曌嫮夛偱柧傜偐偵側偭偨堛椕岦偗OSS偺懡條側妶梡朄劅劅揹巕僇儖僥丄椪彴帋尡僨乕僞夝愅丄擔杮岅堛妛梡岅僾儔僢僩僼僅乕儉丄夋憸DB丗僿儖僗働傾偩偗偱廔傢傜偣側偄堛椕IT乮6乯乮3/4 儁乕僕乯
亂Myna亃OSS傪嬱巊偟偰擔杮岅堛妛梡岅僾儔僢僩僼僅乕儉偺峔抸偵挧傓
丂垽昋戝妛 堛椕忣曬晹偺栘懞塮慞巵偑乽堛椕僞乕儈僲儘僕乕 Web Services乿偲戣偟偰峴偭偨曬崘偱偼丄暷崙偵戝偒偔屻傟傪庢偭偰偒偨崙撪偺堛妛梡岅僾儔僢僩僼僅乕儉偺惍旛傪恦懍偵恑傔傞偙偲傪栚巜偟偰丄OSS傪嬱巊偟偨擔杮岅堛妛梡岅僾儔僢僩僼僅乕儉乽Myna乿偺峔抸偵岦偗偨庢傝慻傒傪奐巒偟偰偄傞偙偲偑柧傜偐偵偝傟偨丅
丂Myna偺摿挜偼丄暷崙偺堛妛梡岅僾儔僢僩僼僅乕儉偲偼堎側傝丄Ubuntu傗Vagrant丄MySQL丄Ruby丄Rails丄Grape側偳偺OSS傗丄OSS偺奐敪丒岞奐庤朄傪揙掙揑偵妶梡偟偰峔抸傪恑傔偰偄傞偙偲偩丅2015擭廐偵偼丄塸岅乣擔杮岅偺婡夿揑徠崌傪峴偭偨梡岅傪悢廫枩岅儗儀儖偱岞奐偡傞梊掕偱丄僐儈儏僯僥傿偺椡傪寢廤偟偰愻楙壔嶌嬈傪恑傔偰偄偔丅偨偩偟丄儔僀僙儞僗丒挊嶌尃娭學偺栤戣偑僋儕傾偵側傞傑偱偼丄僋儘乕僘僪側娗棟幰搊榐惂偵傛傞岞奐偲側傞丅
 Myna偺傾乕僉僥僋僠儍乮栘懞巵偺島墘帒椏傛傝乯
Myna偺傾乕僉僥僋僠儍乮栘懞巵偺島墘帒椏傛傝乯丂Myna偼丄戝偒偔嶰偮偺僐儞億乕僱儞僩偱峔惉偝傟偰偄傞丅堦偮偼丄崙嵺堛妛梡岅僨乕僞儀乕僗乽SNOMED CT乿傪婎偵塸岅偲擔杮岅傪儅僢僺儞僌偟偨SNS巜岦偺僞乕儈僲儘僕乮梡岅懱宯乯僨乕僞儀乕僗偱偁傞丅栘懞巵偼乽偙偺僨乕僞儀乕僗傪岞奐偟丄僐儈儏僯僥傿偺椡偱僽儔僢僔儏傾僢僾偟偰偄偔乿偲愢柧偟偰偄傞丅
丂僐儞億乕僱儞僩偺擇偮栚偼丄堛椕僾儘僙僗偲捈寢偡傞忣曬嶲徠儌僨儖傪採嫙偡傞乽OpenEHR乿傗丄REST乛JSON儀乕僗偱峔抸偝傟偨堛椕忣曬儕僜乕僗乽FHIR乮Fast Healthcare Interoperability Resources乯乿側偳偲API楢実偱偒傞僞乕儈僲儘僕乕丒僒乕價僗丅偦偟偰嶰偮栚偼丄堦斒儐乕僓乕偑棙梡偱偒傞堛妛帿彂偲偟偰採嫙偡傞僨乕僞攝晍僒乕價僗偱偁傞丅
