Webアプリの問題点を「見える化」する7つ道具:現場から学ぶWebアプリ開発のトラブルハック(1)(3/3 ページ)
その6:プロファイラ
プロファイラとは、実行中のプログラムの動作を分析するツールである。メソッドの処理時間や呼び出し関係を統計情報として提供するメソッドプロファイラと、メソッドから生成されたオブジェクトの数やサイズ、世代情報を提供するオブジェクトプロファイラの2つが存在する。
■使いどころ
メソッドプロファイラは、HWリソースモニタリングツールでAPサーバのCPUがボトルネックになっているときに有効である。また、スレッドダンプ解析で問題が発見できなかった場合に使用する。
一方、オブジェクトプロファイラは、OutOfMemoryエラーが発生しているときや、GCログ分析でヒープ使用量が右肩上がりになっているときに、巨大なオブジェクトや無駄なオブジェクト生成をしているコードを発見するときに使用する。
実際に、コードがどのように動作しているか把握することのできるプロファイラ導入効果は非常に大きい。しかしながら、導入のイニシャルコストやアプリケーションに与える影響などデメリットも大きい。そのため、これまで紹介してきたツールなどでアプリケーションのつくりに問題の原因があると、アタリを付けてから導入するようにしている。
■分析方法
メソッドプロファイラは以下の観点で分析を行う。
- 全体の実行時間中の特定のメソッドの総実行時間が占める割合が大きいメソッドがないか
筆者は総実行時間の上位10件に注目しソースコードを再度確認している。経験上、上位10件を確認しておけば、ボトルネックとなっている個所をソースコードレベルで改善できる。
また、メソッド1回当たりの実行時間が短い場合でも、そのメソッドが大量に呼ばれている場合、メソッドの総実行時間(呼び出し回数×1回当たりの実行時間)が大きくなりボトルネックになる。そのため分析は総実行時間で行うのがポイントである。
- ほかのオブジェクトに比べて、生成されているサイズと数が多いオブジェクトが存在しないか
- 生存期間の長いオブジェクトがないか
- GC発生後に回収されず、数が増加し続けているオブジェクトがないか
上記リスト(1)の場合は、ヒープ領域を圧迫しGCが発生する原因となる。(2)の場合は、世代別GCのメリットを享受しにくくなってしまう。そのため、オブジェクトの生存期間は短いほどよいとされている。
編集部注:世代別GCについて詳細を知りたい読者は、チューニングのためのJavaVM講座の後編「ガベージコレクタの仕組みを理解する」をご参照ください
(3)の典型例は、静的なコレクションクラスにオブジェクトを追加し続け、削除しない場合である。こういった場合、アプリケーション起動後一定時間が経過すると、そのうちOutOfMemoryエラーが発生し、システムが停止してしまう。

図7はNetBeanProfilerでのオブジェクトプロファイリング実行例である。生成されているオブジェクト名とその数、サイズ、世代が表示されている。
編集部注:NetBeanProfilerについて詳細を知りたい読者は、連載Java開発の問題解決を助けるの第2回「プロファイラでメモリリークとパフォーマンス問題を解決」をご参照ください
■高速、マルチプラットフォーム対応のプロファイラ
プロファイラはその特性上、システムに与えるオーバーヘッドが非常に大きい。筆者の環境では、JVMに標準搭載されているhprofの場合、3秒足らずで起動していたTomcatの起動時間が1分以上に増加した。オーバーヘッドが大きくなると、高負荷時に問題が発生する場合、システムに負荷をかけきれず問題の再現が難しくなる。
また、問題を再現させるために時間がかかってしまい、早急にトラブルを解決できなくなってしまう。さらに、プロファイラはJVM依存の機能を利用することが多く、JVMのベンダや実行されるOSに対する制限が存在する。
