ハフマン符号展開処理を最大で「1万1000倍」高速化 広島大学の研究チームが「ギャップ配列」を考案:「セグメント」と「ギャップ」で高速化
広島大学の教授である中野浩嗣氏らの研究チームは、GPUによるハフマン符号の並列展開処理を高速化する新しいデータ構造「ギャップ配列」を考案した。従来の最速展開手法に比べて、最大1万1000倍高速化できるという。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
広島大学大学院先進理工系科学研究科の教授である中野浩嗣氏らの研究チームは2020年8月31日、富士通研究所と共同で、GPUによる「ハフマン符号」の並列展開処理を高速化する新しいデータ構造「ギャップ配列」を考案したと発表した。従来の最速展開手法に比べて2.5〜1万1000倍の高速化が見込めるとしている。
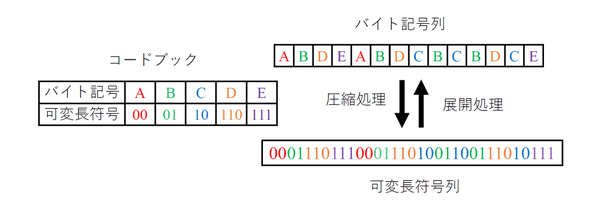
ハフマン符号は、可変長符号を使って全体のデータ量を小さくするデータ圧縮アルゴリズム。より多く出現するデータ(バイト記号)に対して、より短いビット長の符号を割り当てる。「JPEG」や「ZIP」などの圧縮技術にも利用されている。
圧縮の並列化はできていたが、展開処理の並列化が困難だった
プロセッサは単一コアの処理性能が頭打ちになっており、マルチコア化など並列化によって全体の処理性能を高める必要がある。だがハフマン符号には、圧縮処理時には並列化が比較的容易なのに対して、展開処理時の並列化が難しいという課題があった。
元データをハフマン符号化(圧縮)するには、バイト記号と可変長符号の対応表(コードブック)に従ってバイト記号を可変長符号に変換し、変換した可変長符号を連結する。そのため、元データを複数部分に区切ってそれらを複数のプロセッサコアを使って同時に変換処理し、最終的に連結することで比較的容易に並列化できる。
 ハフマン符号の圧縮と展開の処理
ハフマン符号の圧縮と展開の処理これに対して圧縮データは可変長符号からなっているため、データの途中からではデータ区切りが分からず、展開時には先頭から逐次的に変換する必要がある。展開時に並列化が困難なのは、このためだ。
「セグメント」と「ギャップ」を使って並列化を実現
中野氏らの研究チームは、圧縮後のデータ(可変長符号列)を、通常のバイト列のように、先頭から同一ビット数(256ビット程度)ごとに分割して考えた。このときの分割単位を「セグメント」と呼ぶ。各セグメントを独立して展開できれば、並列処理が可能になる。
ただし、圧縮後のデータは可変長符号からなるので、当然、1つのデータが2つのセグメントにまたがることがある。あるセグメントを見ただけでは、そのセグメントにデータがまたがっているかどうかは判別できないので、前述のように展開処理時は並列化が困難だった。
そこでデータ圧縮時に、各セグメントに2つのセグメントにまたがったデータの次のデータが始まる位置(ギャップ)を記録するようにした。こうすれば、ある1つのセグメントを取り出しても、展開処理が可能だ。全てのセグメントのギャップを並べたものをギャップ配列と呼ぶ。
 データの始まる位置(ギャップ)を記録した配列を使って展開処理を高速化
データの始まる位置(ギャップ)を記録した配列を使って展開処理を高速化従来のハフマン符号によって圧縮したデータに比べて、中野氏らの研究チームが考案した手法はギャップ配列の分だけデータ量が増える。だが研究チームによると「増加量は0.4〜1.5%とわずかだ」という。
実際に、NVIDIAのGPU「Tesla V100」で、10種類のファイルを対象に処理性能を評価したところ、ギャップ配列のない従来のプログラムに比べて、圧縮処理は2.5〜7.4倍、展開処理は2.5〜11000倍の高速化が達成できたとしている。
関連記事
 NVIDIAのGPU4基で「1秒間に1兆の解を探索」 広島大学の研究グループが高速探索手法を開発
NVIDIAのGPU4基で「1秒間に1兆の解を探索」 広島大学の研究グループが高速探索手法を開発
広島大学大学院の教授である中野浩嗣氏らの研究チームは、組み合わせ最適化問題の解を高速に探索する新しい計算方式「アダプティブ・バルク・サーチ」を開発した。著名な組み合わせ最適化問題である「最大カット問題」「巡回セールスマン問題」「ランダム問題」について、いずれも1秒以内で最適解が得られたという。 広島に行けばなにか新しいことができる――広島県が目指す「イノベーション立県」への第一歩とは
広島に行けばなにか新しいことができる――広島県が目指す「イノベーション立県」への第一歩とは
「イノベーション立県」を目指す広島県。地域や企業の課題を解決するために行っている3つの取り組みとは。 深層学習モデルのサイズを30分の1に NEDOとアラヤが自動圧縮ツールを開発
深層学習モデルのサイズを30分の1に NEDOとアラヤが自動圧縮ツールを開発
NEDOとアラヤは、深層学習用ニューラルネットワークモデルを自動で最大約30分の1に圧縮し、FPGAに実装可能なソースコードを出力するツールを開発した。自動車やスマートフォンといったエッジデバイスにもAIを実装できるようになる。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。