第1回 Dockerとは:超入門Docker
Dockerの概要を知るための超入門連載(全4回)。Dockerとは何か、コンテナとは何か、従来のハードウェアエミュレーション型の仮想化とはどう違うのかなどについてまとめておく。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
本入門連載では、システム管理者やシステムエンジニアの方々を主な対象として、IT業界でよく使われる技術や概念、サービスなどの解説をコンパクトにまとめておく。
- 第1回「Dockerとは」(本記事)
- 第2回「Dockerを使ってみる」
- 第3回「Dockerコマンドの使い方」
- 第4回「Windowsプログラムを実行するWindowsコンテナ」
「Docker(ドッカー)」とは、非常に軽量なコンテナ型のアプリケーション実行環境である。dotCloud社(現Docker社)が開発し、2013年にオープンソースのプロジェクトとして公開された。ソフトウェアの高速な配布・実行や容易なイメージのカスタマイズ、導入運用の手軽さ、豊富なプレビルドイメージの提供などの理由により、当初はソフトウェアの開発やテスト段階における利用が多かったが、現在ではパブリッククラウドからオンプレミスシステムまで、さまざまなシーンで急速に普及しつつある。
- Docker[英語](docker.com)
軽量なコンテナ型の仮想化環境Docker
独立したアプリケーション実行環境といえば、PCのハードウェア全体を仮想化して、その上でOSやアプリケーションなどを動作させる仮想実行環境を真っ先に思い浮かべることが多いだろう。ハイパーバイザ型(Hyper-Vなど)やホスト型(VMware PlayerやWindows Virtual PC、VirtualBoxなど)がある。だがこの方式では、目的のアプリケーションとは関係のないサービスなども多数動作することになり、オーバーヘッドが大きく、リソースも無駄に多く必要になりがちだ。
これに対してコンテナ型の仮想化環境とは、Linuxカーネルが持つ「コンテナ」機能などを使って、実行環境を他のプロセスから隔離し、その中でアプリケーションを動作させる技術である。
コンテナはLinuxの通常のプロセスとほぼ同じものだが、利用できる名前空間やリソースが他のプロセスやコンテナからは隔離され、それぞれ固有の設定を持てるようになっている。そのためコンテナ内のアプリケーションから見ると、独立したコンピュータ上で動作しているように振る舞う。コンテナを管理するコストはプロセスを管理するコストとほとんど変わらず、仮想マシンを管理するコストと比較すると非常に軽い。
