Webサーバ周辺、これだけおさえれば、落ちても大丈夫?:特集:システム管理の鉄則(前編)
さて、この記事に興味を持った皆さんの多くはサーバ運用に携わっていることかと思います。顧客や社外向けのシステムや、社内向けの業務サーバを構築、運用されている皆さんにとって、導入したシステムの稼働状況はいうまでもなく重大事で、システムがちゃんと動いているかが気になって夜もぐっすり寝られないことがあるかもしれません。
そこでシステム監視ツールを導入して、サーバの稼働状況を監視し、障害が発生したときに迅速な対処を図ろうということになるかと思います。この連載では、システム障害時の迅速・的確な対応を第一義とした、システムの具体的な監視のための手法について解説していきます。
監視設計とは
システムを監視するには、監視の設計をすることが必要です。システムを構築するに当たっては、最初に設計を行うのと同じように、監視を行うためにも監視システムの設計をしましょう(監視を行うのも“システム”なのだから当たり前のことですが)。
監視システムの設計というと何やら込み入った面倒くさい作業に感じますが、ポイントとしては以下の3つです。
- システム全体、もしくはシステムを構成するモジュールが提供するサービスに対して監視方法を決める。――「外形監視」外形監視」
- システムの構成するモジュールをさらに細かいコンポーネントに分け、このコンポーネントごとに監視方法を決める。――「症状監視」症状監視」
- 監視対象は必要最小限に。
1.は監視の基本となる部分で、システムとして提供するサービスが正しく動いているかどうかの監視を受け持ちます。このタイプの監視をこの記事では「外形監視」と呼びます。
この部分の監視は、可能な限りシステムの利用方法に近い監視対象で、利用方法に近い監視手法を選びます。具体的には、Webサーバに対する監視を実施する場合、実際にHTTPでデータの送受信をシミュレートしたり、メールサーバなどには実際にメールを送信してみるなどの方法が最も理想的です。監視に利用するツールの仕様などで、実際に利用者が利用するときの状況をそのまま監視方法として採用できない場合でも、可能な限り利用イメージに近い監視方法を採用することが必要です。
2.のタイプの監視は外形監視で決めた監視を補完するもので、障害を検知したときに発生している障害がどんなものなのかを特定するために必要な情報収集を受け持ちます。このタイプの監視をこの記事では「症状監視」と呼びます。
具体的にはシステムの中核となるサーバがつながっているファイアウォールや、ルータ、スイッチなどのネットワーク機器への監視や、サーバを構成するハードウェアやOSへの監視と、サービスを提供するプロセスへの監視などを別個に監視することにより、障害対応時の的確な対応に役立ちます。
外形監視と症状監視の違いを明確にするため、それぞれの監視の役割を図に描いてみるとこんな感じになります。
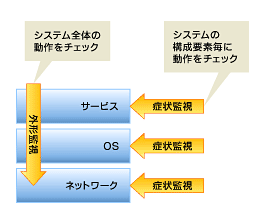 図1 外形監視と症状監視の模式図
図1 外形監視と症状監視の模式図ここで強調したいのは、システムに対する監視の中心はあくまでも外形監視で、症状監視はそれを補完するものだということを覚えておいてください。極端な話をすると、システム監視をするためには外形監視だけでも監視としては十分機能します。システムを監視する目的の第一義は「システムの稼働状態をチェックする」なので、この目的だけで監視を実施する場合には外形監視の実施だけでまったく問題ないでしょう。
問題は症状監視の設計です。外形監視と症状監視はそれぞれ役割が異なり、
- 外形監視でシステムの稼働状態をチェックする
- 症状監視で障害発生時に起こっている症状を把握し、障害対応に役立てる
という分担を明確にする、それぞれの役割での監視の設定をすることが重要です。
監視する対象は必要最小限に
3つ目のポイント「監視する対象は必要最小限に」は障害対応時に効いてきます。このポイントは正確にいうと「障害発生時に監視ツールから送られてくる障害通知がシンプルなほど良い監視システムである」ことなのですが、一般的な監視ツールは、
監視対象の数 = 障害通知メールの数
