HTTP(Hyper Text Transfer Protocol)〜前編:インターネット・プロトコル詳説(1)
インターネット普及の原動力となったHTTPの登場
| 1990年ごろ | スイスのCERN(ヨーロッパ素粒子研究所)において、Tim Berners-LeeがHTMLと共にHTTPの基礎を考案。WWW(World Wide Web)システムと名づける |
|---|---|
| 1993年 | NCSA(米国 国立スーパーコンピューター応用センター)でHTMLとHTTPを実装したMosaicブラウザとNCSA HTTPサーバを開発。対応バージョンはHTTP0.9。無償公開を開始 |
| 1996年 | Tim Berners-LeeらがHTTP1.0仕様(RFC1945)を公開 |
| 1999年 | HTTP1.1公開 |
| 表1 HTTP発展の歴史 | |
HTTPは、近年のインターネットを生み出したといっても過言ではない。それほどのインパクトを生んだこのプロトコルは、実にシンプルで、それゆえにこれほど発展したともいえる。
| RFC2616 | "Hypertext Transfer Protocol -- HTTP/1.1" |
|---|---|
| RFC2617 | "HTTP Authentication: Basic and Digest Access Authentication" Basic認証 |
| RFC2068 | "Hypertext Transfer Protocol -- HTTP/1.1" 最初のHTTP1.1仕様。2616に置き換えられている |
| RFC1945 | "Hypertext Transfer Protocol -- HTTP/1.0" |
| RFC1738 | "Uniform Resource Locators (URL)" |
| RFC1630 | "Universal Resource Identifiers in WWW" URI仕様 |
| RFC2965 | "HTTP State Management Mechanism" Cookieに関しての利用仕様。現在での正式最新版 |
| RFC2109 | "HTTP State Management Mechanism" Cookieに関しての利用仕様 |
| 表2 HTTP関連のRFC一覧 | |
現在の最新バージョンはHTTP 1.1で、1999年にRFC2616として標準化された。すでに標準的なWebブラウザやWebサーバでは1.1の実装はされているが、まだ前バージョンである1.0が使われている局面も多い。本稿では主に1.1をベースに説明を行い、適時注釈を加えることにしよう。
HTTPプロトコルの概要
以下の図はHTTPプロトコルを模式的に表したものだ。
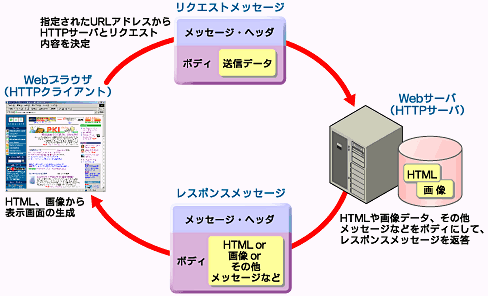 図1 HTTP通信の流れ
図1 HTTP通信の流れもともとHTTPはその名の示すとおり、「Hyper Text」つまりHTMLなどのテキストファイル、画像、そのほかの複合ファイルといったリソースを、効率的にクライアントへ配布するためのプロトコルである。また近年では、XMLや分散オブジェクトモデルとも深く結びつき、「コミュニケーション/アプリケーション・プロトコル」として、ますます活用の場は広がり続けている。
誤解されている場合も多いが、HTTPは単にリソースの送受信を行うプロトコルにすぎず、画面の生成/表示(レンダリング)はHTMLやWebブラウザにおける仕様であり、明確に分けられている。
特徴として、
- 数少ない命令だけから構成され、シンプル
- 複雑なネゴシエーション(通信前手順)を必要としないため、クライアント/サーバともに処理のオーバーヘッドが少ない
- HTMLや画像・音声、そのほかの「マルチメディア・データ」=「Hyper Text」を格納するためのフレキシブルかつステートレスな構造化データである
ことが挙げられるだろう。
その単純さは、RPCなどのそれまでに存在したプロトコルに比べてそう快さ、潔さを感じられるほどである。ただし、それゆえの問題点を含む要因にもなっている。
クライアント/サーバモデルであり、
(1) クライアントからサーバへのリクエスト
(2) サーバからクライアントへのレスポンス
を最小の通信単位とする。
