Javaバッチフレームワークで多重実行、非同期実行:Javaバッチ処理は本当に業務で“使える”の?(4)(2/3 ページ)
TERAバッチでジョブの多重化をしてみよう!
では、先ほどの仕様のアプリケーションの多重化をしてみましょう。TERAバッチで必要な実装、プロジェクトのディレクトリ構成については、前回の「TERAバッチで必要なソースコード」の内容を参考にしてください。
ジョブBean定義ファイルの修正
ジョブBean定義ファイルを格納するフォルダを作成します。[パッケージエクスプローラ]ビューで、「terasoluna-batch-sample-foratmarkit04\batchapps\sample\UC0003\JB0001.xml」のジョブBean定義ファイルを以下のとおりに修正します。
<!-- トランザクションモデル別Bean定義ファイルのひな型をインポート --> |
このように、ひな型ファイルを「チャンク別トランザクション」モデルから「ジョブ分割チャンクトランザクションモデル」に変更するだけで、フレームワークの構造を簡単に切り替えることができます。
ジョブコンテキストの修正
ジョブコンテキストは分割ジョブが必要とする分割キーを設定します。「terasoluna-batch-sample-foratmarkit04\sources\jp\terasoluna\batch\sample\uc0003\JB0001JobContext.java」に対して、以下のような実装を追加することで分割キーを格納できるようになります。
/** |
分割キーの取得処理、多重実行の設定
次に、分割キーの取得について記述します。まずジョブBean定義ファイルに以下のとおりの記述を<beans></beans>のネスト内に追加します。
<!-- ジョブ分割キーのコレクター --> |
“partitionkeyCollector”はTERAバッチが提供する固定のBeanIDであり、“stringArrayPropertyPartitionKeyCollector”はTERAバッチが提供する文字列配列用の分割キー取得コレクターBeanであるため、これらの名称の変更はできません。分割キーの取得処理はこれ以外のコレクタを利用しても可能です。
また、同じくジョブBean定義ファイルに以下のとおりの記述を<beans></beans>のネスト内に追加します。
<!-- 多重実行数 --> |
上記では、分割した子ジョブの同時実行数を“multiplicity”というBeanIDにて指定しています。なお、“multiplicity”という名称はTERAバッチで定義されている名称なので変更することはできません。ここで指定した“3”の値によって、3つの子ジョブが作成されることになります。
対象データ取得処理の設定の修正
次に、子ジョブで実行される対象データ取得処理の設定を修正します。対象データ取得時に使用するSQL文は「terasoluna-batch-sample-foratmarkit04\batchapps\sample\UC0003\UC0003_sqlMap.xml」にすでに定義されているので、これを以下のとおりに分割ジョブ用に修正します。
<!-- 対象データ取得処理 --> |
上記のように記述することで、先ほどの分割キー取得にて定義した「東京」「大阪」「福岡」のそれぞれが子ジョブのジョブコンテキストに渡されているため、対象データを分割できます。なお、“partitionKey”という名称はTERAバッチで定義されている名称なので、変更はできません。
ジョブ後処理の修正
最後に、ジョブ後処理の修正を行います。ジョブの後処理は親ジョブ、子ジョブそれぞれで定義することが可能です。今回は、子ジョブの後処理を定義します。とはいっても、ジョブBean定義ファイルに関しては以下のとおりすでに記述されているので、特に変更する必要はありません。
<!--子ジョブ後処理--> |
もし、親ジョブの後処理を実行したい場合は、上記の書式を利用し、「id="jobPostLogicList"」の部分を「id="parentjobPreLogicList"」と記述すればOKです。なお、"jobPostLogicList""parentjobPreLogicList"という名称はTERAバッチで定義されている名称なので変更はできません。
次に、後処理の実装を分割キーによって処理されていることを分かりやすくするため、以下のように変更します。前回からログの書式を少々変更しているのみです。
/** |
ここまでで、ジョブ多重化のための実装終了です。
Eclipse上で実際に動作確認してみよう
それでは、実際に動かしてみましょう。Eclipse上でJavaアプリケーションとして起動します。
前回と同じ要領で、Eclipseの[実行]ダイアログを開き、[メイン]タブの[プロジェクト]に「terasoluna-batch-sample-foratmarkit04」を指定、[メイン・クラス]にTERAバッチが提供する「jp.terasoluna.fw.batch.springsupport.init.JobStarter」を指定します。
そして、[引数]タブの[プログラムの引数]において、第1引数にジョブID「JB0001」、第2引数にジョブBean定義ファイルのパス「sample/UC0003/JB0001.xml」を入力して、実行します。以下のように、ジョブの起動・終了に加え、処理件数のログが出力されれば、成功です。
| コンソール出力のイメージ |
[2008/06/23 15:27:46] [JobStarter ] [DEBUG] START Batch |
また、残高テーブルが以下のように更新されていることを確認してください。
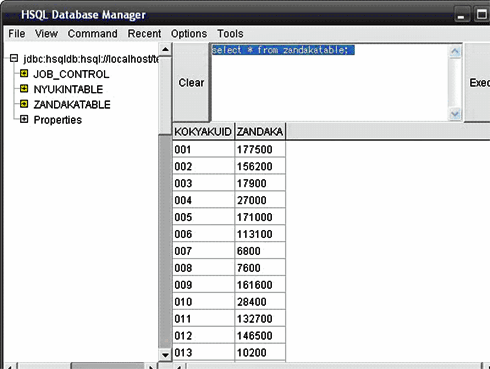 図5 多重化実行後の残高テーブルの確認例
図5 多重化実行後の残高テーブルの確認例いかがでしたか? ジョブの多重化という手法はバッチ処理を構築するうえでとても重要なものですので、このような方法もあるということを覚えておいていただけるとよいと思います。
同期実行? 非同期実行?
次に、ジョブの非同期実行について話を進めたいと思います。TERAバッチはバッチ処理の実行方法を大きく分けて2種類提供しています。
1つは「同期実行」というもので、いままでのように「コマンドラインからjavaコマンドでバッチアプリケーションを起動し、終了するまで待つ」というものです。
もう1つは「非同期実行」というもので、「ジョブ管理テーブルを監視し続ける常駐プロセスを起動し、ジョブ管理テーブルに登録されたジョブの情報に基づいてバッチ処理がバックグラウンドで実行される」というものです。TERAバッチでは、上記の常駐プロセスを「非同期バッチデーモン」と呼んでいます。
どのようなときに非同期実行を利用するかというと、昼間のオンライン処理が稼働している時間帯にオンラインアプリケーションから直接(比較的処理時間が短い)バッチ処理を呼び出す場合に利用します。特に、「オンライン・ディレード処理」と呼ばれるオンラインでバッチ処理を起動し、バッチ処理の終了前にユーザーに処理開始を知らせたい場合などに有効です。
この「非同期実行」によるバッチ処理を、TERAバッチを利用して実装するとどうなるのか、具体的に見ていきましょう。
次ページでは、TERAバッチでジョブの非同期実行をしていきます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。