DBや入力フォームで文字化けする場合の対処方法:Javaの文字化け対策FAQ(3)
JSP/サーブレット・プログラミングで誰もが一度は遭遇するトラブルが文字化けだ。予期せぬ文字化け発生に、デバックに苦労した経験を持つ読者も多いだろう。本連載では、JSP/サーブレットにおける文字列の扱いの基礎を復習した上で、文字化けの解決策を要点よく解説していく予定だ。(編集部)
本記事は2005年に執筆されたものです。Javaの文字化け全般の最新情報は@IT Java Solution全記事一覧のカテゴリ「トラブル・問題解決/ノウハウ/文字化け」をご参照ください。
質問1:ファイルやメール、DBで「〜‖‐¢£¬」が文字化けします
解答: 各種文字コードとUnicodeの間の変換ルールを見直しましょう
前回説明したとおり、「〜‖‐¢£¬」の文字化けは、「Unicodeと各種文字コード間の変換ルールの違い」によって発生するものだ。これらの文字について、Windows-31JとUnicode間の変換ルールは、その他の文字コード(Shift_JIS、EUC_JP、ISO-2022-JPなど)に用いられる変換ルールとはまったく異なる。よって、Windows-31Jとその他の文字コードの両方を扱わなくてはならないJavaアプリケーションでは、この問題が表面化しやすいのである。
例えば「ローカルのテキスト・ファイルの内容をWebブラウザやメールに送信する」というWebアプリケーションを考えてみよう。ファイルの文字コードをWindows-31Jで読み込み、その内容をShift_JISやISO-2022-JPなどの文字コードでWebブラウザやメールに送信すると、「〜‖‐¢£¬」の文字化けが発生する。これを回避するには、以下のような方策を取る必要がある。
- Windows-31J以外の文字コードでテキスト・ファイルを作成する
- テキスト送信時の文字コードをWindows-31Jに指定する
- 「〜‖‐¢£¬」のコードポイントを強制変換するコードを自作する
対応策の1つは、Windows-31J以外の文字コードでテキスト・ファイルを用意する方法である。Shift_JISやEUC-JPでファイルを作成し、java.io.FileReaderクラスではなくFileInputStreamクラスを用いることで読み込み時の文字コードを指定する(これについては後述)。ただしこの方法ではWindows機種依存文字は使えなくなる。
2つ目は、テキスト送信時の文字コードとしてWindows-31Jを指定する方法だ。これならばWindows機種依存文字も扱うことができるが、Windows-31J対応のWebブラウザしかサポートできなくなる。またテキスト内容をメール送信するケースでは、文字コードをISO-2022-JPとするのがルールであるため、この方法は使えない。
3つ目は、「〜‖‐¢£¬」のUnicodeコードポイントを強制変換するコードを自作する方法だ。例えば、Windows-31Jベースのテキスト・ファイルから読み込んだコンテンツを1文字ずつチェックし、U+FF5Eの「〜」を見つけたらU+301Cに置き換える、といった具合である。コーディングの手間は掛かるが、柔軟性は高いといえるだろう。
■デフォルト・エンコーティングに気を付けよう
ところで、ローカル・ファイルの読み込みにjava.io.FileReaderクラスを使うのはお勧めできない。なぜならFileReaderクラスはJVMのデフォルト・エンコーディングにしか対応しておらず、読み込み時の文字コードを明示的に指定できないからである。デフォルト・エンコーディングは、Windows上のJVMではWindows-31J(MS932)となり、UNIXではLANG変数で設定された文字コード(EUC-JPやUTF-8など)になる。そのため、例えばWindows上で開発した成果物をLinuxサーバ上で運用するケースなどにおいて、デフォルト・エンコーティングの違いによる文字化けが発生しやすい。
Javaアプリケーション開発では、自分が書いたコードがデフォルト・エンコーティングに依存しないように心掛けよう。例えばテキスト・ファイルを読み込む場合は、以下のようにFileInputStreamクラスとInputStreamReaderクラスで実装にすればよいだろう。
InputStreamReader isr = new InputStreamReader(
new FileInputStream("filename.txt"),
"Windows-31J");
この方法であれば、InputStreamReaderクラスのコンストラクタで文字コードを明示的に記述でき、デフォルト・エンコーティングに依存しない実装となる。
■データベースでの文字化け
「〜‖‐¢£¬」の文字化けは、データベース・アクセスでも発生することがある。ここで問題となるのは、データベース本体がどのような文字コードで構築されているかだ。
データベースがUnicodeで構築されていれば、JDBCドライバはJVM内部のUnicode文字をそのままデータベースに送ればよいため、文字化けが発生することはない。しかしデータベースがEUC-JPやShift_JISで構築されていると、再びUnicode変換の問題が頭をもたげてくるのである。
