Pythonの機械学習ライブラリ「scikit-learn」で実践する「教師あり学習」「教師なし学習」:Pythonで始める機械学習入門(7)(2/3 ページ)
教師あり学習
「教師あり学習」とは、特徴量と、それに対応する予測を行おうとする値(ターゲット)が訓練データとして与えられている場合の学習のことです。
例えば前述のあやめデータでは、花の寸法の測定値とあやめの種類の組みが訓練データとして与えられて、それを使ってモデルを学習させるのは教師あり学習です。
教師あり学習の中でも、特にターゲットの値の大小関係に意味がないのが「分類」と呼ばれるタスクです。あやめデータではターゲットに0、1、2という品種を表す数値が含まれていますが、これは「同じ数値は同じ品種である」というだけで大小関係に意味がありません。この品種を予測しようというのが分類タスクです。
一方で、ターゲットの大小に意味があるのは「回帰」と呼ばれるタスクです。例えば人間の体重から身長を予測するというのは回帰に当たります。
線形回帰
「線形回帰」とはデータの分布を線形関数で近似する手法です。ここで使うデータとして、あやめデータのインデックス0と2の特徴量(ガクの長さと花びらの長さ)を使います。それらの値を平面上にプロットしてみます。
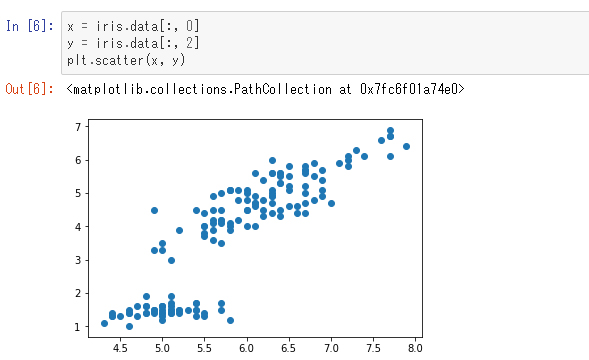
このデータを、線形回帰を使って直線で近似にします。

ここで「model.coef_」は係数で、「model.intercept_」は切片に当たります。この直線の式を「y = ax + b」とすると、「a」に当たるのが「model.coef_[0]」であり、「b」に当たるのが「model.intercept_」です。一般に特徴量(この場合の「x」)は多次元になるのでベクトルaを使って「y = a・x + b」(ここで・は内積)となるので「coef_」は配列となっています。
このモデルによって新しいデータに対する予測もできるようになります。例えば花びらの長さが6.5センチのあやめにおけるガクの長さを予測してみましょう。

約4.98センチと予測されました。
サポートベクターマシン
まずは、がくの幅と花びらの幅の関係について、あやめの種類ごとに可視化してみます。
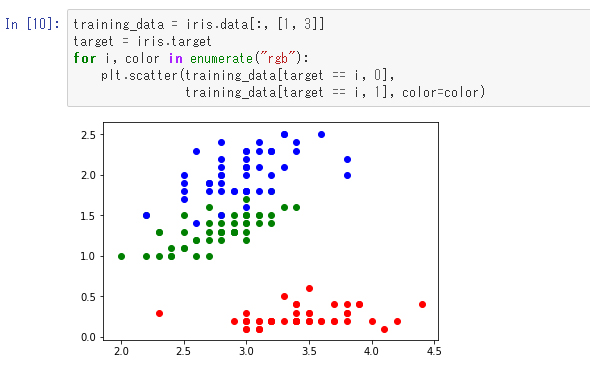
これを「サポートベクターマシン」というアルゴリズムを使って分類してみます。

これで学習が終わりました。この学習させたモデルを使って座標平面を色分けしてみます。

ここでは、学習の結果の分類を色の塗り分けで示していて、学習データの点は対応する色が塗られた丸で示しています。青い点が4個ほど緑の方に入っていて、緑の点が1個青の方に入っていますが、おおむね正しく分類できているのが分かります。
教師あり学習の評価
ここまで回帰と分類の例をそれぞれ見てきましたが、学習させたモデルが妥当であるかはどのように判定すればよいのでしょうか。
機械学習アルゴリズムの性能は、「未知のデータについて、どのくらい正しく予測できるか」によって評価されます。従って、「幾つかのデータを評価用として分離して、それを取り除いたものを訓練用データとして使い、それで学習した後に評価用データで評価する」手法がよく行われます。これは「ホールドアウト検証」と呼ばれるものです。
scikit-learnには評価用のデータを抽出するための関数も用意されています。

評価用のデータを取り出して訓練用と分離しました。ここで、「train_test_split」関数の名前付き引数「test_size」は全体に対する評価用データの割合で、「random_state」は乱数の種(つまり、この関数を何度呼んでも同じ結果にするようにするためのもの)を意味しています。結果は「X_train」と「y_train」に訓練用データが入っており、「X_test」と「y_test」に評価用データが入っています。ここでは、それぞれのサイズを表示して確認しています。では、今度は4つの特徴量全てを使ってサポートベクターマシンで学習させてみます。
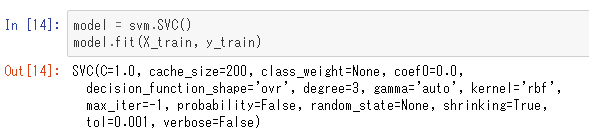
この学習したモデルがどの程度評価用データを正確に予測できるかを調べるにはscoreというメソッドがあります。

この「1.0」という数字は全ての予想が当たったということです。データが単純なのでこうなりましたが、一般にはあまり起こることではありません。
ところで、実は上記の「SVC」クラスには「C」という引数があり、学習時の振る舞いを決定するパラメーターを意味しています。このように最初に指定して学習の途中では変化しないパラメーターを「ハイパーパラメーター」と呼びます。「ハイパーパラメーターとしてどの値を設定すべきか」は実験により決めるのが普通ですが、上記のようなホールドアウト検証では固定された評価データに対して過学習してしまう可能性があり、代わりに「交差検証(クロスバリデーション)」という手法が使われることがあります。
「k分割考査検証」とは、データをk個に分割して、そのうちのi番目を評価用とし残りを訓練用として評価する、ということをiが1からkまで繰り返すという手法です。k回評価するので、モデルの評価としてはその平均値を取るのが普通です。scikit-learnには交差検証用の関数も用意されています。以下にその使用例を見てみます。

交差検証のための関数「cross_val_score」で、名前付き引数の「cv」は分割数を意味しています。従って、このcvで指定した回数評価が行われるので、戻り値は要素数がcv個の配列になります。ここでは配列の中身と平均を比較しています。
関連記事
 機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
本連載では、さまざまなソフトウェアのインストール、実行するためのセットアップ設定、実行確認、アンインストールの手順を解説する。今回は、Pythonとは何か、Pythonのインストールとアンインストールについて解説。Pythonがよく使われる機械学習やビッグデータ解析を始める参考にしてほしい。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。