カラム指向型データベース(HBase、Hypertable、Cassandra)編:知らないなんて言えないNoSQLまとめ(3)(2/3 ページ)
LSM-Treeで永続化しつつ高速に書き込み
HBaseはLSM-Treeを採用しています。リージョンサーバが書き込み要求を受け取ると、HDFS上のHLog(BigtableのCommit Logに相当)ファイルに先行書き込みログを書き、続いて、メモリ上のMemStore(BigtableのMemtableに相当)にデータを格納します。MemStoreのサイズが設定値を越えると、HDFS上のHFile(BigtableのSS Tableに相当)にデータを移します。HFileの世代数が増えると読み込み性能が低下するため、定期的に複数の世代を1つのファイルにマージします。
この動作により、ハードディスク内のHDFSへの書き込みは、データの先頭から順番に行うシーケンシャルなものだけとなるため、書き込み性能が高くなります。
Apache ZooKeeperで障害検知
HBaseはApache ZooKeeper(以下、ZooKeeper)を用いてノードの死活監視を行い、障害ノードをクラスタから切り離します。なお、リージョンサーバには行ロック*4の機能がありますが、これはリージョンサーバ単独で実現されており、ZooKeeperのロック機能は使用していません。
MapReduce処理に対応
HBaseは、単体ではMapReduce処理の機能を持っていませんが、Hadoop MapReduceを利用できます。Hadoop MapReduceでHBaseテーブルにアクセスするためのライブラリが用意されており、さらに、高いパフォーマンスを得るために、MapReduceジョブから直接HFileに書き込むこともできます。
複数データセンターへ複製
バージョン 0.90では、HBaseクラスタ間のデータ複製機能が追加されました。この機能を使うと、遠隔地に配置されたHBaseクラスタにデータをバックアップしたり、高い応答性能が要求されるオンライン処理クラスタと、MapReduceを多用するバッチ処理やデータ分析向けのクラスタを分離したりできます。なお、データの複製処理は、性能面への影響を最小限に抑えるために非同期で実行されるので、クラスタ間のデータの整合性は結果整合性となります。
*4 行ロック 同一のデータに対し複数のクライアントからの要求により同時更新が行われないよう行レベルで排他制御するための仕組みです。
コ・プロセッサ機能を追加
バージョン0.92では、コ・プロセッサ機能が追加されます。これは簡単にいうと、従来のRDBMSのトリガ*5やストアドプロシージャ*6のようなものであり、Javaで記述します。現在、この機能を活用し、セカンダリインデックス*7のサポートや、暗号による認証方式の1つであるKerberosを用いたクライアント認証機能の開発が進められています。
書き込み速度が速いHypertable
Hypertableも、Bigtableに触発され開発されました。Zventsの社内ソフトウェアとして開発された後、オープンソースとしてリリースされました。中国の百度*8もHypertableのスポンサーとなっています。
HBaseと同様、稼働に際しては分散ファイルシステムが必須となり、Hadoopの分散ファイルシステムであるHDFSがよく使われています。
「Apache HBaseよりも高性能」とうたう
Hypertableの商用サポートを提供するHypertable Incは、性能比較試験の結果として「HypertableはHBaseよりも性能が高い」と公表しています(図1)*9。
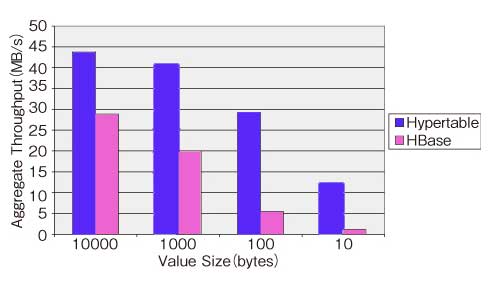 図1 HypertableとApache HBaseの書き込み性能比較
図1 HypertableとApache HBaseの書き込み性能比較*5 トリガ 正しくはデータベーストリガという。データが変更された時に自動的に実行される処理です。
*6 ストアドプロシージャ データベースに対する一連の処理をまとめた手続きにして、DBMSに保存(永続化)したものを指す。
*7 セカンダリインデックス 主キーによるインデックス(索引)以外のインデックスです。これにより検索をさらに効率よく実行できるようになります。
*8 百度(バイドゥ) 「中国の Google」とも呼ばれている検索エンジンを提供する中国企業です。
*9 http://www.hypertable.com/pub/perfeval/test1/を参照。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。