コンテナはLinuxカーネルが持つ次の機能を利用して実現されている。
■名前空間の隔離機能
ファイルシステムやコンピュータ名、ユーザー名(ユーザーID)、グループ名(グループID)、プロセスID、ネットワーク機能などを、コンテナごとに独自に設定できるようにする機能。
■リソースの隔離機能
CPUやメモリ、ディスク入出力など、コンテナ内で利用するリソースを他のコンテナから隔離したり、設定に基づいて振り分けたりする機能。
Dockerでは、最終的なアプリケーションはホストOS上の1つのプロセスとして実行されているため、余計なオーバーヘッドがない。
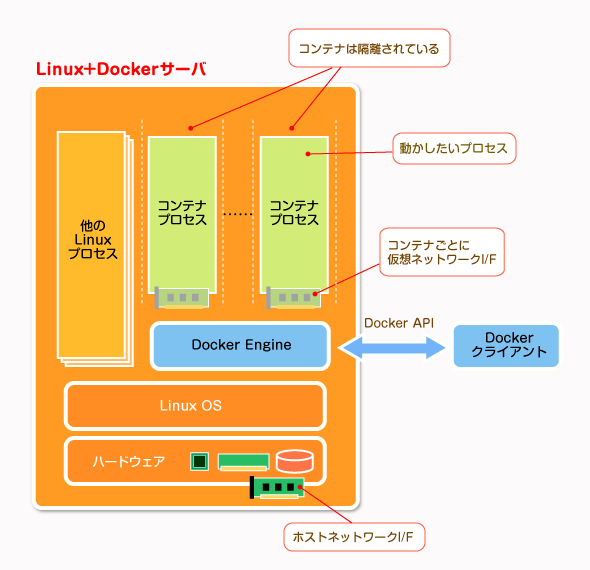 Dockerの実行環境
Dockerの実行環境Dockerでは、最終的なアプリケーションはホストOS中の1プロセスとして実行されているため、余計なオーバーヘッドがない。ただし通常のLinuxのプロセスと違って、Linuxカーネルのサポートする「コンテナ」技術などをベースにしている。コンテナは、他のプロセスからは隔離された、ある程度独立したプロセス実行環境である。コンテナごとにファイルシステムやネットワークインタフェース、名前空間などが独立している。図中の「Docker Engine」はDockerのコンテナの実行をサポートするためのモジュールであり、外部からはDocker APIを使って制御される。Docker機能をインストールして、コンテナを実行できるようにしたLinuxシステム全体をまとめてDockerホストと呼ぶ。1つのDockerホスト内では複数のコンテナを実行できる。
参考のために、ハイパーバイザ型やホスト型の仮想実行環境の例を次に挙げておく。この環境では、仮想化されたハードウェア上でLinux OSが動作し、さらにその上で目的のアプリケーションのプロセスが動作している。アプリケーションを実行するためにはまずゲストOSを稼働させなければならず、起動に時間もかかるし、CPUやメモリ、ディスクなどのリソースも多く消費する。
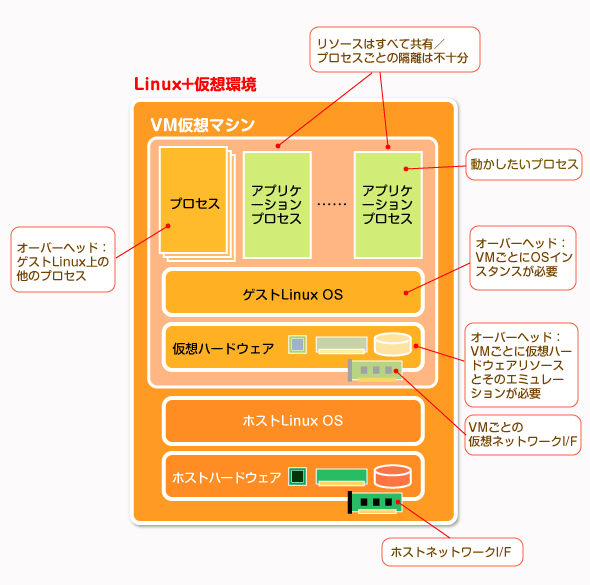 ハードウェア仮想化型の仮想実行環境
ハードウェア仮想化型の仮想実行環境ハイパーバイザ型やホスト型の仮想実行環境では、ホストOS上でまず仮想的な仮想マシン環境を作成/実行し、さらにその中でゲストOSを実行している。最終的なアプリケーション(図中のアプリケーションプロセスの部分)を動かすために、仮想マシンやゲストOSを実行させねばならず、それら全てがオーバーヘッドとなる。
Dockerイメージとは?