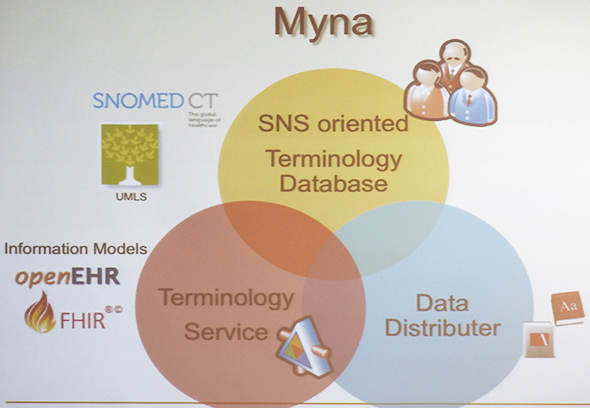 Myna偺僐儞億乕僱儞僩峔惉乮栘懞巵偺島墘帒椏傛傝乯
Myna偺僐儞億乕僱儞僩峔惉乮栘懞巵偺島墘帒椏傛傝乯丂偪側傒偵丄Myna偲偄偆柤徧偼丄尵梩傪榖偣傞儉僋僪儕壢偺捁傪桼棃偲偟偰偍傝丄悽奅拞偱尒傜傟傞捁偱偁傞偙偲偐傜嵦梡偝傟傞偙偲偵側偭偨偲偄偆丅
暷崙偵屻傟傪庢傞擔杮偺堛妛梡岅娐嫬
丂Myna偺奐敪偑巒傑偭偨攚宨偵偼丄堛妛梡岅僾儔僢僩僼僅乕儉偺峔抸偍傛傃妶梡偱暷崙偵戝偒偔屻傟傪庢偭偰偄傞偲偄偆尰幚偑偁傞丅暷崙偱偼丄偡偱偵20擭傕慜偐傜丄NLM乮暷崙崙棫堛妛恾彂娰乯偑堛妛梡岅傪摑堦揑偵栐梾偡傞摑崌堛妛梡岅僔僗僥儉乽UMLS乮Unified Medical Language System乯乿傪峔抸偟偰偍傝丄枅擭偍傛偦2000枩僪儖婯柾偺梊嶼偑搳偠傜傟偰偒偨丅UMLS偱偼丄2015擭尰嵼丄弮悎側奣擮偱311枩屄丄尵梩偺梙傟傪娷傓堛妛梡岅偱1200枩屄偵忋偭偰偄傞乮恾乯丅
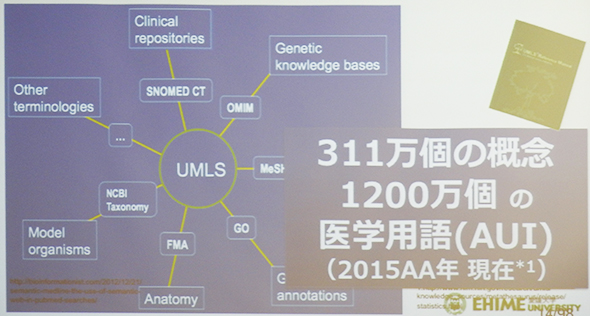 UMLS乮Unified Medical Language System乯乮栘懞巵偺島墘帒椏傛傝乯
UMLS乮Unified Medical Language System乯乮栘懞巵偺島墘帒椏傛傝乯丂堦曽丄擔杮偺帠忣偼偳偆偐丅栘懞巵偵傛傞偲丄崙撪偱傕夁嫀偵丄岤惗楯摥壢妛尋媶偺堦娐偲偟偰丄僔僜乕儔僗乮奣擮暘椶帿彂乯偺惍旛偑恑傔傜傟丄擔杮堛妛梡岅帿揟偲偄偆宍偱岞奐偝傟偰偄傞偑丄僾儘僾儔僀僄僞儕側僨乕僞儀乕僗偵偡偓偢丄OSS偱偺妶梡偼偱偒側偄偲偄偆丅
 垽昋戝妛 堛椕忣曬晹 栘懞塮慞巵
