Pythonの機械学習ライブラリ「scikit-learn」で実践する「教師あり学習」「教師なし学習」:Pythonで始める機械学習入門(7)(1/3 ページ)
最近流行の機械学習/Deep Learningを試してみたいという人のために、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説する連載。今回は、Pythonの機械学習ライブラリ「scikit-learn」を使って「教師あり学習」「教師なし学習」などについて説明します。
プログラミング言語「Python」は機械学習の分野で広く使われており、最近の機械学習/Deep Learningの流行により使う人が増えているかと思います。一方で、「機械学習に興味を持ったので自分でも試してみたいけど、どこから手を付けていいのか」という話もよく聞きます。本連載「Pythonで始める機械学習入門」では、そのような人をターゲットに、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説しています。
連載第1回の「Pythonで機械学習/Deep Learningを始めるなら知っておきたいライブラリ/ツール7選」では、ライブラリ/ツール群の概要を説明しました。前回は、その中でもJupyter Notebookの基本操作と設定について説明しました。
連載第3回から第1回で紹介した各種ライブラリを使う具体的なコードを例示していますが、Jupyter Notebook形式で書いています。
今回は「scikit-learn」を使った機械学習について説明します。scikit-learnは、機械学習の有名なアルゴリズムを多く含んでおり、また機械学習に必要なデータ処理などのツールも提供しています。

前回までと同様、次のように「NumPy」「Matplotlib」をインポートしておきます。

なお本稿では、Pythonのバージョンは3.x系であるとします。
あやめデータ
以下の解説では、主にscikit-learnに付属している「あやめ」のデータ(irisデータ)を使って説明します。このデータは、あやめの花の幾つかの箇所の寸法と、その品種についての情報を含んでいます。
まずは次のようにしてあやめデータを読み込みます。

これで変数irisにあやめデータが入れられました。このメンバ変数「DESCR」にはデータに関する説明が入っているので見てみましょう。
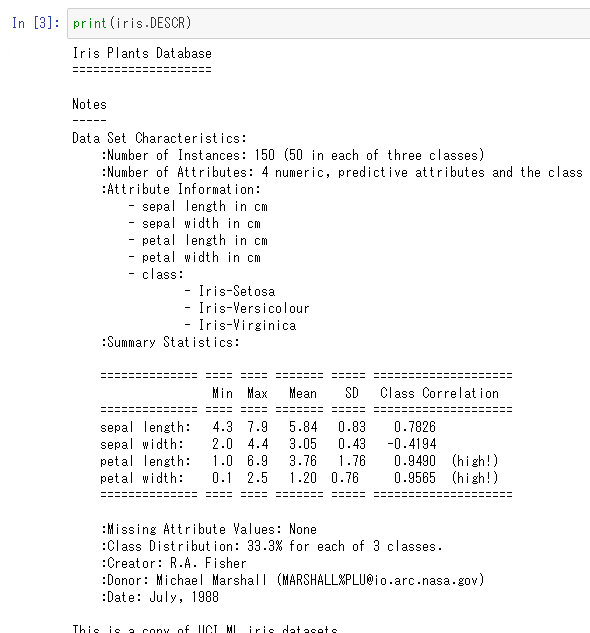
冒頭の部分の概訳は次のようになります。
データセットの特徴:
:インスタンスの数:150(各クラスについて50個ずつ)
:属性の数:予測のための数値が4つと、クラスが1つ
:属性の情報:
- ガクの長さ
- ガクの幅
- 花びらの長さ
- 花びらの長さ
- クラス(あやめの3つの種類「Setosa」「Versicolour」「Verginica」のいずれか)
ここで「クラス」とは、花に与えられる「分類ラベル」のことです。では実際の属性のデータを見てみます。特徴量に当たる4つの属性は次のようになっています。
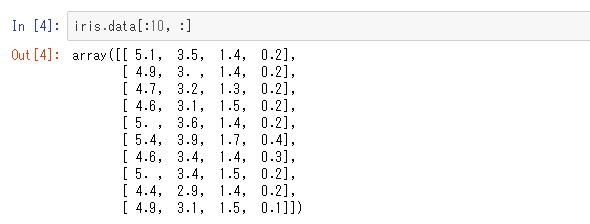
このように特徴量はメンバ変数「data」に入っています。各行が1つの花の個体に対応しています。ここでは最初の10行分だけを表示しています。
次にラベルの値を表示してみます。

このようにラベルはメンバ変数targetに入っています。この0、1、2という数字は「各サンプルが、どの種類のあやめに属するか」を表しています。
関連記事
 機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
本連載では、さまざまなソフトウェアのインストール、実行するためのセットアップ設定、実行確認、アンインストールの手順を解説する。今回は、Pythonとは何か、Pythonのインストールとアンインストールについて解説。Pythonがよく使われる機械学習やビッグデータ解析を始める参考にしてほしい。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。