な対外活動を行う。
現在、技術カテゴリとしてはブロックチェーンにフォーカス。
筆者紹介
中鉢 洋介(ちゅうばち ようすけ)
Curious Vehicle プリンシパルエンジニア
ATLには2016年初頭から参画し、ブロックチェーン技術を中心としたR&Dに従事。
過去にはC、java、PHPなどで大規模Webアプリケーションの開発をする傍ら、ミドルウェアの使いこなしを得意とし検索エンジンSolrの解析や機能開発、コンサルティングなどを行ってきた。
関連記事
 インフォテリアとテックビューロ、金融機関でのプライベートブロックチェーン実証実験に成功
インフォテリアとテックビューロ、金融機関でのプライベートブロックチェーン実証実験に成功
インフォテリアとテックビューロは、金融機関の勘定データをクラウド上に配置したプライベートブロックチェーンに移行する実証実験に成功。勘定データの記録に同技術を適用できることが実証されたとする。 オリックス、静岡銀行らがブロックチェーンでNTTデータらと共同研究
オリックス、静岡銀行らがブロックチェーンでNTTデータらと共同研究
NTTデータなど5社は、ブロックチェーン技術を活用した新たな金融サービスの開発に向けて共同研究を開始する。 JPX、みずほがブロックチェーン技術の実証実験を開始
JPX、みずほがブロックチェーン技術の実証実験を開始
証券、金融取引でブロックチェーン技術適用の可能性を探る動きが日本国内でも。JPXはOSSの分散台帳フレームワークで、みずほフィナンシャルグループはAzure BaaSで検証を行う。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。