垽昋戝妛 堛椕忣曬晹 栘懞塮慞巵丂堛妛梡岅僾儔僢僩僼僅乕儉偵偍偗傞丄20擭偱椵寁悢壄僪儖偲偄偆戝偒側屻傟傪偳偺傛偆偵庢傝栠偣偽偄偄偺偐丅栘懞巵偼丄乽Bazzar儌僨儖傪嵦梡偟偰丄僐儈儏僯僥傿偺椡傪寢廤偡傟偽屻傟傪庢傝栠偣傞壜擻惈偑偁傞乿偲嫮挷偡傞丅
丂栘懞巵偺尵偆Bazzar儌僨儖偲偼丄OSS奐敪巚憐傪榑偠偨Eric S. Raymond巵偺榑暥亀The Cathedral and the bazzar乮壘棔偲僶僓乕儖乯亁傪嶲峫偵偟偨傕偺偱丄OSS偺奐敪儌僨儖傪巜偡丅堦曽丄僾儘僾儔僀僄僞儕側奐敪儌僨儖偼Cathedral儌僨儖偲偄偆偙偲偵側傞丅
丂UMLS偼丄僨乕僞偙偦岞奐偝傟偰偄傞偑丄奐敪儌僨儖偱尒傞偲丄摿掕暘栰偺愱栧壠廤抍偑崙壠揑側僀儞僼儔偲偟偰僾儘僾儔僀僄僞儕側娐嫬偱奐敪傪恑傔傞Cathedral儌僨儖偱偁傝丄Bazzar儌僨儖偵傛偭偰愱栧偺堛巘傪堷偒崬傒側偑傜丄僐儈儏僯僥傿偑椡傪寢廤偟偰庢傝慻傔偽廫暘偵懳峈偱偒傞偲偄偆傢偗偩丅
丂栘懞巵偵傛傞偲丄僆乕僾儞僜乕僗偺儌僨儖傪儀乕僗偲偡傞Bazzar儌僨儖偵傛偭偰奣擮丒抦幆僨乕僞儀乕僗傪峔抸偡傞庢傝慻傒偲偟偰偼丄偡偱偵擇偮偺愭椺偑偁傞偲偄偆丅堦偮偼丄桳巙偑廤傑偭偰堛妛梡岅偺僙儅儞僥僢僋丒僱僢僩儚乕僋傪峔抸丒岞奐偟偰偄傞墷廈偺乽OpenGALEN乿丅傕偆堦偮偼丄堛椕忣曬傪傾乕僋僞僀僾偲偄偆忣曬扨埵偵傑偲傔偰岞奐偟偰偄傞摨偠偔墷廈偺乽OpenEHR乿偱偁傞丅OpenEHR偱偼丄僋儕僄僀僥傿僽丒僐儌儞僘偵婎偯偄偰丄僐儈儏僯僥傿偺惉壥暔偱偁傞傾乕僋僞僀僾傪堦斒偺棙梡幰偵巊梡嫋戻偡傞儔僀僙儞僔儞僌偑峴傢傟偰偄傞丅
丂栘懞巵偵傛傞偲丄Myna僾儘僕僃僋僩偱偼丄MEDIS乮堛椕忣曬僔僗僥儉奐敪僙儞僞乕乯偺昗弨昦柤儅僗僞乕傗崙嵺堛椕梡岅廤偺乽SNOMED-CT乿偲偄偆堎側傞儔僀僙儞僔偺惉壥暔傪婎偵僐儈儏僯僥傿偺庤偱僐儞僙僾僩儅僢僾傪峔抸偡傞偙偲傪梊掕偟偰偄傞丅Myna傪惓幃偵岞奐偡傞偵摉偨偭偰偼丄偙傟傜偺儔僀僙儞僗偺栤戣傪夝寛偟偰偍偔昁梫偑偁傞丅尰嵼丄僋儕僄僀僥傿僽丒僐儌儞僘側偳偺庢傝慻傒傪嶲峫偵偱偒傞偐丄尃棙傪偳偙偵婣懏偝偣傞偺偐側偳丄儔僀僙儞僗偺栤戣偺夝寛偵岦偗偨庢傝慻傒傪恑傔偰偄傞偲偄偆丅