となるため、効率の良い監視を実施するには「監視する対象は必要最小限に」する必要があります。
前に解説した外形監視と症状監視の役割分担を踏まえずに監視の設計を行ってしまい、とにかく「検出したいエラー」ありきで設計し、監視対象を増やしていったり、「監視ツールが対応しているから監視しておこう」といってむやみに監視対象を増やしてしまうケースも多々見受けられます。
一般的に症状監視を行う監視対象や方法を多くすればするほど、より詳細な障害発生時の状況を知ることができますが、そもそも検出したい状況はどんなものなのかを把握せずに監視を実施すると、障害発生時に処理しなければならない情報が増え、本当に知りたい情報が埋もれてしまうなどのトラブルが起こりえます。
逆に筆者の経験からするとシステムの監視は監視対象(正確にいうと障害と判断するに必要な監視対象)が少なければ少ないほど障害発生時の対応を迅速にできます。
一見、監視から得られる情報が多いと障害発生時に多くの情報を収集できているので、監視対象が多ければ対応は的確かつ迅速に行えそうに思えますが、多くの場合、現実は逆に作用します。
監視にまつわる実際にあった話として例を挙げると、非常に重要なサービスだからだといって監視設定を非常に多く設定したところ、システムの根幹の部分で障害が発生したため大量の障害通知メールが送信され、それがもとでメールサーバまで、一時的に機能しなくなり、そのメールサーバの機能停止がさらに障害として検知されたために障害通知の輻輳が起こってしまったという、まったく笑えない事例がありました。
もちろんこれは極端な例ですし、実はこの問題を解決するため、昨今の監視ツールでは関連するエラーをまとめて報告するような機能が付いているものもあり、監視対象の依存関係を細かく規定できるので、多くの監視から得られた情報を包括的にレポートできるようになっています。この機能を有効に使えば多くの監視対象を設定しても障害発生時に報告されるエラー情報をシンプルにできるので、非常に有用な機能ではあります。
しかし、だからといってむやみに監視対象を増やしてゆくと、今度は「監視対象の依存関係を細かく設定」に大変なコストが掛かってしまうので、やはり監視設定はほどほどにというのが重要であることに変わりはありません。
ほとんどの人(筆者もそうですが)にとって障害の一報は、その人を非常にナーバスな状態に陥れます。ナーバスな状態の人間は、大抵の場合多くの情報を処理できないので、障害発生時の情報は可能な限り少なくなるよう監視設計を行い、代わりに障害発生時の対応方法をマニュアル化するなどした方が、実際の障害対応の効率がアップする傾向があるかと思います。
効率の良い症状監視
監視対象が増えてしまう要因は症状監視にあります。前にも説明したとおり、そもそも症状監視は障害発生時に障害の内容を切り分けるために設定する監視なので、つい多くの対象に対して監視を設定してしまうものです。
では効率の良い症状監視をするにはどうしたらいいのでしょうか? 残念ながら症状監視はその性格上、システムの成り立ちに大きく依存しているため、症状監視を行うための「公式」と呼べるようなものはありません。しかし、それでもいくつかのパターンを利用すれば、症状監視を行う対象を減らすことはできます。
以下に症状監視を減らすため、一般に適応しやすいパターンを列挙してみました。
監視方法の組み合わせを整理する
一般に1つのサーバに複数の監視方法を行うことによって、発生した障害がどのようなタイプかをある程度判断することができます。
例えばping監視とサービス稼働監視を組み合わせると、障害を検知した状態が、
ping監視 OK
サービス稼働監視 NG
であれば、多分OSは動いているのだが、プロセスが落ちているということを想像できます。
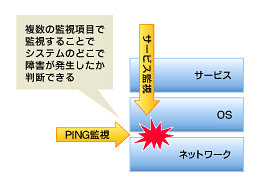 図2 複数の監視方法によるサーバ監視
図2 複数の監視方法によるサーバ監視しかし、障害対応の観点からは、OSが落ちているかどうかも知りたい情報であるが、それよりもそのサーバに対してリモートからアクセスできるかどうかを知るのが重要なのではないでしょうか?
