Playで体得するRESTfulアーキテクチャの基礎知識:Javaの常識を変えるPlay framework入門(5)(1/3 ページ)
サーブレット/JSPを基にする重厚長大なJavaのWeb開発のイメージを変える軽量フレームワーク「Play」について解説し、Webアプリの作り方を紹介する入門連載。今回は、RESTの概要、URIの概念、RESTで使われるHTTPメソッドとステータスコード、PlayでのRESTfulな設計、実装上の問題点などを解説します。
RESTを理解すると、Play frameworkが分かる
前回記事「Play frameworkのコントローラの使い方を理解する」までは、Javaを使う観点からPlay frameworkを紹介してきました。しかし、今回は視点を変えて、言語による実装方法ではなくPlay frameworkが得意とするソフトウェア・アーキテクチャのパターンである「REST」をターゲットとして紹介します。
RESTを理解したうえでPlay frameworkを見てみると、よりPlay frameworkが求めるシステム像が見えてくるかと思いますので今回はRESTの概念に重点を置いて以下の内容で紹介していきます。
RESTの概要
「RESTって何?」という方もいるかと思うので、まずはRESTについて簡単に説明します。RESTとは「REpresentational State Transfer」の略語であり、2000年にHTTPプロトコル規格の代表者の1人であるRoy Fielding氏が提唱した分散システムにおけるソフトウェア・アーキテクチャのパターンのことです。そのRESTの原則に従ったシステムのことをRESTfulなシステムといいます。
RESTfulなシステムの特徴は、セッションやクッキーなどでクライアント・サーバ間の情報を持ち続けず、同じURIでアクセスしたら毎回同じリソース(情報)が取得でき、HTTPで定義されたコマンドのみでシステムを操作できることです。
RESTでの基本となる原則は4つあり、以下のものになります。
- リソース(情報)をURIで識別できること
- HTTPで、すでに定義されているコマンドとステータスコードに従って操作できること
- ステートレスなクライアント・サーバ間のやりとりをすること
- 他の情報へのリンクを持つことができること
今回はRESTの基本原則のうち、1と2の「リソース(情報)をURIで識別できること」「HTTPで、すでに定義されているコマンドに従って操作できること」についてPlay frameworkとの関係を説明していきます。
ちなみに、他の3と4の2つの解説を除いた理由ですが、Webシステムによっては例えば認証が必要なシステムなどステートレス(セッションやクッキーを使わない状態)であり続けるのが難しいものがあるのと、リンクは普段、皆さんが使っているので、今さら述べるほどのことでもないからです。
リソース(情報)を識別するURIの概念
RESTの基本原則の1つにリソースをURIで識別できることがありますが、これは同じURIが示す情報は情報元が更新や削除をされない限り、毎回同じ情報になるということです。
このリソースとURIの関係をイメージしやすいのはフォルダ構成とアドレスの関係かと思います。例えば、下記のようなC直下にある「サンプル」というフォルダに年月日ごとの記事があったとします。
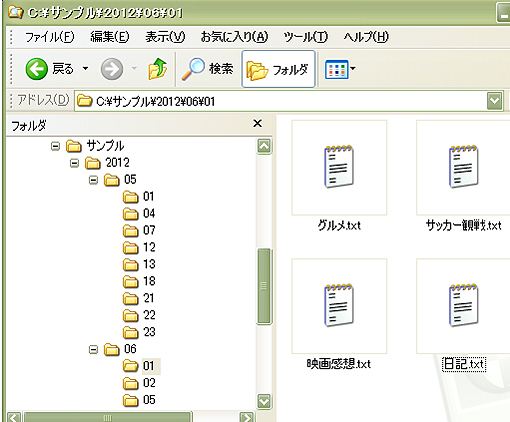
ここで2012年6月1日のリソースにアクセスしたい場合は、アドレスに「C:\サンプル\2012\06\01\」と入力すると、そこのフォルダにアクセスでき、ファイルやフォルダの一覧が表示されます。また2012年6月のリソースなら、「C:\サンプル\2012\06\」とアドレスに入力すれば、その月の各日々のフォルダの一覧が表示されます。
このように、指定したアドレスに意味を持たせ、そこにアクセスすれば、そのリソース(ここではファイルやフォルダ)があるようなことをURIで表現するのがURIでリソースを識別する考え方です。
それではWebシステムではどうなるのか? 先ほどの例をブログサイトに例えてみましょう。下記のようなURIを使うと、年月日ごとにブログ記事のリソースを取得するように設計可能です。
| URI | リソース |
|---|---|
| http://……/2012/ | 2012年のブログ記事の一覧 |
| http://……/2012/06/ | 2012年6月のブログ記事の一覧 |
| http://……/2012/06/01 | 2012年6月1日のブログ記事の一覧 |
また、年月日での区分けではなく下記のようにブログ記事のカテゴリごとにリソースを取得できるようにすることも可能です。
| URI | リソース |
|---|---|
| http://……/foods/ | グルメについてのブログ記事の一覧 |
| http://……/sports/ | スポーツについてのブログ記事の一覧 |
| http://……/movies/ | 映画についてのブログ記事の一覧 |
| http://……/diaries/ | 日記についてのブログ記事の一覧 |
さて、URIでリソースを識別できることによって、どんな利点があるのでしょうか?
まず考えられるのは、URIで何のリソースがあるのか直感的に分かりやすいことが挙げられます。例えば、リソースの指定を全てパラメータで指定した場合に上記のブログサイトで年月日を示すには、以下のように長くなってしまいます。
http://……/blog?year=2012&month=6&day=1
この程度ならまだ許容できる範囲ですが、さらに年月日のほかに長文のような情報があった場合は、パラメータがさらに追加され長くなってしまいます。そして、目的のリソースにアクセスするためには指定するパラメータ名自体を知らなければならなくなってしまいます。
さらに、URIでリソースを指定できる場合、ブックマークの設定時の仕組みが作りやすいという利点があります。よくあるのが全て情報をPOSTメソッドで遷移していくシステムだと、まずURIが変わらないのでブックマークするURIが特定できません。そうなると毎回トップページからの遷移になってしまいます。
ブックマークしたいページがトップページから深いリンクをたどる場合は、毎回深いリンクをたどらねばならず、ユーザーにとって使い勝手が良いサイトではなく、かつ開発者にとっては確認やテストするのも時間が奪われてしまいます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。