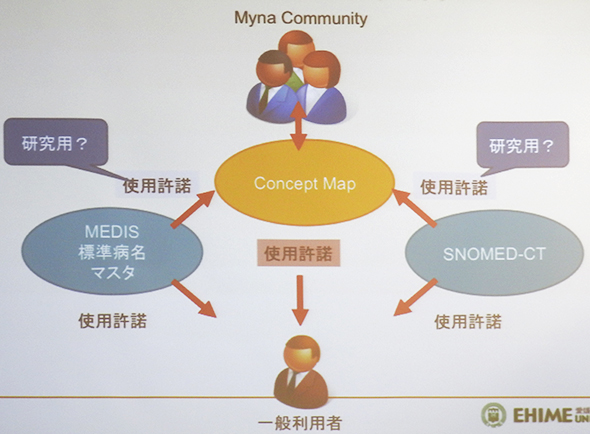 儔僀僙儞僗偺娭學乮栘懞巵偺島墘帒椏傛傝乯
儔僀僙儞僗偺娭學乮栘懞巵偺島墘帒椏傛傝乯梡岅娐嫬偺惍旛偑Watson偺堛椕妶梡傪屻墴偟
丂堛妛梡岅僾儔僢僩僼僅乕儉偺屻傟偼擔杮偺堛椕IT慡懱偺敪揥偵儅僀僫僗偺塭嬁傪梌偊偰偄傞丅偦偺戙昞椺偑丄恖岺抦擻乮AI乯偺妶梡偱偁傞丅
丂暷崙偱偼丄偡偱偵IBM偑奐敪偟偨乽Watson乿偑堛椕暘栰偱梡岅僔僗僥儉偲楢実偡傞宍偱杮奿揑偵妶梡偝傟巒傔偰偄傞乮徻嵶偼乽Watson偼僗儅乕僩僼僅儞乛僂僃傾儔僽儖抂枛偱廂廤偟偨儐乕僓乕僨乕僞偺妶梡偱堛椕IT傪妚怴偱偒傞偺偐乿傪嶲徠乯丅栘懞巵偼丄乽IBM Watson偑丄幚嵺偵揹巕僇儖僥忋偱偑傫姵幰偵搳梌偡傞偺偵揔愗側峈偑傫嵻傪儅僢僠儞僌偝偣偰偄傞偺傪尒偰丄乬崟慏棃峲乭偺傛偆側徴寕傪庴偗偨丅擔杮偱偺AI偺妶梡偼20擭傎偳慜偐傜幐攕偺楢懕偱丄幚嵺偵巊偊傞偲偼巚偭偰偄側偐偭偨乿偲愢柧偡傞丅
丂Watson偑僋儔僂僪忋偱採嫙偟偰偄傞僒乕價僗偺偆偪丄栘懞巵偑偲傝傢偗拲栚偟偰偄傞偺偑丄乽Concept Expansion乿偲偄偆僒乕價僗偱偁傞丅偙傟偼丄帺慠尵岅偺暥傪夝愅偡傞嵺偵丄奣擮揑偵嬤偄扨岅傪帺摦揑偵廂廤偡傞婡擻傪採嫙偡傞傕偺偩丅栘懞巵偼丄堦掕検偺塸岅暥傪棳偟崬傫偱丄乽drag乿偲偄偆扨岅偵嬤偄奣擮傪夝愅偝偣偰傒偨偲偙傠丄乽儁僯僔儕儞乿偑栻偵娭學偡傞傕偺偩偲偄偆偙偲傪傑偭偨偔嫵偊偰偄側偄偵傕偐偐傢傜偢丄崅偄僗僐傾偱乽penicillin乿偲偄偆寢壥偑摫偒弌偝傟偨偲偄偆僨儌帠椺傪徯夘偟偨丅
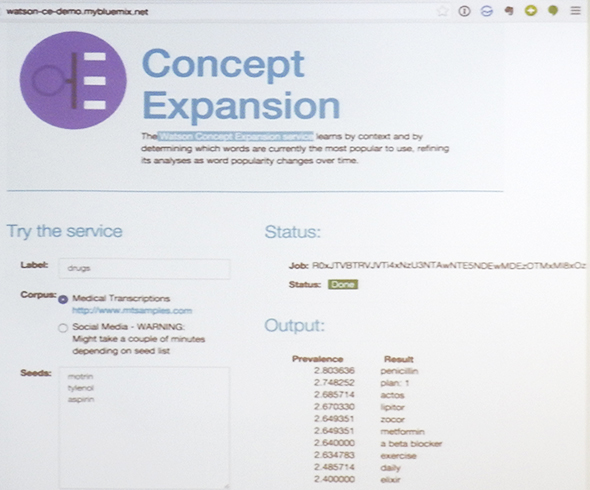 Watson偺幚峴寢壥乮栘懞巵偺島墘帒椏傛傝乯