Dockerではアプリケーションとその実行環境、展開/操作方法(スクリプト)などをまとめて1つのパッケージにし、それを「Dockerイメージ」として保存/配布している。イメージは公式な「リポジトリ」で配布されているもの(ベースイメージ)を取得してきてもよいし、自作することもできる。
DockerイメージをDocker Engine上で起動したものがDockerのコンテナになる。そのコンテナ内で必要なアプリケーションをインストールして、各部をカスタマイズした後、それをディスクに保存すれば、新しいDockerイメージとして利用できる。イメージファイルは互換性が高く、これは基本的にはどのDockerホスト上でも動作する。
ただしこの方法は、既に存在するイメージや新しいベースイメージをカスタマイズしたり、コンポーネントをバージョンアップしたりする場合には不便である。手動でカスタマイズした内容を、新しいイメージに対してもう一度適用しなければならないからだ。
こんな場合はDockerfileというスクリプト機能を使うことになる。このファイル中には、イメージに対して適用する指示を記述しておく。例えばRubyとMySQLのパッケージを追加し、さらにapp1コマンドを実行する、というようなスクリプトを記述しておく。Dockerfileをベースとなるイメージに適用すれば、いつでも簡単に同じソフトウェア環境をすぐに用意できることになり、これはDevOps的なアプローチにも有用だ。Dockerfileについては第3回で説明する。
Dockerイメージの履歴管理
Dockerのコンテナ中ではイメージ中のファイルシステムは全て書き込み禁止になっており、書き込まれた内容は全て新しい「レイヤー」に保存される。元のイメージの内容を保ったまま、更新された差分データだけを別ファイルとして取り扱うので、少ないディスク領域で多数のコンテナの実行が可能となる。
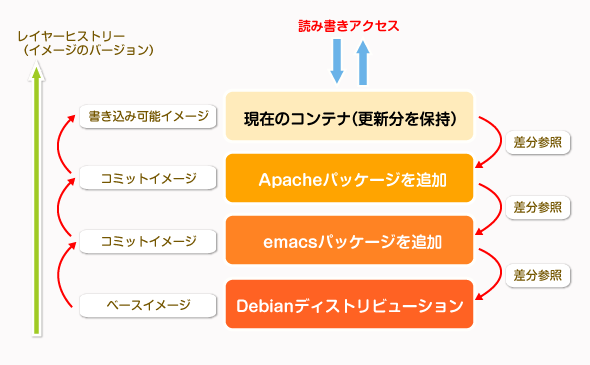 レイヤー化されているDockerのファイルシステム
レイヤー化されているDockerのファイルシステムDockerではイメージに書き込みを行うと、それは新しいレイヤーとして保存される。レイヤーを「コミット(書き込み、確定)」して新しいイメージを作成したり、以前のイメージに戻したりといったことが簡単に行える。
レイヤーの内容は適宜「コミット」することにより、新しいイメージとして保存できる。これにより、ソフトウェアのバージョン管理のように、すぐに以前のイメージに戻したり、新しい派生版で試験したりといったことが簡単にできるようになっている。
Dockerクラスタを管理するDocker Swarm
Dockerが開発やテスト工程だけで使われていた段階では、Dockerを管理することはそう難しいことではなかった。Dockerサービスが稼働しているマシンもコンテナ数も限られていたため、dockerコマンドを使って手動で管理することも十分可能だった。
しかしDockerが普及するにつれ、クラウドやクラスタ構成の本番環境でもDockerが利用されるケースが増えてきている。そのため、多数のコンテナをまとめて管理したり、監視したりする必要性が高くなっている。
このような要求に応えるため、現在のDockerには「Docker Swarm」という機能が導入されている。これは、複数のノード(コンテナを実行するホスト)をまとめて1つのクラスタとして管理する機能だ。
これ以外にも、Dockerをクラスタとして管理できるサービスやツールなどは数多い。ただ、いずれもDocker入門という範囲を超えるので、本記事では触れない。興味があるなら、以下の記事などを参照のこと。
- 「コンテナ運用環境を標準化? CNCFは何をやろうとしているか」(@IT System Designフォーラム)
- 「CNCFのCOOに聞いた、CNCFとOCI、Docker、Kubernetes、Cloud Foundryとの関係」(@IT System Designフォーラム)
今回はDockerの概要について見てきた。より進んだDockerの利用方法については、以下の記事などを参照していただきたい。
- 「無償のDocker for Windowsで手軽にLinuxコンテナを利用する」
- 連載「いまさら聞けないDocker入門」(@IT Linux & OSSフォーラム)
→第2回「Dockerを使ってみる」へ
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。