第8回 分類問題をディープラーニング(基本のDNN)で解こう:TensorFlow 2+Keras(tf.keras)入門(3/3 ページ)
―――【二値分類編】―――
多くのコードは前ページと重複するので、説明は極力なしで、書き換えたコードのみを太字で示していく。コード自体は全体を掲載するので長いが、太字以外は読み飛ばしていただいて構わない。
(6)データの準備
二値分類問題では「MNIST」データセットを用いる(図14)。

データの仕様は同じであるが、分類カテゴリーが次のように変わる。
- ラベル「0」: 手書き数字「0」
- ラベル「1」: 手書き数字「1」
- ラベル「2」: 手書き数字「2」
- ラベル「3」: 手書き数字「3」
- ラベル「4」: 手書き数字「4」
- ラベル「5」: 手書き数字「5」
- ラベル「6」: 手書き数字「6」
- ラベル「7」: 手書き数字「7」
- ラベル「8」: 手書き数字「8」
- ラベル「9」: 手書き数字「9」
先ほどとほぼ同じコードでデータを導入できる(リスト6-1)。二値分類なので、2個の分類カテゴリーしか要らない。よって、ラベルが「0」「1」以外はカットするフィルタリング処理を追記している。
# TensorFlowライブラリのtensorflowパッケージを「tf」という別名でインポート
import tensorflow as tf
import matplotlib.pyplot as plt # グラフ描画ライブラリ(データ画像の表示に使用)
import numpy as np # 数値計算ライブラリ(データのシャッフルに使用)
# Fashion-MNISTデータ(※NumPyの多次元配列型)を取得する
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
# データ分割は自動で、訓練用が6万枚、テスト用が1万枚(ホールドアウト法)。
# さらにそれぞれを「入力データ(X:行列)」と「ラベル(y:ベクトル)」に分ける
# データのフィルタリング
b = np.where(y_train < 2)[0] # 訓練データから「0」「1」の全インデックスの取得
X_train, y_train = X_train[b], y_train[b] # そのインデックス行を抽出(=フィルタリング)
c = np.where(y_test < 2)[0] # テストデータから「0」「1」の全インデックスの取得
X_test, y_test = X_test[c], y_test[c] # そのインデックス行を抽出(=フィルタリング)
# ※訓練データは、学習時のfit関数で訓練用と精度検証用に分割する。
# そのため、あらかじめ訓練データをシャッフルしておく
p = np.random.permutation(len(X_train)) # ランダムなインデックス順の取得
X_train, y_train = X_train[p], y_train[p] # その順で全行を抽出する(=シャッフル)
# [内容確認]データのうち、最初の10枚だけを表示
classes_name = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
plt.figure(figsize=(10,4)) # 横:10インチ、縦:4インチの図
for i in range(10):
plt.subplot(2,5,i+1) # 図内にある(sub)2行5列の描画領域(plot)の何番目かを指定
plt.xticks([]) # X軸の目盛りを表示しない
plt.yticks([]) # y軸の目盛りを表示しない
plt.grid(False) # グリッド線を表示しない
plt.imshow( # 画像を表示する
X_train[i], # 1つの訓練用入力データ(28行×28列)
cmap=plt.cm.binary) # 白黒(2値:バイナリ)の配色
plt.xlabel(classes_name[y_train[i]]) # X軸のラベルに分類名を表示
plt.show()
先ほどと同様に、訓練データの1つ目の入力データとラベルを、出力して確かめてみる(リスト6-2)。
import pandas as pd # データ解析支援「pandas」
# 1件の訓練データの、ラベルと入力データを表示する
print('y_train(正解ラベル): 「',y_train[0],'」');
print('X_train:');
display(pd.DataFrame(X_train[0])) # NumPy多次元配列をpandasデータフレームに変換して表示