Watson偺幚峴寢壥乮栘懞巵偺島墘帒椏傛傝乯丂偟偐偟丄栘懞巵偵傛傞偲丄Watson偺僒乕價僗偼乽偦傟偧傟偺扨岅傪奣擮偲偟偰棟夝偡傞亀嫮偄AI亁偱偼側偔丄幙栤偝傟偨僉乕儚乕僪偵嬤偄扨岅傪嫟婲乮摨帪偵弌尰偡傞嫍棧乯傑偨偼弌尰昿搙傪婎偵丄奣擮揑偵嬤偄扨岅傪摫偒弌偡亀庛偄AI亁偵偡偓側偄乿偲偄偆丅摉慠丄椪彴尰応偵偍偄偰傕丄椪彴奣擮傪棟夝偡傞傢偗偱偼側偄偨傔丄堛巘偺乬椪彴敾抐偵昁梫側忣曬乭偼採嫙偱偒傞傕偺偺丄乬椪彴敾抐偦偺傕偺乭偼戙懼偡傞偙偲偼偱偒側偄丅
丂嫮偄AI偼丄奣擮傪僉僠儞偲棟夝偟偰丄椶悇乛悇榑丄栤戣夝寛偡傞乽僆儞僩儘僕乮Ontology乯乿婡擻傪巊偭偰丄偁傜備傞扨岅傗奣擮偺娭學傪丄嵶偐偔捛媮偟偰偄偔偙偲偵傛偭偰丄恖娫偵嬤偄椪彴敾抐傪壜擻偵偡傞傕偺偩丅擔杮偱傕20擭傕慜偐傜尋媶偑恑傔傜傟偒偨偑丄幚梡壔偵偼帄偭偰偄側偄丅
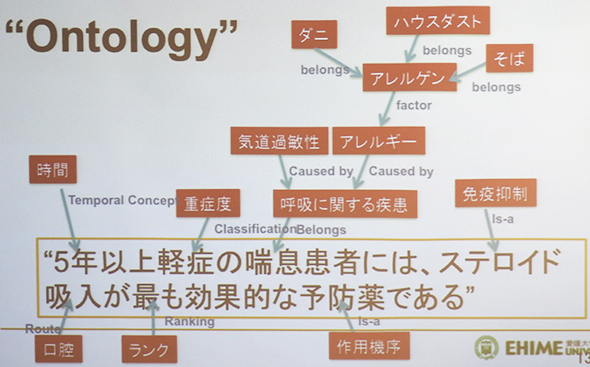 僐儞僺儏乕僞乕偑奣擮傪棟夝偡傞巇慻傒
僐儞僺儏乕僞乕偑奣擮傪棟夝偡傞巇慻傒丂Watson偼丄庛偄AI偺婡擻偲丄摑崌堛妛梡岅僔僗僥儉偺UMLS傗惗暔堛妛宯暥專僨乕僞儀乕僗偺MEDLINE丄儔僀僼僒僀僄儞僗摿嫋暥彂側偳傪楢実偝偣傞偙偲偵傛偭偰丄嫮偄AI偵旵揋偡傞崅偄AI惈擻傪堷偒弌偟丄崅搙側恌抐巟墖傪幚尰偟偰偄傞丅巆擮側偑傜丄擔杮偵偼偙偺傛偆側岅渂丒奣擮儕僜乕僗偼惍旛偝傟偰偍傜偢丄堛椕IT偱戝偒側屻傟傪庢偭偰偄傞偺偑尰忬偩丅Myna僾儘僕僃僋僩偵傛偭偰丄偙偆偟偨屻傟偑憗媫偵崕暈偝傟傞偙偲偑婜懸偝傟傞丅
娭楢婰帠
 Apple Watch傗僎僲儉夝愅偲傕楢実乗乗乽僋儔僂僪宆揹巕僇儖僥乿傪僾儔僢僩僼僅乕儉偲偡傞怴偟偄乽堛椕乿偺壜擻惈
Apple Watch傗僎僲儉夝愅偲傕楢実乗乗乽僋儔僂僪宆揹巕僇儖僥乿傪僾儔僢僩僼僅乕儉偲偡傞怴偟偄乽堛椕乿偺壜擻惈