有償ではあるが、JVMのプロファイラNeckLess(NTTデータ開発、ニューソン販売)を利用すると、これまで懸案だったプロファイラのオーバーヘッドを抑えるとともに、さまざまな環境(OS/JVM/APサーバ)で活用することが可能となる。筆者はこのNeckLessを用いて、ストレスのないプロファイリングを行っている。プロファイリングにストレスを感じる方は、試してみるとよいだろう。
その7:JMXクライアント
JMXはJava SE 5.0、J2EE 1.4以上で導入された、Javaアプリケーションを監視、管理するための仕組みのことである。APサーバにJMXクライアントを接続し、アプリケーションの状態を監視、管理できる。
■使いどころ
スレッドダンプ解析によって、プーリングオブジェクトの使用状況に問題が発生している可能性が高い結果が得られたときに利用する。JDBCコネクションプールやコネクタスレッドといったプーリングオブジェクトのMBeanに接続し、使用状況を監視する。
また、JMXクライアントはGC発生状況やスレッド使用を取得する機能を備えている。そのため、大まかにシステムの状態を把握したいときにも、有効である。
■分析方法
筆者はプーリングオブジェクトの分析を行うために以下のMBeanを監視している。
- コネクタスレッド:待受スレッド数
- コネクタスレッド:使用中の待受スレッド数
- JDBCコネクションプール:全JDBCコネクションプール数
- JDBCコネクションプール:使用中のJDBCコネクションプール数
利用できるJMXクライアントはMC4Jやjconsoleなどの多くのツールが世の中に存在するが、筆者は利用時のオーバーヘッドなどを考慮し上記の4つのMBeanのみを監視し、ログとして保存したいため、100行程度のJavaで記述したJMXクライアントを作成している。
コネクタスレッドは以下の観点で分析を行う。
- コネクタスレッドが枯渇していないか
- コネクタスレッドを無駄に生成していないか
コネクタスレッドはユーザーからのリクエストを受け付けるリソースであるため枯渇した場合、ユーザーリクエストは処理待ち状態となり著しくパフォーマンスが低下する。そのため、想定されるユーザー数のリクエストを同時に処理できる程度のコネクタスレッドをあらかじめ生成しておくことが理想的である。ただし、あまりにも多くのコネクタスレッドを生成してしまうと、無駄なリソースを消費してしまう。
JDBCコネクションプールは以下の観点で分析を行う。
- JDBCコネクションプールのActive数は想定している数と同じであるか
- JDBCコネクションプール数とDBサーバが示す接続数が同数であるか
システムが無応答になる原因の1つにプールオブジェクトの開放漏れがある。JDBCコネクションプールを獲得した後、JDBCコネクションプールを開放しないと、JDBCコネクションプールをすべて使い尽くし、システムは無応答になる。
迅速にトラブルを解決するには、どうすればよいか?
これまで紹介したツールを駆使し、システムの状況を「見える化」することで、分析作業が非常にやりやすくなる。ここでトラブル切り分け解析フローを振り返りたい。
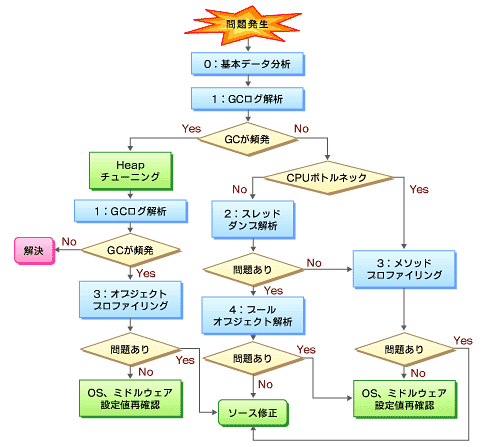 図8 トラブル切り分けフロー(再掲)
図8 トラブル切り分けフロー(再掲)- 最初に基本データを分析し、APサーバ以外のサーバがボトルネックになっていないか確認する。ほかのサーバがボトルネックとなっている場合、サーバの種類に応じた解析を行う
- 続いて、GCログ解析を行い、GC発生状況がボトルネックとなっているか切り分ける。ここで、GC発生状況に問題がある場合、ヒープチューニングとオブジェクトプロファイリングへとつながっていく
- GCが発生していない場合、基本データで取得したCPUリソース状況を確認し、CPUボトルネックになっている場合は、メソッドプロファイリングへつながり、CPUボトルネックでない場合は、スレッドダンプ解析へと流れる