こうした通信はコンピュータにしか理解できないバイナリ値ではなく、簡単なテキスト(ASCIIコード)の組み合わせになっており、ゆえに(1)をリクエスト・メッセージ、(2)をレスポンス・メッセージと呼ぶ。つまりメッセージの交換でクライアントとサーバは通信し合っているにすぎない。
これらのメッセージは、SMTPやPOP3などで使用されるMIMEメッセージと酷似している。歴史的にはMIMEが先に存在しており、HTTPはそれに倣ったわけだ。両者はまったく別個の仕様であり、互換性などはさほど明確にされていないが、RFC2616では、メッセージの構造や文字コードの利用をMIMEに倣うとしている個所が随所に現れる。
実際の例を挙げよう。例えば、WebブラウザがあるHTMLを取得する場合、上記のメッセージ交換を1往復のみ行う。これだけで処理はすべて足りてしまう。HTMLが画像など、そのほかのリソースも併せて構成されている場合には、再びそのリソースごとに1往復のメッセージがやりとりされ、すべてのデータがそろった時点でWebブラウザはデータを表示し終えることになる。
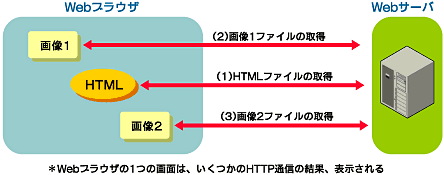 図2 Webブラウザが1つのページを表示するまでに、HTMLや画像の要素分だけメッセージの交換が行われる
図2 Webブラウザが1つのページを表示するまでに、HTMLや画像の要素分だけメッセージの交換が行われるちなみに、Webサイトへのアクセス数といった場合に、単純な集計では上記のようにHTMLページだけでなく、画像やそのほかのリソースへのアクセスも含んでしまうことになる。Webサーバから見ればHTMLファイルも画像ファイルも違いはないからだ。そこで「ページビュー」などの単位では、純粋にHTMLファイルへのアクセス数のみを切り出すようになっている。
URLの意味を解読してみよう
Webブラウザで入力するアドレスとして、HTTPを知らない人でもURLは使い慣れていることだろう。このURLが示す場所のファイルを取得する、これがHTTPの本質であるといえる。まず、URLとは何なのだろうか? 以下はURLの模式である。
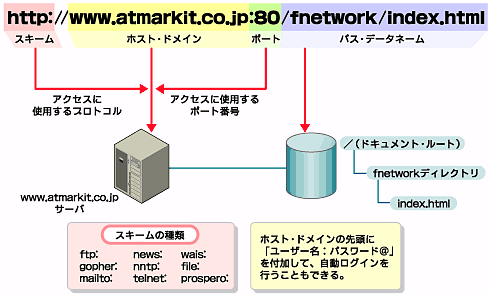 図3 URLのフォーマット
図3 URLのフォーマットURLはUniform Resource Locatorの略である。つまり汎用的(全世界的)に特定可能なリソースの位置を示すための簡易なフォーマット文字列という意味を持つ(RFC1738で定義されている)。もともとはURI(Universal Resource Identifiers)という位置関係を示す定義が存在しており、URLはこのURIの1つの形式にすぎない。
まずWebブラウザは、スキームでサーバへアクセスするプロトコルを決定する。ここで「http:」と指定されている場合のみ、HTTPが利用される。つまり、HTTPありきでURLは存在しているわけではなく、HTTPはURLを利用しているだけである点に注意されたい。
普段ポート番号を指定することは少ない。これはWebサーバ側で何番のポートを用いてWebサーバ・アプリケーションを実行しているかに依存する。省略された場合には、HTTPの標準ポート番号である80が指定されているものと見なされる。
そしてホスト・ドメイン(DNSサーバ名)に指定されたサーバへ接続が行われる。DNS名の代わりにIPアドレスを使用することもできるが、可能な限り避けるべきとされる。
Webサーバへは、パス・データネーム部がリクエストとして渡される。WebサーバではHTMLや画像ファイルを格納するドキュメント・ルートというディレクトリが通常設定されている。パス・データネームはこのドキュメント・ルートからの相対パスである。
このようにプロトコル(=アプリケーション)+サーバ名+サーバ内ファイル名の組み合わせによって、全世界で一意なリソースをURLは特定しているのだ。
また、URLは上記のように「物理的な位置」を示しているにすぎない点に注意していただきたい。つまり「永続的な」存在を保証しているわけではないのだ。これに対して、URIのもう一方の仕様であるURN(Uniform Resource Name)は永続的なリソース、すなわち「名前」を指定できることを想定している。例えば、住所を用いて個人を特定しようとした場合はこの住所が変われば特定できなくなるかもしれないが、(全世界で唯一存在する)氏名であれば、永続的に特定は可能になる。HTTP 1.1仕様でもこうした点に着目して、一般的にはURIを対象としている。
