第1回 人工知能・機械学習・ディープラーニングとは? 基礎概念まとめ:Deep Insiderオピニオン:吉崎亮介
Microsoft・Preferred Networks公認のデータサイエンス人材養成トレーナーであるキカガク吉崎氏による「機械学習」コラム連載がスタート。ビジネス視点も踏まえつつエンジニア向けにAI・ディープラーニングを実践で活用する方法を紹介していく。まずは基礎概念から理解しよう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
ご注意:本記事は、@IT/Deep Insider編集部(デジタルアドバンテージ社)が「www.buildinsider.net」というサイトから、内容を改変することなく、そのまま「@IT」へと転載したものです。このため用字用語の統一ルールなどは@ITのそれとは一致しません。あらかじめご了承ください。
はじめに
空前の人工知能(AI)ブームにより、日本各社では「AIを導入しよう!」と叫ばれるようになりました。そのような時代の流れの中、AIを正しく理解できている方が実は少ないと感じています。難しい数学やプログラミングをしっかりと理解している人が少ないという意味ではなく、「ビジネスの目標設定に対して、AIを手段として適切に提案できる方」が少ないのではないでしょうか。
しかし、いざ勉強しようと参考書を手に取られるのですが、数式が難しく見えてしまって結局諦めてしまう方が跡を絶ちません。「お客様先に提案したいけれど、そもそも何ができるか分からないし、勉強しようとしても参考書が難しい。しかも有識者の大学の先生に質問しても、前提知識がなさすぎて全然ついていけない。」……こんな経験をされている方も多いのではないでしょうか。
そこで、本シリーズでは、まず「AIとは何か?」「どういった準備が必要か?」「導入時によくある、思わぬ落とし穴は何か?」といったビジネスパーソンとしての視点も踏まえながら、またエンジニアの方向けにどのような方法で実装していくことができるかといった具体的な手順についてもお伝えする盛りだくさんな内容としていきます。
それでは初回である今回は、「人工知能・機械学習・ディープラーニング」についてしっかりと位置づけを押さえていきましょう。
人工知能(AI)・機械学習・ディープラーニングとは?
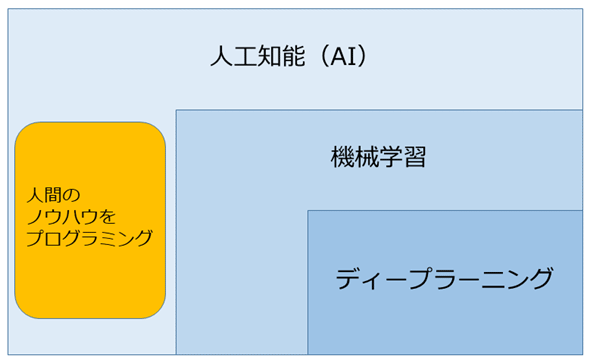 図1 人工知能(AI)・機械学習・ディープラーニングの関係概念図
図1 人工知能(AI)・機械学習・ディープラーニングの関係概念図 人工知能(AI)
人工知能が3つの概念の中で最も大枠となり、人間のように学習や推論を行わせる概念を指します。
「人工知能」と言えば、最近でこそ、収集したデータに基づいて学習させるデータ駆動型のイメージが強いですが、本来の意味はそれだけではありません。例えば、人間が学習・習得した知識・ノウハウをプログラミングすることにより形式化・再現可能にして、それをコンピューターで動かすことも「一種の人工知能」と言えます。もちろん、この後で紹介する機械学習のように、集めたデータに基づいて(データ駆動型で)コンピューター自身が学習も行って、学習した結果に基づいて推論を行う場合も「人工知能」と言えます。
このように、人工知能という言葉が指す範囲は非常に広いわけです。ですから、「AIで何かしよう!」といったプロジェクトではなく、「機械学習により電力量の需要を予測することで運用のオペレーションを改善し、1%のコスト削減を目指そう」といった具体的な目標設定が必要となります。
機械学習
収集したデータに基づいて、モデルの学習を行う仕組みのことを機械学習と呼びます。
「モデルの学習」という曖昧な表現でしたが、具体的には、定式化した数式のパラメーターを、収集したデータに基づいて、ある定めた評価関数(誤差など)を最小化するように決定することを指しています。先述したデータ駆動型の学習や推論を行う仕組みが機械学習です。