多くの場合サーバに対する障害対応は、OSが稼働しているのであればリモートからそのサーバにアクセスし、ログのチェックなどをしてサーバプロセスへの対応を行うと思います。このため、障害発生時にそもそもサーバに対してリモートアクセスする方法があるかどうかをチェックできていれば、その分だけ障害への対応が迅速になるはずです。
このように、「障害対応に必要情報を得る」という観点から監視対象を決定していくことで、余計な監視の設定を排除することができ、結果として効率の良い監視設計ができるかと思います。
サーバ外部からの監視を優先する
例えばWebサーバの監視を行う場合、HTTPによるサービス稼働監視とプロセス監視を同時に行う意味はほとんどありません。なぜならばサービス稼働監視でエラーが起こらないということは、プロセスが稼働していることを意味しているので、わざわざプロセスを監視する必要はありません。
そもそもプロセス監視はOS側から見てプロセスがあるかどうかのチェックしか行えないため、監視の対象となるプロセスが通信を行う場合には、ポート監視やサービス稼働監視で監視を行った方が実効的です。
また、サービス稼働監視でレスポンスのデータが得られている場合、このサーバにサーバ負荷の監視を行うことも意味がありません(サーバリソースの統計データの取得という意味ならば有用ではありますが)。両者から得られるデータは基本的にはシステムに掛かっている負荷という意味では同じものを指しますし、そればかりかサービス稼働監視で得られているレスポンスのデータは、実際にクライアント側から見たレスポンスに近い値が得られるので、サーバのロードよりシステムが置かれている状況に対して監視が実施できます。
ログ監視のパターンは最小限にする
ログ監視は実際の監視対象からの情報を抽出して監視できるので、状況監視としては実に都合のいい監視方法です。しかし、一般的な監視ツールはログ監視をログファイルに出現する文字列から検出するパターンを設定します。このため、検出パターンをあいまいにしておくと、本来、障害ではない場合でも検出されたり、障害発生時でも多くの行がマッチしてしまい障害通知が大量に出てしまったりすることがよくあります。
一般的な監視ツールではログの1行が障害通知1件に対応する点に留意してください。このため、設定によっては1つのエラーで大量にログが発生したとき、ログの1行1行が1通のメールとなって送られてくる場合もあり得ます。
このため、ログ監視を行う場合には1つの障害で検出するログが少ない方が障害対応に好ましい結果を上げることになるでしょう。
システムリソース監視は最初は閾(いき)値を設定しない
CPU利用率、ディスク利用率、ネットワークインターフェイスの流量などシステムリソースは、どれも基本的にはある程度時間をかけて収集し、統計データとして解析して初めて役立つ情報です。従って、統計用のデータとして監視の設定を行う分には問題ありませんが、閾値を設定して、障害の通知に利用することはあまりお勧めできません。
設定する閾値は統計情報が得られていない監視ツール導入の段階では「まあ、こんな感じ」という数字が設定されるケースが多く、障害検出という視点から見るとほとんど無意味な監視設定です。従って、このタイプの監視を行う場合は、実際のシステムに適応し、一定期間データを収集してから閾値を設定する方が有用です。極端な話をすれば「実際に障害が発生した後で、障害時の数値を参考に閾値を設定する」ぐらいの方が有用な閾値を設定できる可能性は高いです。
監視ツールと監視対象の経路に応じた監視を行う
実際に監視を行う際に、さまざまな事情により、監視ツールと監視の対象となるサーバの経路にファイアウォールや、ロードバランサなどが入る場合もあり得ます。
この場合、ping監視・ポート監視などでは、監視ツールからの監視パケットに対して、サーバと監視ツールの間にあるファイアウォールなどが返答してしまう場合があり得ます。
こういった場合は、監視を実施する前に、ファイアウォール、ロードバランサなど経路に入った機器の動作をよく確認し、監視方法を決定するとともに、実際に監視の通信がサーバに届いているかどうかのチェックを行うなどして無意味な監視をしないようにすることが重要です。
これらはどんなシステムでも適応可能なパターンですが、監視の対象となるシステムの特性に応じて、無駄な監視対象を減らしたり、より実効的な監視が行えたりするなどいろいろな方法があるかと思います。
後編ではこれらのポイントを踏まえて、モデルシステムにフリー(GPLライセンス) の監視ツールを利用した監視の設計と設定の具体的な例を示していこうと思います。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。