擔杮偱峔抸偑媫偑傟偰偄傞乽抧堟曪妵働傾僔僗僥儉乿偺廳梫側婎斦偲峫偊傜傟偰偄傞乽揹巕僇儖僥乿僔僗僥儉丅僋儔僂僪宆揹巕僇儖僥偑堛椕僨乕僞拁愊偺偨傔偺僾儔僢僩僼僅乕儉偲側傞偙偲偵傛傝丄堛椕偦偺傕偺偺恑壔傪屻墴偟偡傞壜擻惈傕惗傑傟偰偄傞偲偄偆丅 Watson偼僗儅乕僩僼僅儞乛僂僃傾儔僽儖抂枛偱廂廤偟偨儐乕僓乕僨乕僞偺妶梡偱堛椕IT傪妚怴偱偒傞偺偐
Watson偼僗儅乕僩僼僅儞乛僂僃傾儔僽儖抂枛偱廂廤偟偨儐乕僓乕僨乕僞偺妶梡偱堛椕IT傪妚怴偱偒傞偺偐
乽IBM Watson乿偼丄僗儅乕僩僼僅儞傗僂僃傾儔僽儖抂枛側偳偺僨僶僀僗偐傜廂廤偟偨僨乕僞偲丄揹巕僇儖僥傗堚揱巕忣曬側偳偺朿戝側堛椕忣曬偲傪桳婡揑偵寢傃晅偗偰堛椕尰応偺妶摦傪巟墖偱偒傞擣抦僔僗僥儉偲偟偰拲栚傪廤傔偰偄傞丅杮峞偱偼丄2015擭5寧19擔丄20擔偵搶嫗偱奐嵜偝傟偨乽IBM XCITE SPRING 2015乿偱偺島墘撪梕傪婎偵丄IBM Watson偑偳偺傛偆偵恑壔偟丄堛椕傗儔僀僼僒僀僄儞僗暘栰偱妶梡偝傟傛偆偲偟偰偄傞偺偐傪徯夘偡傞丅 僗儅乕僩僨僶僀僗偐傜偺儘僌丄昦堾DB丄堛椕婡婍偐傜摼傞夋憸乗乗堛椕尰応偺價僢僌僨乕僞妶梡傪幚慔偡傞3幮偺帠椺
僗儅乕僩僨僶僀僗偐傜偺儘僌丄昦堾DB丄堛椕婡婍偐傜摼傞夋憸乗乗堛椕尰応偺價僢僌僨乕僞妶梡傪幚慔偡傞3幮偺帠椺
堛椕丄僿儖僗働傾偵娭楢偟偨僥僋僲儘僕價僕僱僗傗僗僞乕僩傾僢僾偺摦岦傪丄僄儞僕僯傾傗價僕僱僗儅儞偵懳偟偰徯夘偡傞僀儀儞僩乽Digital Health Meetup Vol.2乿偺僺僢僠僙僢僔儑儞偐傜3幮偺堛椕儀儞僠儍乕偑奐敪偟偨僒乕價僗傗傾僾儕偺帠椺傪偍揱偊偡傞丅 尰栶堛巘傗堛椕儀儞僠儍乕偑岅傞丄堛巘夛丄IT妶梡丄挻崅楊幰丄偦偟偰枹棃傊
尰栶堛巘傗堛椕儀儞僠儍乕偑岅傞丄堛巘夛丄IT妶梡丄挻崅楊幰丄偦偟偰枹棃傊
堛椕丄僿儖僗働傾偵娭楢偟偨僥僋僲儘僕價僕僱僗傗僗僞乕僩傾僢僾偺摦岦傪丄僄儞僕僯傾傗價僕僱僗儅儞偵懳偟偰徯夘偡傞僀儀儞僩乽Digital Health Meetup Vol.2乿偺僷僱儖僨傿僗僇僢僔儑儞乽堛椕妚柦両 堛巘偺IT妶梡偲偦偺枹棃偵偮偄偰乿偺柾條傪偍揱偊偡傞丅 2025擭栤戣丄儅僀僫儞僶乕丄夵惓栻帠朄乗乗奐敪幰偑乽桞堦偺惉挿巗応乿僿儖僗働傾乛堛椕偵嶲擖偡傞嵺偺壽戣偲偼