出力結果、筆者の場合は図15のように表示された(※訓練データはシャッフルしたので、結果が人によって異なる)。

入力データの正規化(Normalization)
何も変更していない。
X_train = (X_train / 255.0).astype(np.float32)
X_test = (X_test / 255.0).astype(np.float32)
(7)モデルの定義
ディープニューラルネットワークのモデル設計
ニューラルネットワークのモデル設計は、以下の仕様とする。出力層のニューロン数が、多クラス分類では10個だったのが1個に変わった。
- 入力の数(INPUT_FEATURES)は、28行×28列(=784)になっているので、フラット化(Flatten)して784個
- 隠れ層のレイヤー数は、2つ
- 隠れ層にある1つ目のニューロンの数(LAYER1_NEURONS)は、128個
- 隠れ層にある2つ目のニューロンの数(LAYER2_NEURONS)は、32個
- 出力層にあるニューロンの数(OUTPUT_RESULTS)は、1個
出力層の活性化関数は、前述した通り、二値分類時に一般的に利用されるシグモイド関数を指定する。
以上の仕様に基づくニューラルネットワークのモデル設計コードは次のようになる。
import tensorflow as tf # ライブラリ「TensorFlow」のtensorflowパッケージをインポート
from tensorflow.keras import layers # レイヤー関連モジュールのインポート
from IPython.display import Image
# 定数(モデル定義時に必要となるもの)
INPUT_ROWS = 28 # 入力行の数: 28行
INPUT_COLS = 28 # 入力列の数: 28列
# 入力(特徴)の数: 784(=28行×28列)
LAYER1_NEURONS = 128 # ニューロンの数: 128
LAYER2_NEURONS = 32 # ニューロンの数: 32
#OUTPUT_RESULTS = 10 # 前述する多クラス分類の場合: 10(=「0」〜「9」の10クラスに分類)
OUTPUT_RESULTS = 1 # 出力結果の数: 1(=「0.0」〜「1.0」の2値に分類)
# 過学習対策でドロップアウトを使う場合はコメントオフ:
#DROPOUT1_RATE = 0.2 # 第1隠れ層から第2隠れ層へのドロップ率: 0.2(20%)
# 変数(モデル定義時に必要となるもの)
activation1 = layers.ReLU(name='activation1') # 活性化関数(隠れ層用): ReLU関数(変更可能)
activation2 = layers.ReLU(name='activation2') # 活性化関数(隠れ層用): ReLU関数(変更可能)
act_output = layers.Activation('sigmoid', name='act_output') # 活性化関数(出力層用): Sigmoid関数(固定)
# tf.keras.Modelによるモデルの定義
class NeuralNetwork(tf.keras.Model):
# レイヤー(層)を定義
def __init__(self):
super(NeuralNetwork, self).__init__()
# 入力層:入力データのフラット化(Flatten)
self.flatten_input = layers.Flatten( # 行列データのフラット化
input_shape=(INPUT_ROWS, INPUT_COLS), # 入力の形状(=入力層)※タプル形式
name='flatten_input')
# 隠れ層:1つ目のレイヤー(layer)
self.layer1 = layers.Dense( # 全結合層(線形変換)
# 入力ユニット数は、前の出力ユニット数が使われるので、指定不要
LAYER1_NEURONS, # 次のレイヤーへの出力ユニット数
name='layer1')
# 第1レイヤーの後でドロップアウトを使う場合はコメントオフ:
#self.dropput1 = layers.Dropout( # ドロップアウト
# DROPOUT1_RATE, # 何%ドロップするか
# name='dropput1')
# 隠れ層:2つ目のレイヤー(layer)
self.layer2 = layers.Dense( # 全結合層
LAYER2_NEURONS, # 次のレイヤーへの出力ユニット数
name='layer2')
# 出力層
self.layer_out = layers.Dense( # 全結合層
OUTPUT_RESULTS, # 出力結果への出力ユニット数