機械学習には、
- 教師あり学習
- 教師なし学習
- 強化学習
の3つのトピックがあります。
入力xから出力yを予測する仕組みである教師あり学習が、ビジネスの場でよく使われているため、これから勉強される方は、まずこちらから調べてみてください。
AlphaGoが囲碁で人間に勝利して以来、強化学習も注目を浴びるようになってきていますが、ゲームやロボット系の分野以外では、まだまだ実用的な技術ではないと感じています。理由としては、強化学習の考え方や実装自体はそれほど難しくないのですが、強化学習ではシミュレーター、もしくは実機が必要となり、これらを割と手軽に準備できる業界がゲームやロボットに限られているためです。
ディープラーニング
機械学習、例えば教師あり学習における問題設定は、「入力と出力の関係性を見つける」といったものですが、これはあくまで概念であり、具体的な手順は明らかになっていません。そこで実際にコンピューターが実行できるレベルまで具体的な手順を明確化したものを、アルゴリズムと呼びます。
そして、この機械学習アルゴリズムの一部がディープラーニングです。もちろん、ディープラーニング以外にもサポートベクターマシンやロジスティック回帰といった他の機械学習アルゴリズムも存在し、ディープラーニングは一手段であることをしっかりと覚えておきましょう。
最近では、「ディープラーニングを使って、問題を解決したいのですが」といった相談も少なくありません。しかし、その前に、その問題が本当にディープラーニングによって解決すべきか、それ以外の古典的な手法でも解決できるかを見極めておく必要があります。
ビジネスとして相談を受ける大半の例では、ディープラーニングは不要なケースが多いと感じています。ただし、画像や時系列、自然言語処理といったメディアと結びつきの強い分野では、ディープラーニングが非常に有用なケースがあります。
学習と推論とは?
人工知能を勉強すると必ず出てくるキーワードとして、先述した学習と推論があります。
「どういったことを行うのか?」という具体的なイメージ(=推論したいこと、問題設定)を持っておくことで、実際に現場へ導入する際に、「どういった情報を集めるべきか」(=学習すべきデータ)が明確になるため、今回はこの学習と推論に焦点を当てましょう。
学習
学習では、ある入力と出力に対して情報をひもづけてあげるために、「この入力を行うとこの出力が得られる」といったデータを渡して、その規則性を見つけることを行います。
具体的な例を見てみましょう。ここでは、入力用の学習データとして「吉崎」と「今西」という2人(図2)の人物写真を使うこととします。
 図2 左がキカガクの「今西」、右が「吉崎」
図2 左がキカガクの「今西」、右が「吉崎」 今回の例では、ある画像(1人が写った顔写真)を入力として、この画像内に写っている人間が「吉崎」か「今西」かを分けたいという問題を設定するとにします。人間の目では全く難しくない問題ですが、これがコンピューターにとっては案外難しかったりします。
人間の知識・ノウハウをプログラミングする方法
それでは、まず機械学習ではない人間の知識によるプログラミングの例から見てみましょう。
画像だけを見ると、「吉崎」と「今西」を分けるためには、Tシャツの色で判断する方法を採用できそうに思えますが、Tシャツを着替えると、この方法が通用しなくなります。人間であれば、「人間は色の異なる服を着替えることもある」という事前の知識・ノウハウがあるため、この方法は避けるでしょう。そして、肌の色や顔の面積などを画像処理によって取得し、例えば、「おでこの面積が○○よりも大きければ吉崎」「肌の色が○○よりも白ければ今西」といった判断を下すためのプログラムを書くことになります。
これが「人間のノウハウをプログラミングする」方法です。
収集したデータに基づいて学習し、その結果から推論する方法(機械学習)
一方、機械学習では、コンピューターで扱うために、画像の情報をまず数値に変換します。