2025擭栤戣丄儅僀僫儞僶乕丄夵惓栻帠朄乗乗奐敪幰偑乽桞堦偺惉挿巗応乿僿儖僗働傾乛堛椕偵嶲擖偡傞嵺偺壽戣偲偼
堛椕丄僿儖僗働傾偵娭楢偟偨僥僋僲儘僕價僕僱僗傗僗僞乕僩傾僢僾偺摦岦傪丄僄儞僕僯傾傗價僕僱僗儅儞偵懳偟偰徯夘偡傞僀儀儞僩乽Digital Health Meetup Vol.2乿偺島墘乽堛椕惌嶔偺摦岦偐傜撉傒夝偔丄偙傟偐傜偺堛椕丒夘岇嬈奅乿偺柾條偐傜僿儖僗働傾乛堛椕嬈奅偵墶偨傢傞壽戣傪傑偲傔偰偍揱偊偡傞丅 堛椕亊IT丂堛巘偼僾儘僌儔儈儞僌偱堛椕偺巇慻傒傪曄偊傜傟傞偐
堛椕亊IT丂堛巘偼僾儘僌儔儈儞僌偱堛椕偺巇慻傒傪曄偊傜傟傞偐
僾儘僌儔儈儞僌偼僾儘僌儔儅乕偩偗偺摿尃偱偼側偄丠乗乗IT傪妶梡偟偰帺恎偺愱栧暘栰傪傛傝椙偔偟偰偄偙偆偲僠儍儗儞僕偟偰偄傞恖偨偪偵偍榖傪巉偆僀儞僞價儏乕僔儕乕僘丄杮擔巒摦丅 傾僢僾儖偑GitHub偵岞奐偟偨堛椕偺尋媶挷嵏梡OSS僼儗乕儉儚乕僋乽ResearchKit乿偺婎慴抦幆
傾僢僾儖偑GitHub偵岞奐偟偨堛椕偺尋媶挷嵏梡OSS僼儗乕儉儚乕僋乽ResearchKit乿偺婎慴抦幆
暷傾僢僾儖偑2015擭4寧14擔偵GitHub偵岞奐偟偨堛椕偺尋媶挷嵏梡OSS僼儗乕儉儚乕僋乽ResearchKit乿偵偮偄偰丄奣梫傗婡擻丄尰帪揰偱偱偒側偄偙偲丄偳偺傛偆側傾僾儕偑嶌傟傞偐偵偮偄偰徯夘偡傞丅 堛幰偼IT媄弍傪妛傃丄僄儞僕僯傾偼堛妛傪妛傇帪戙
堛幰偼IT媄弍傪妛傃丄僄儞僕僯傾偼堛妛傪妛傇帪戙
2013擭8寧31擔丄乽10擭屻偺堛椕乿傪僥乕儅偵擔杮奺抧偐傜1000恖偺堛妛惗偑搒撪偵廤寢丅乽Medical Future Fes 2013乿偑奐嵜偝傟偨丅
Copyright © ITmedia, Inc. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