name='layer_out')
# フォワードパスを定義
def call(self, x, train_mode=True):
x = self.flatten_input(x) # 入力データのフラット化
# 「出力=活性化関数(第n層(入力))」の形式で記述
x = activation1(self.layer1(x)) # 活性化関数は変数として定義
#ドロップアウトを使う場合はコメントオフ:
#if train_mode: # 訓練時のみ……
# x = self.dropput2(x) # ……ドロップアウト(不活性化)
x = activation2(self.layer2(x)) # 活性化関数は変数として定義
x = act_output(self.layer_out(x)) # ※活性化関数は「softmax」固定
return x
# モデル内容の出力を行う独自メソッド
def get_static_model(self):
x = layers.Input(shape=(28,28), name='input_features')
static_model = tf.keras.Model(inputs=[x], outputs=self.call(x))
return static_model
定義したモデルを生成して内容を図で確認してみる(リスト7-2)。何も変更していない。
# モデル(NeuralNetworkクラス)のインスタンス化
model = NeuralNetwork()
# モデル概要の図を描画する
f_model = model.get_static_model()
filename = 'model.png';
tf.keras.utils.plot_model(f_model, show_shapes=True, show_layer_names=True, to_file=filename)
from IPython.display import Image
Image(retina=False, filename=filename) # 図で描画
#f_model.summary() # テキストで出力
これを実行すると、図16のように描画される。
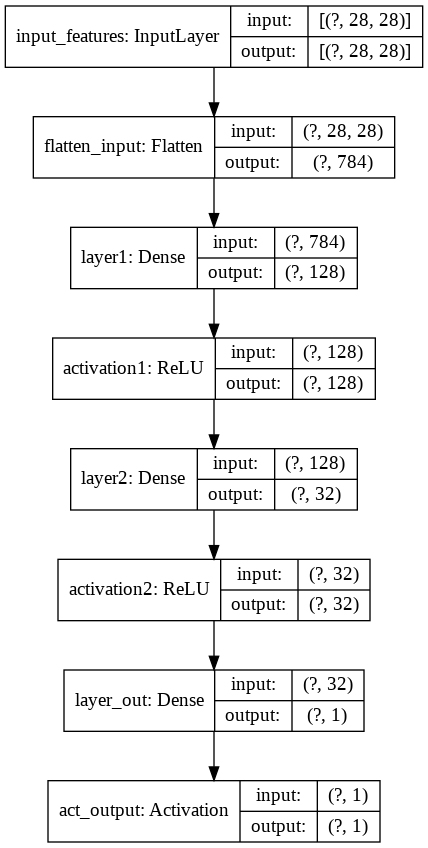 図16 モデル内容(図)の確認結果
図16 モデル内容(図)の確認結果(8)学習/最適化(オプティマイザ)
学習に関するコード(リスト8-1)については、損失関数が二値分類用の交差エントロピーである'binary_crossentropy'に変わっている。
# 定数(学習方法設計時に必要となる数値)
LOSS = 'binary_crossentropy' # 損失関数:二値分類用の交差エントロピー
METRICS = ['accuracy'] # 評価関数:正解率
OPTIMIZER = tf.keras.optimizers.Adam # 最適化:Adam
LEARNING_RATE = 0.001 # 学習率: 0.001(学習率の調整)
# 学習方法を定義する
model.compile(optimizer=OPTIMIZER(learning_rate=LEARNING_RATE),
loss=LOSS,
metrics=METRICS) # 精度(分類では正解率。回帰では損失)
続いて、fit()メソッドを呼び出して、トレーニングを実施する(リスト8-2)。何も変更していない。
# 定数(ミニバッチ学習時に必要となるもの)
BATCH_SIZE = 96 # バッチサイズ: 96
EPOCHS = 100 # エポック数: 100
# 早期終了
#es = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=3)
# 学習する
hist = model.fit(x=X_train, # 訓練用データ
y=y_train, # 訓練用ラベル
validation_split=0.2, # 精度検証用の割合:20%
batch_size=BATCH_SIZE, # バッチサイズ
epochs=EPOCHS, # エポック数
verbose=1, # 実行状況表示
callbacks=[]) # コールバック(早期終了しない場合)
#callbacks=[es]) # コールバック(早期終了する場合)
トレーニングの実行状況については割愛する。
(9)評価/精度検証
「損失」と「正解率」のグラフ描画を行う(リスト9-1)。何も変更していない。
import matplotlib.pyplot as plt
# 学習結果(損失=交差エントロピー)のグラフを描画
plt.figure()