さらに厄介なのは、JDBCドライバ固有の振る舞いが絡んでくることだ。例えばPostgreSQL 7.3系のJDBCドライバでは、データベースがEUC-JPで構築されている場合、Unicode変換に「Windows-31Jと同じ変換ルール」を適用する仕様になっている。つまりコードポイントU+FF5Eの文字をEUC-JPの「〜」に割り当てるのである。そのため、例えば「Webブラウザのフォーム入力をShift_JISでデコードする」「EUC-JPで構築されたPostgreSQL 7.3.xにそれを保存する」といったWebアプリケーションでは、「〜‖‐¢£¬」の文字化けが発生してしまう。この場合、PostgreSQLをUnicodeで構築するか、各文字のコードポイントを強制変換するコードを挿入するなどしなくてはならない。
質問2:フォーム入力されたデータが文字化けします
解答:setCharacterEncodingメソッドを使いましょう
サーブレット2.3仕様以降(Tomcat 4以降)では、HttpServletRequestオブジェクトにsetCharacterEncodingメソッドが追加され、リクエスト・パラメータ読み込み時の文字コードを明示できるようになった。この機能を使うには、サーブレットもしくはJSPにおいて、getParameterメソッドを呼び出す前に以下のようなコードを実行すればよい。
request.setCharacterEncoding("Windows-31J");
これにより、Webブラウザが送信するデータをWindows-31Jとして認識し、JVM内で正しく日本語を扱うことができる(Windows-31J利用時の注意点は上述したとおりである)。
一般的にWebブラウザは、受信したWebページの文字コードをそのまま使ってフォームのデータを送信する。よって、例えばJSPやサーブレットの出力文字コードをEUC-JPに統一しているならば、setCharacterEncodingメソッドの引数にもEUC-JPを指定すればよい。
ちなみに、同引数に「JISAutoDetect」というキーワードを記述すると、受信したデータに基づく文字コードの自動判定も可能だ。しかしこの自動判定は完全ではなく、文字列の内容によっては誤判定も起こるので、できるだけ具体的な文字コード名を指定するのが望ましいだろう。
■GETメソッド利用時の注意点
setCharacterEncodingメソッドの利用において1点注意すべき点は、フォームのデータ送信にGETメソッドを用いたときの振る舞いがWebコンテナの実装依存であることだ。例えば以下のようなJSPページを考えてみよう。
<%@ page language="java" contentType="text/html;
charset=Windows-31J" %>
<html>
<head><title>テスト</title></head>
<body>
<form action="test.jsp" method="GET">
<input type="textbox" name="msg">
<input type="submit" value="Send">
</form>
<%
request.setCharacterEncoding("Windows-31J");
out.print(request.getParameter("msg"));
%>
</body>
</html>
このJSPページで注意していただきたい点は、フォームの送信メソッドとしてGETを指定している点だ。よってフォームのパラメータは、HTTPリクエスト・ボディではなく、URI上のクエリ文字列を通じてサーブレット・コンテナに送信される。
Tomcat 4.1.31の場合、上記コードは問題なく日本語を扱うことができる。
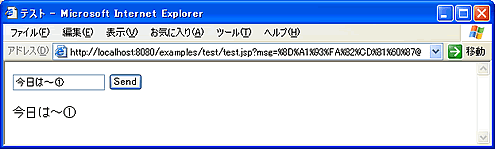 Tomcat 4.1.31では問題なく日本語が表示される
Tomcat 4.1.31では問題なく日本語が表示される一方、Tomcat 5.0.28では、これとまったく同じJSPページで、パラメータの文字化けが発生してしまう。実はTomcat 5.xではGETにより受信したパラメータに対して、setCharacterEncodingメソッドの文字コードを「適用しない」という仕様変更がなされているのである。
Tomcat 5.xにおいてこの問題を解消するには、同コンテナの設定ファイルserver.xmlのConnector要素にて、useBodyEncodingForURI属性を以下のように指定すればよい。
<Connector port="8080" maxThreads="150" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" redirectPort="8443" acceptCount="100" debug="0" connectionTimeout="20000" disableUploadTimeout="true" useBodyEncodingForURI="true"/>
Webブラウザの多くは、Webページと同じ文字コードでクエリ文字列を作成し、それに対してURLエンコーディング(%xx形式)を施してWebサーバに送信する。しかし、そもそもクエリ文字列の文字コードにはUTF-8を用いるのがルールである。Tomcat 5.xにおける仕様変更は、このルールを優先したものなのである(ちなみに、今年4月にGoogleにおけるクエリ文字列のデフォルト文字コードがUTF-8に変更され、いくつかのタブブラウザで文字化けが発生したのも、これと同様の事情によるものだ)。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。