管理が困難―分散処理の常識はZooKeeperで変わる:ビッグデータ処理の常識をJavaで身につける(8)(2/3 ページ)
■Replicate(冗長化)
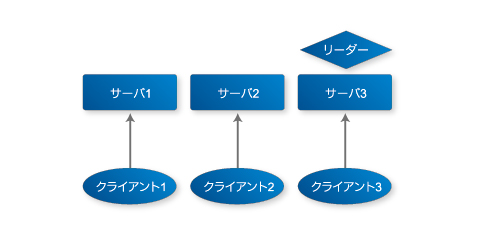
ZooKeeperは1台の計算機でも動作しますが、複数の計算機にもインストール(分散化)して利用できます。分散化することで性能を向上を期待できるとともに、データの欠損を防げます。
ZooKeeperを複数立ち上げると、リーダーが自動で選択され、トランザクションの管理を行います。クライアントは、どのZooKeeperサーバに接続してもデータの取得・書き換えを行えます。
■ウオッチ
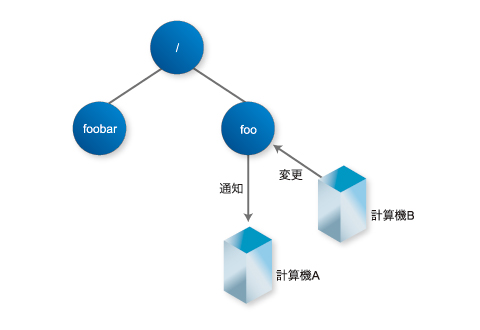
ZooKeeperが提供する特徴的な機能に「ウオッチ」があります。プロセスがZooKeeperの特定のノード(Znode)をウオッチの対象とすると、ノードに変更があった場合に、ウオッチの対象に設定したプロセスに通知が送られます。
例えば、分散システムの設定ファイルの内容を特定のZnodeに保存し、サーバBが設定ファイルを保持するZnodeをウオッチしたとします。後日Znodeの内容をサーバAが変更すると、サーバBに通知が行くため、このタイミングでサーバBは設定ファイルを再ロードできます。
ZooKeeperを利用するソフトウェア3選
Zookeeperは以下のようなソフトウェアで実際に利用されます。
■「HBase」分散Key-Valueデータベース
HBaseは分散Key-Valueデータベースとして有名です。HBaseは欠損したインスタンスの検知やクラスタ内の各インスタンスの状況把握にZooKeeperを利用しているそうです。
■SolrCloud
「SolrCloud」は、検索エンジン「Apache Solr」のZookeeperを利用した拡張です。SolrCloudは現在のバージョンのSolrには導入されていませんが、将来のバージョンで利用されるそうです。クラスタの設定ファイルの集中管理などでZooKeeperが使われるそうです。

「Jubatus(ユバタス)」はプリファードインフラストラクチャーとNTTによって共同で開発が進められている分散リアルタイムストリーミング処理エンジンです。オープンソースプロジェクトとして管理運営されています。
残念ながら筆者は内部について分かっていないので、開発に携わっている人にどのように利用しているのか尋ねてみました。「システムで利用できるインスタンスリストの管理(メンバー取得)と分割して保存されているデータデータに対するクエリの転送に利用している」とのことです。
Zookeeperを使う準備
実際にZooKeeperサーバを立ち上げて利用してみましょう。初めに、1つの計算機でZooKeeperを立ち上げて利用してみます。次に、複数(3台)のZooKeeperサーバを立ち上げて動作を確認してみます。
実際にサーバを立ち上げる前に、ZooKeeperを「Apache ZooKeeper - Releases」よりダウンロードしておいてください。その後、以下のコマンドで解凍してディレクトリを移動します。
$ tar zxvf zookeeper-3.3.4.tar.gz $ cd zookeeper-3.3.4
次ページでは、ZooKeeperの特徴をつかむために動かしてみましょう。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。