ブロックチェーン技術「Ethereum」とは何か、アプリのアーキテクチャはどう変わるのか:ブロックチェーンの検証現場で何が起きているのか(終)(3/3 ページ)
ここまでの課題点
ここまでで、履歴DBの基本的な機能(下記)を、アプリやエージェント(コントラクト)同士を相互にやりとりさせることで、実現できました。
- 求職者が登録したい経歴の作成
- 組織側の承認
- 承認された経歴を他の組織へ開示
この実装では、経歴の書き込み、承認、公開のやりとりがブロックチェーンを介して記録されます。
このようにEthereumでは、各組織や求職者のアカウントがただのアドレスとなっており、ブロックチェーンに書かれた取引から「それが誰が誰に対して行ったものか」は特定できないようになっています。アカウントとコントラクト間の取引も同様です。しかし、アドレスと個人情報が一度ひも付いてしまうと、以降のやりとりから「誰が誰に対して行った通信(トランザクション)か」が、明らかになってしまいます。よって、(実際の求職者、企業を特定することは難しいものの)「誰がどこに、どの期間所属していたか」などの経歴情報や、「承認依頼をしたか」などのやりとり情報まで外部から(Ethereumのネットワークから情報を引き出すことで)分析できてしまいます。
この問題を解決するために、求職者の経歴情報をブロックチェーンに書き込まないようにし、承認要求、公開は全てWhisperを介して行うようにします。承認したという行為のみは証明が必要なためブロックチェーンに書き込みますが、「誰のどのような経歴を承認したか」を特定できないようにして書き込みます。
通信内容が公になる問題を解消する
この問題は、「匿名にした上で全ての取引(トランザクション)を公にし、第三者が外から分析、監査できるようにしている」というEthereumのパブリックなネットワークの特徴に端を発しています。その特徴を生かしつつ、実際のアプリケーションに対応するため、求職者が自身の経歴をアプリ内で管理し、経歴をブロックチェーンに書き込まない形に変更します。これにより、経歴を書き込んだアカウントと求職者の個人情報がひも付いたとしても、ブロックチェーンから経歴を参照できなくなります。
経歴を組織に承認してもらう、もしくは組織に公開する際は、Whisperを介して個人情報および経歴を該当の組織アプリに送ります。このように処理することによって、必要な経歴のみを該当の組織に見せることができます。また、この方法では求職者エージェントが手続きを仲介することはないため、求職者のエージェント自体が不要となります。
ただ、このように求職者個人が経歴を管理してしまうと、「組織が承認した経歴かどうか」を証明できないため、ブロックチェーンに承認の証明を書き込むことで対応します。
その際、「誰の、どのような経歴なのか」を分からないようにするために、求職者の個人情報と経歴からハッシュを生成して、ブロックチェーンにはハッシュのみを書き込みます。ハッシュは承認を行う組織アプリが生成し、そのエージェントが管理します(図13)。

求職者が経歴を公開した場合は、「公開された経歴が承認済みであるかどうか」を職歴を承認した組織のエージェントに確認します。これは承認時と同様に、求職者の個人情報と経歴からハッシュを生成して、該当の組織エージェントに同じハッシュが登録されているかを確認し、登録されていれば承認済みの経歴であると判断します(図14)。

少し複雑に思えますが、当初作成したもの(図3)と、図15を比較することで変更点が分かると思います。これにより、先に上げた通信が公になってしまうことによる課題は解消できていることが分かります。