賢明な読者の皆さんはすでに気付いているかもしれないが、トラブル切り分けフローは上から下に流れるにつれ、ツールの利用のコストが掛かるようになっている。
障害を切り分けるときは、安易な憶測で適当にツールを利用するより、簡単に分析できるハードウェアリソース情報やGCログなど調べたうえで、考えられる障害の原因の範囲を狭めながら、詳細に調査をしていく方が効率の良い切り分けができる。適切な順序で適切なツールを導入して発生している問題を切り分け、無駄な分析を行わずに済むようにしていただきたい。
地道にボトルネックの直接の原因となっている部分を切り分けてトリルダウンすることが、結果的に迅速なトラブルシューティングにつながっていく。
トラブルシューティングの現場で迅速に問題を解決するためには、適切なタイミングで適切なツールを使うことが重要である。今回紹介した7つ道具が皆さんの迅速なトラブルシューティングの糸口になれば幸いである。
- 数百キロのコードでブルー - ドクターTomcat緊急救命
- DB操作の“壁”を壊すJPAが起こした「赤壁の戦い」
- アプリ開発でも、よ〜く考えよう。キャッシュは大事だよ
- スレッドダンプの森で覚えた死のロックへの違和感
- ThreadとHashMapに潜む無限回廊は実に面白い?
- JavaのGC頻度に惑わされた年末年始の苦いメモリ
- 肥え続けるTomcatと胃を痛めるトラブルハッカー
- 【トラブル大捜査線】失われたコネクションを追え!
- 【真夏の夜のミステリー】Tomcatを殺したのは誰だ?
- OutOfMemoryエラー発生!? GCがあるのに、なぜ?
- DBアクセスのトラブルは終盤で発覚しがち……
- 【実録ドキュメント】そのログ本当に必要ですか?
- “Stop the World”を防ぐコンカレントGCとは?
- Webアプリの問題点を「見える化」する7つ道具
関連記事
- Eclipse上でプロファイリングを実現する
連載:Eclipse徹底活用(6) コーディング作業とプロファイリングを繰り返しながらアプリケーションのチューニングができる。そんな便利なEclipseの活用法を紹介しよう - JMeterによるWebサーバ性能評価の勘所
連載:実用 Apache 2.0運用・管理術(2) サーバのボトルネックを見極めるには、適切な性能評価が必要。そこでツールを使った効果的な性能評価のポイントを紹介する - 事例に学ぶWebシステム開発のワンポイント
現場のエンジニアの経験から得られた、アプリケーション・サーバをベースとしたWebシステム開発におけるノウハウ、注意点について解説 - 第1回 クラスタ化すると遅くなる?(2002/3/9)
- 第2回 キャッシュが性能劣化をもたらす謎を解く(2002/3/23)
- 第3回 クラスタは何台までOK?(2002/4/19)
- 第4回 マルチスレッドのいたずらに注意(2002/5/14)
- 第5回 クラスタによるアプリケーションの動的アップデート(2002/6/4)
- 第6回 APサーバからの応答がなくなった、なぜ?(2002/11/30)
- 第7回 低負荷なのにCPU使用率が100%?(2002/12/11)
- 第8回 文字化け“???”の法則とその防止策(2003/1/28)
- 第9回 メモリは足りているのに“OutOfMemory”のなぞ(2003/2/15)
- 第10回 レスポンスキャッシュでパフォーマンス向上(2003/3/29)
- 第11回 JDBC接続を高速化―PreparedCacheの活用(2003/4/18)
- 第12回 ブラウザキャッシュでパフォーマンス向上(2003/5/10)
- 第13回 ファイルアップロード/ダウンロードに潜むわな(2003/6/12)
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。