そのためには、「画像はどのような数値で表現されるのだろうか?」という情報、つまりデータの特性が分かっていないと、そもそも機械学習を使うまでに至ることができません。ちなみに、画像はRGB(Red/Green/Blue)で表される光の三原色に対する光の強さ(輝度)を定量評価することで数値に落とし込むことができます。
教科書で紹介されていることはあまりありませんが、こういったデータの特性を考えることは、機械学習を実装していく上で非常に重要なため、「身の回りの現象を定量評価するにはどうするのか?」といった観点で、物事を見る練習をしてみましょう。宿題として、「キカガク」という文字は数値でいうといくらでしょうか? ということについて考えてみてください(※決まった正解はありません)。
話を戻すと、この数値を今度は特徴量と呼ばれる別の指標に変換します。例えば、顔の輪郭だけ抽出するとか、画像内の肌色の数をカウントしてみるとか、いろいろな方法があり得ます。この特徴量の抽出が、推論の結果、この例では「吉崎」と「今西」をうまく判別できるかを大きく左右します。
そして図3に示すように、この特徴量を入力として、それに対する出力(「この画像は『吉崎』である」といった出力)も1セットで、モデルに与えます。
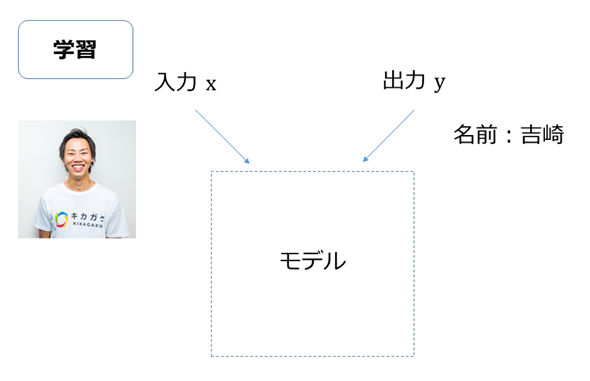 図3 AIを独自に開発する場合(1): 画像から「吉崎」を学習させる例
図3 AIを独自に開発する場合(1): 画像から「吉崎」を学習させる例 もちろん1枚だけではコンピューターは規則性を見つけられないため、他にもいろいろな角度で撮った写真を数十枚〜数百枚、多いときには数万枚ほど準備してコンピューターに学習をさせます(例えば図4は「今西」を学習させるための1セットで、こういった学習を多数行っていきます)。
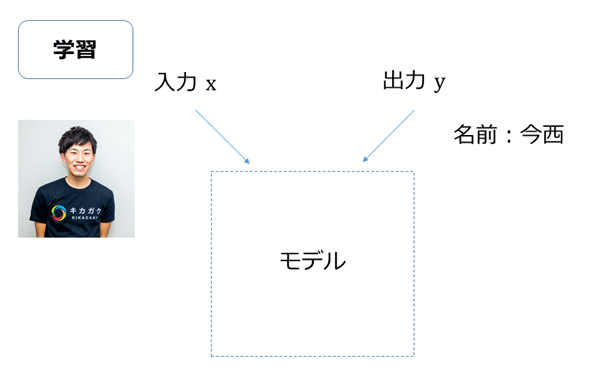 図4 AIを独自に開発する場合(2):画像から「今西」を学習させる例
図4 AIを独自に開発する場合(2):画像から「今西」を学習させる例 そして、この学習によって学習済みモデルが完成します。
推論
学習後に、学習済みモデルを使用して、新しい画像に対してその予測値を求めることを推論と言います。具体的には図5のように、新しい画像が入ってきた際に、学習済みモデルに基づいて、「吉崎」といったような予測が行われます。
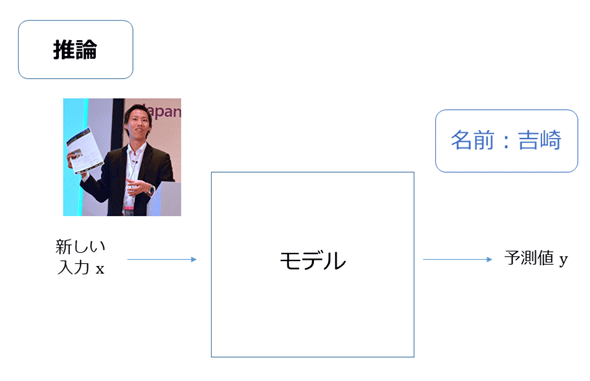 図5 AIを独自に開発する場合(3): 推論の例
図5 AIを独自に開発する場合(3): 推論の例 AI搭載のプロダクトには、この学習済みモデルによる推論が組み込まれているわけです。
学習には時間がかかります。しかし推論には、この学習済みモデルを使用した計算のみのため、基本的にほとんど時間がかからないといったメリットがあります。
よくある落とし穴
よく受ける相談として「過去数十年分で蓄積されているデータを使用して何か予測できるモデルを作りたい」というお題があります。こういった方の特徴として、「AIは何かデータを与えれば自動的に有用な情報を返してくれる」といった淡い期待があります。
しかし今回、学習と推論を勉強していただいた皆さんであればお分かりの通り、何かデータがあれば自動的に何かが予測できるわけではありません。まず「何(出力)を予測するのか」「そのために何(入力)が必要か」を事前に決定し、目的にあった学習データを準備しておく必要があります。
まずビジネスの課題から考えて、「何から何を予測するのか」を正しく設定すること。これが、成功する機械学習の第1ステップです。
おわりに
今回はAIにまつわる概念を中心に紹介しました。
次回は、このAIを習得するために必要なスキルセットについて紹介していきますので、楽しみにしていてください。それでは、また次回お会いしましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。