残る課題と今後の進化
最後に、さらに残る課題について触れておきます。
全体で共有するデータについて
エージェントに蓄積される情報、例えば組織一覧などは利用者が増えるほど増加しますが、「これらをどう効率よく管理するか」「これらの情報に対する検索をどう実施するか」も現時点では課題です。
これらに対し、Ethereumとしては「Swarm」という仕組みの実装が進んでいます。これ以外に別のプロジェクトとして「IPFS」(InterPlanetary File System)も徐々に実装が進み、実験的に公開されてきています。
ただ、現時点で実際に組み込んで利用できそうなIPFSですが、実際に使おうとすると、Ethereumのコントラクトから直接呼び出すことはできません。コントラクトは入出力としてブロックチェーンのトランザクションを使います。例えば、「トランザクションを見張っている別プロセスがIPFSの各種オペレーションをコールする」という形で実装することになります。
エージェントからではなくweb3.jsを使っているWebアプリ上からIPFSを操作する方法でも、どこかで書き換え順序などを担保しなくてはなりません。しかし、この実装を分散アーキテクチャの上で実現するためには、現時点ではEthereumの枠を超えた別の仕組みを使って実装する必要があるでしょう。
このように、現在は、それぞれの世界(EthereumやIPFSなど)が実装的に分断されており、その後の連携に関しては、混沌としている状態といえます。
皆が使える仕組みに向けて
スマートフォンでのDApps実装に向け、Ethereumでは「LightClient」という実装が議論、開発されています。これまでのクライアントのような「実際にブロックチェーンを持ち合うフルノード」とは異なり、「一部分の情報だけを保持し、不足があれば、そのフルノードに問い合わせをする」という実装です(図16)。
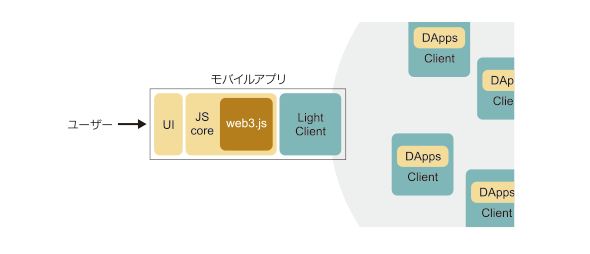 図16 LightClientを使ったEthereumの実装
図16 LightClientを使ったEthereumの実装Androidなどスマートフォンで使えるようになるには、この発展を待つ、または、「完全な分散アーキテクチャになることを捨て、共通で使えるGethのサーバを用意する」という対応が必要です(スマートフォンなどは計算能力が限られるため、Gethをスマートフォンで実行することは難しい)。
なお、後者(Ethereumネットワークへの入り口たるGethインタフェースを準備する)は、上海のスタートアップInfura.ioが提供を開始しているため、一足早くこれをベースに実装することも可能です。
ブロックチェーンを使った全く新しいアーキテクチャができつつある
本連載を通じて、ブロックチェーンを利用することで実現できる世界を、順を追って見てきました。今回はさらに一歩進んだDAppsの世界を、Ethereumをベースに見ていきました。
このように、特に今回紹介したDAppsについては、これからの発展に期待する部分が大きいことは事実ですが、「これまでのインターネットを利用したサービスの実現方法とは全く異なる可能性を秘めたアーキテクチャができつつある」ことを感じられたかと思います。
リクルートテクノロジーズおよびATLとしては、これからもブロックチェーン技術の進化に対してコミットし、発展自体にも貢献できるよう幅広く、スタートアップや社内外の開発者と連携していこうと考えています。
最後に、補足になりますが、このEthereumによる計算環境は、Ethereumネットワークに参加しているノードが計算をする(ネットワークが十分なノードを持って構成されている)必要があり、この点でEthereumはまだ未知数だといえます。この点に対し、ビットコインの元コア開発者が始めたスタートアップRSK Labsが、Ethereumと同じEVMコードを、参加ノードの計算リソースが十分担保されているビットコイン上のブロックチェーンで実現しつつあり、この検証にATLも参加しています。こちらについては、今後また何かの形でご紹介できればと考えています。
筆者紹介
中野 猛(なかの たけし)
リクルートテクノロジーズ ITソリューション統括部 アドバンスドテクノロジーラボ
シニアリサーチエンジニア。リクルートテクノロジーズの技術開拓&検証機関であるATLで、主に欧州、イスラエルのテクノロジースタートアップとの提携および共同開発を推進中。
これまでに日本では検索エンジン(Apache Solr)やビッグデータ処理(Hadoop)などでの共著、ベルリンでは某スタートアップハブ、イスラエルではテクニオン大学でのメンタリングなど、積極的な対外活動を行う。
現在、技術カテゴリとしてはブロックチェーンにフォーカス。
筆者紹介
向井 育正(むかい いくまさ)
リサーチリード
ATL発足以前からリクルートの技術R&Dに参画し、その発展に大きく貢献。これまでに業務システム、組み込みシステム、Webシステムと、さまざまなシステムの開発経験をベースにHadoopの初期検証導入、独自の動的Webページキャッシュや独自言語を持つApache Stormを基盤としたストリームシステムの設計開発などを行う。こだわり抜くことを大切にする自称「ソフトウェア職人」。「亀で歩みが遅くても、一歩ずつ確かな足取りで進んでいきたい」がモットー。
関連記事
 インフォテリアとテックビューロ、金融機関でのプライベートブロックチェーン実証実験に成功
インフォテリアとテックビューロ、金融機関でのプライベートブロックチェーン実証実験に成功
インフォテリアとテックビューロは、金融機関の勘定データをクラウド上に配置したプライベートブロックチェーンに移行する実証実験に成功。勘定データの記録に同技術を適用できることが実証されたとする。 オリックス、静岡銀行らがブロックチェーンでNTTデータらと共同研究
オリックス、静岡銀行らがブロックチェーンでNTTデータらと共同研究
NTTデータなど5社は、ブロックチェーン技術を活用した新たな金融サービスの開発に向けて共同研究を開始する。 JPX、みずほがブロックチェーン技術の実証実験を開始
JPX、みずほがブロックチェーン技術の実証実験を開始
証券、金融取引でブロックチェーン技術適用の可能性を探る動きが日本国内でも。JPXはOSSの分散台帳フレームワークで、みずほフィナンシャルグループはAzure BaaSで検証を行う。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。