混乱する部分もあるかもしれないが、以下の説明でURIとある部分は、URLと読み替えても問題はない。
HTTPメッセージの構造
以下はHTTP 1.1で示されるHTTPメッセージのフォーマット構造図だ。
| メッセージ・ヘッダ | リクエスト・ライン |
|---|---|
| リクエスト・ヘッダフィールド | |
| 一般ヘッダフィールド | |
| エンティティヘッダフィールド | |
| その他 | |
| 空行(CR+LF) | |
| メッセージ・ボディ | |
| メッセージ・ヘッダ | ステータス・ライン |
|---|---|
| レスポンス・ヘッダフィールド | |
| 一般ヘッダフィールド | |
| エンティティヘッダフィールド | |
| その他 | |
| 空行(CR+LF) | |
| メッセージ・ボディ | |
図4 HTTPメッセージのフォーマット(ここをクリックすると、それぞれのメッセージの例を別ウィンドウで表示します)
HTTPメッセージは例のように、複数行から成り立つ一連のデータ列である。ここでいう1行とは、終端にCR(キャリッジリターン、16進の0x0d)とLF(ラインフィード、16進の0x0a)を持つデータの単位である。ほぼ、通常のテキスト・データの1行と等しい。メッセージ・ヘッダとメッセージボディ部に分かれ、両者は空行(単独のCR+LF)で分割される。
ボディは常に存在するとは限らない。例えば、単にリソースを取得する場合のリクエスト・メッセージや、エラー時のレスポンス・メッセージのボディには何も含まれない場合がある。ボディ部は通常転送されるべきデータそのものであり、ヘッダはリクエストやレスポンスの内容や属性を示す。またヘッダはそれぞれ意味の異なる複数行から成り立つ。この行をヘッダ・フィールド(または単にフィールド)と呼ぶ。以下はフィールドのフォーマットである。
フィールド名: フィールド値{[;パラメータ名=パラメータ値]}
フィールドは、続く行の先頭が空白か水平タブ(0x09)である場合のみ複数行にまたがることができる( { } 内の項目は複数現れる場合がある)。
ヘッダ・フィールドは、主に次の種類に分けられる。
リクエスト・ヘッダまたはレスポンス・ヘッダ
リクエスト・メッセージまたはレスポンス・メッセージに固有に含まれるヘッダ
一般ヘッダ
リクエスト・メッセージとレスポンス・メッセージに共通して含まれ得る。主にメッセージ全体の属性について示す
エンティティ・ヘッダ
リクエスト・メッセージとレスポンス・メッセージに共通して含まれ得る。主にエンティティ(転送されるデータ。主にボディに含まれるデータなどの総称)の詳細や属性について示すフィールド
その他
HTTPのRFCには定義されていないフィールドが格納される場合もある。クッキー(Cookie)フィールド(RFC2965)などが挙げられる
| フィールド名 | HTTPバージョン | 説明 |
|---|---|---|
| Accept | 利用可能なアプリケーション・メディアタイプ。複数指定、優先度指定も可能 | |
| Accept-Charset | 利用可能な文字セット | |
| Accept-Encoding | 利用可能なエンコーディング形式(Content Coding形式) | |
| Accept-Language | 利用可能な言語コード。複数指定し、優先度を付けることが可能 | |
| Authorization | ○ | ログインに必要な認証情報。ユーザー名とパスワードが格納される |
| Expect | サーバ要求が実装されているかどうかの確認時に期待されるレスポンスを指定する | |
| From | ○ | 利用ユーザーに固有なメールアドレスなどの情報。ただし無条件にリクエストに付加するのはセキュリティ上の問題でもあり、あまり実装されていない |
| Host | リクエスト先サーバ名。DNS名を利用する。1.1ではプロキシや仮想サーバの利用を前提に、必須としている | |
| If-Modified-Since | ○ | Dateを指定する。指定したDateより最新のリソースの場合のみデータを取得できるように指示する。ローカルキャッシュの最新確認に使用される |
| If-Match | 指定したエンティティタグに一致する場合のみデータを更新/取得するように指示する | |