train_loss = hist.history['loss']
valid_loss = hist.history['val_loss']
epochs = len(train_loss)
plt.plot(range(epochs), train_loss, marker='.', label='loss (training data)')
plt.plot(range(epochs), valid_loss, marker='.', label='loss (validation data)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss (cross entropy)')
# 評価関数(正解率)のグラフを描画
plt.figure()
train_mae = hist.history['accuracy']
valid_mae = hist.history['val_accuracy']
epochs = len(train_mae)
plt.plot(range(epochs), train_mae, marker='.', label='accuracy (training data)')
plt.plot(range(epochs), valid_mae, marker='.', label='accuracy (validation data)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
このコードを実行すると、筆者の場合は図17のようなグラフが描画された。
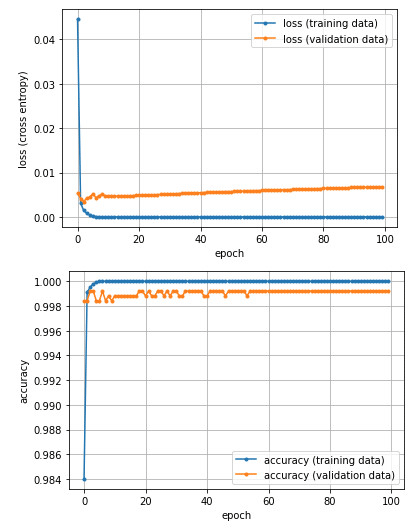 図17 学習結果(損失の履歴)のグラフ描画
図17 学習結果(損失の履歴)のグラフ描画かなり早い段階で、低い損失値、高い正解率となっており、そこからは過学習となっていることが分かる。
(10)推論/未知データによるテスト
何も変わっていない。
#BATCH_SIZE = 96 # バッチサイズ(リスト3-2で定義済み)
# 未知のテストデータで学習済みモデルの汎化性能を評価
score = model.evaluate(X_test, y_test, batch_size=BATCH_SIZE)
print('test socre([loss, accuracy]):', score)
# 出力例:
# 23/23 [==============================] - 0s 2ms/step - loss: 0.0030 - accuracy: 0.9995
# test socre([loss, accuracy]): [0.002963468199595809, 0.9995272159576416]
実運用のイメージ
今回は、Colab(Webアプリ)上で手書き文字を読者自身で入力したものをJPEG画像として取得し、それを入力データとして使えるようにしてみよう(図18)。
 図18 手書き文字を読者自身で入力
図18 手書き文字を読者自身で入力機械学習の範囲を超えているので、概要だけ説明する。リスト10-2は、Canvas(キャンバス)というHTMLテクノロジーを使って、それを実現するコードである。マウスの動きを検出して、キャンバス上に線を描画している。[削除]ボタンがクリックされたらキャンバスをクリアし、[このデータを保存]ボタンがクリックされたらキャンバス内容をJPEG画像として取得している。
JPEG画像はBASE64形式のテキストとなっており、取得するたびに、そのテキストをColab上に出力するようにした。ちなみに、BASE64形式テキストをChromeなどのブラウザーのアドレスバーに指定して実行するとJPEG画像が表示される。それをダウンロードすることで、好きなだけオリジナルの手書き文字画像が作成できる。
BASE64形式テキストの取得はHTMLコード上で行っているが、事前にPython側のBase64image()関数をColab機能のコールバック関数として仕込むことで、[このデータを保存]ボタンがクリック時の処理コードに継続してPythonコードが動く仕組みになっている。Base64image()関数では、画像処理ライブラリ「Pillow(PIL)」を使って、BASE64形式テキストを画像として読み込み、28行×28列のピクセルデータにリサイズし、さらにRGB値を8ビットグレースケールに変換している。このままだと、RGB形式なので、MNISTのデータ形式と異なる。形式を合わせるために、RGB値を「白=0」〜「黒=255」にスケール変換し、それをグローバル変数のtemp_dataに代入している。あとは、MNISTデータと同じように処理できる。
#@title 「0」か「1」を手書きしてください。
# This code will be hidden when the notebook is loaded.
from IPython.core.display import HTML
from IPython.display import Image
from PIL import Image
from io import BytesIO
import base64
import numpy as np
import matplotlib.pyplot as plt
import google.colab.output
temp_data = np.zeros((1, 28, 28))
def Base64image(encoded):
print(encoded)
binary = base64.b64decode(encoded.split(',')[1])
im224 = Image.open(BytesIO(binary))
im28 = im224.resize(
(28, 28),
Image.BICUBIC).convert('L') # L= 8ビット RGB黒白
global temp_data
temp_data = np.array(im28).reshape((1, 28, 28)) # 多次元配列の形状
temp_data = 255 - temp_data #「白=0」〜「黒=255」に変換
google.colab.output.register_callback('Base64image', Base64image)
HTML('''
<canvas id="myCanvas" width="224" height="224" style="border:1px solid #d3d3d3;">
お使いのブラウザーではHTML canvasをサポートしていないようです。
</canvas>
<p>
<button id="clear">削除</button>
<button id="submit">このデータを保存</button>
<span id="infobar"></span>
</p>
<script>
// Canvas描画領域
var canvas = document.getElementById("myCanvas");
var ctx = canvas.getContext("2d");
ctx.strokeStyle = "#000";
ctx.lineJoin = "round";
ctx.lineWidth = 15;
ctx.fillStyle = "#FFF";
ctx.fillRect(0, 0, canvas.width, canvas.height);
// メッセージ表示領域
var infobar = document.getElementById("infobar");
// [削除]ボタン
var clearbtn = document.getElementById("clear");
clearbtn.addEventListener("click", function(){
ctx.clearRect(0, 0, canvas.width, canvas.height);
ctx.fillStyle = "#FFF";
ctx.fillRect(0, 0, canvas.width, canvas.height);
infobar.textContent = "";
});
// [このデータを保存]ボタン
var submitbtn = document.getElementById("submit");
submitbtn.addEventListener("click", function(){
var base64image = canvas.toDataURL('image/jpeg', 1.0);
google.colab.kernel.invokeFunction('Base64image', [base64image])
infobar.textContent = "保存しました!";
});
// マウスカーソルを管理
var mouse = {x: 0, y: 0};
// マウスカーソルを描画する
var onPaint = function() {
ctx.lineTo(mouse.x, mouse.y);
ctx.stroke();
};
// マウスの移動を捕捉する
canvas.addEventListener('mousemove', function(e) {
var rect = e.target.getBoundingClientRect();
mouse.x = e.clientX - rect.left - 1;
mouse.y = e.clientY - rect.top - 1;
}, false);
// マウスボタンが押し下げられたら描画を開始させる
canvas.addEventListener('mousedown', function(e) {
ctx.moveTo(mouse.x, mouse.y);
ctx.beginPath();
canvas.addEventListener('mousemove', onPaint, false);
}, false);
// マウスボタンが離されたら描画を終了させる
canvas.addEventListener('mouseup', function() {
canvas.removeEventListener('mousemove', onPaint, false);
}, false);
</script>
''')
temp_dataは1件分のデータとなっており、リスト10-3のように簡単に表示できる。
import matplotlib.pyplot as plt # グラフ描画ライブラリ(データ画像の表示に使用)
#import pandas as pd # データ解析支援「pandas」
print(temp_data.shape) # 多次元配列の形状: (1, 28, 28)
# 図を描画
plt.imshow( # 画像を表示する
temp_data[0], # 1つの訓練用入力データ(28行×28列)
cmap=plt.cm.binary) # 白黒(2値:バイナリ)の配色
plt.show()
#display(pd.DataFrame(temp_data[0])) # 表形式で表示する場合
また、10-4のように推論もいつも通り行える。
import matplotlib.pyplot as plt # グラフ描画ライブラリ(データ画像の表示に使用)
# 推論(予測)する
predictions = model.predict(temp_data)
predictions
# 以下のように出力される(「1.」は100%「1」、「0.」なら100%「0」)
# array([[1.]], dtype=float32)
次回について
以上、今回は基本的なDNNで「分類問題」を解決した。基本のDNNについては今回で最後である。十分かつ自由に使いこなせるようになっただろうか。
今回の分類問題では、評価指標として「正解率(Accuracy)」を用いた。また、前回の回帰問題では「平均絶対誤差(MAE)」を用いた。これら以外の評価指標を用いることもできるので、回帰問題と分類問題の総集編として、次回からは評価指標をまとめる。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。