| If-None-Match | 指定したエンティティタグに一致しない場合のみデータを更新/取得するように指示する。最新情報の取得や競合の排除のために指定される | |
| If-Range | 指定されたエンティティタグが最新であれば、それ以外の残りを転送するように指示する。Rangeとともに使用される。または最終更新時刻(Date)を指定してもよい | |
| If-Unmodified-Since | Dateを指定する。指定したDate以降リソースが更新されていない場合のみデータを取得できるように指示する | |
| Max-Forwards | 経由できるプロキシの最大数 | |
| Proxy-Authorization | プロキシにログインが必要な場合のための認証情報 | |
| Range | 取得するデータのバイトレンジ。単位はバイト | |
| Referer | ○ | 直前にリンクされていたURL |
| TE | 利用可能なエンコーディング形式(Transfer Coding方式) | |
| User-Agent | ○ | Webブラウザの固有情報 |
| 表3 RFCで定義されているヘッダ・フィールドの一例(ここをクリックすると別ウィンドウで残りのヘッダフィールド一覧を表示します) | ||
○……1.0/1.1共通
無印……1.1より追加
定義されているフィールドはもちろん、それぞれ必ず使わなければならないわけではない。それぞれの用途に応じて使用される。また、独自に任意のフィールドを追加することも可能だ。
リクエストとレスポンスのシーケンス
では実際のリクエストと応答するレスポンスの流れを確認してみよう。リクエスト・メッセージのヘッダには、先頭行に必ず「リクエスト ライン」が含まれる。これは実際のリクエスト内容を示す。
リクエスト・ラインは次のようなフォーマットで示される(各要素間には空白文字が入る)。
メソッド[空白]リクエストURI[空白]HTTPバージョン
メソッドとは、サーバにリクエストを指示する「命令」である。メソッドとして、次のようなものが定義されている。
| メソッド | HTTPバージョン | 機能 |
|---|---|---|
| HEAD | ○ | 指定したURL取得の結果レスポンスのヘッダーのみ取得する。ボディーにリソースのデータは含まれない |
| GET | ○ | 指定したURLが示すリソースを取得する。レスポンスのボディーにはリソースのデータが含まれる |
| POST | ○ | 指定したURLが示すサーバーのコマンドに対して、データを転送する。リクエストのボディーには転送するデータが含まれる |
| PUT | ○ (1.0はオプション) |
指定したURLが示すリソースに対して、データを転送して置き換える。リクエストのボディーには置き換えるデータが含まれる |
| DELETE | ○ (1.0はオプション) |
指定したURLが示すリソースを削除する |
| TRACE | サーバーやプロキシの動作を診断するための情報を返答する | |
| OPTIONS | 使用できるメソッドやオプションの一覧を取得する | |
| CONNECT | プロキシでのトンネリング接続を行う | |
| LINK | × | |
| UNLINK | × | |
| 表4 メソッドの種類 | ||
○……1.0/1.1共通
無印……1.1より追加
×……1.1では廃止
多くの場合、HTMLページや画像ファイルの取得に使用されるのがGETメソッドだ。例えばURLアドレスを指定されたり、リンクをクリックした場合には、WebブラウザはこのURLからGETメソッドのリクエストを生成する。この結果、レスポンス・メッセージとしてリクエストURIで指定したリソースが返答されるわけだ。このリクエストURIは絶対パス形式(例えば、http://www.atmarkit.co.jp/fnetwork.index.html)と相対パス形式(例えば、/fnetwork/index.html)の両方を取り得る(HTTP 1.0では相対パスのみ使用される)。この場合、リクエストボディには何も指定されることはない。
逆にサーバへ格納するなどの目的でリソースを送信する際には、POSTメソッドが使用される。この場合には、リクエストボディにはリソースのデータを格納してリクエストを行う。
POSTメソッドの最も一般的な例は、HTMLの「
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。