「人間行動」と「検索」の関係に見る、機能改善に本当に必要だったもの:機械学習活用プロジェクト大解剖(終)(1/2 ページ)
サイト内検索のランキングアルゴリズムに機械学習を活用した事例を通じて、Deep Learningをはじめとした機械学習の強みと限界を探る連載。今回は、Deep Learning以外の手法で検索改善に大きく貢献した事例を基に、「検索改善に本当に必要だったものは何だったのか」を振り返ります。
リクルートテクノロジーズにおける検索改善施策の事例を通じて、Deep Learningをはじめとした機械学習の強みと限界を探る本連載「機械学習活用プロジェクト大解剖」。
前回で、Deep Learningの導入のために何が必要であり、そのために「なぜ検索改善のためのアーキテクチャ(QueryRewriter)が開発されたか」について解説しました。今回は、Deep Learning以外の手法で検索改善に大きく貢献した事例を基に、「検索改善に本当に必要だったものは何だったのか」を振り返ります。
先にまとめてしまうと、検索改善に本当に必要だったものは以下の通りです。
- 「どこにどのくらい課題があるか」を定量的に示して、それを改善の指標にする
- 仮説を基にモデルを組んで、そのモデルの特性を考慮した上で、方針を決める
改善すべき対象の定量化
多くの人はWebサイトの利用者として検索機能を使っていて、「何か……思ったような検索結果が返ってこない」と思ったことがあるでしょう。しかし、「何がどのくらい悪いのか」、定量的に測るのは難しいと感じると思います。検索改善を実施するに当たっては、ここを真正面に定量的に捉えて改善していく必要があります。
検索の分野では検索の良しあしを表すための定量的な指標として、適合率・再現率といった指標があります。適合率・再現率については記事「ElasticsearchとKuromojiを使った形態素解析とN-Gramによる検索の適合率と再現率の向上」を参照してください。
「ただ適合率・再現率を上げる」という単純な話ではありません。上記のリンク記事でも触れている通り、適合率・再現率を算出する方法は、どんな場合でも一意に「これだ」と決められるものではないからです。
極端な例を挙げると、同じ「はし」というキーワードでも、「橋」を検索したい人と、「箸」を検索したい人がいます。つまり、キーワード適合率はサービスを使う人によって違うのです。
適合率の定量化
しかし、「全ての人に対する」適合率の定量化を目指さなくても、「多くの人に対する」適合率の方は、実サービスサイトでは比較的簡単に定量化できます。実サービスサイトには、定量化するための、信頼できる行動履歴データが豊富にあるからです。実サービスサイトで信頼できるデータが得られる理由は、「購入」「申し込み」といったコンバージョンが、利用者にとってある程度の決断を伴うものであり、ユーザーの本当の欲求に近いものを知ることができるからです。
求人情報サイトを例にとって考えてみましょう。求人情報サイトでは、さまざまなスキルや志向を持つ人が求人情報を検索します。例えば、求人情報サイトで「ホテル」というキーワードで検索する人がいたとします。このキーワードでユーザーがたどり着きたかったのはどんな求人だったのでしょうか? 「ホテルでの接客経験を求める」仕事でしょうか? それとも「ホテル業界」での仕事でしょうか? または「保養所に提携ホテル」がある職場でしょうか? それはデータを見れば分かります。求人情報サイトでいえば、「ホテル」を検索した後、実際に応募した求人を、「求人の職種・業種・条件ごと」に集計したデータを見て、次のようになっていたとしましょう。

この場合は集計されたデータを見ることにより、多くのユーザーにとって「ホテル」は「ホテル業界の求人」を意味することが分かります。この例では、キーワードを単一の属性(業種:「ホテル業界」)に集約しましたが、もちろん単一の属性に集約することは必須ではなく、例えば「接客」「女性が活躍中」といった「ホテル業界」に関連深い複数の属性を足し合わせて集計することで、「ホテル業界」というキーワードに期待されている検索ニーズを測ることもできます。ここで重要なポイントは「キーワードの意味をデータから機械的に算出できる」ことです。これは非常にシンプルな方法ですが、必要に応じてより手の込んだ手法を利用することもできます。
ただし、シンプルな手法を使うことは「機械学習や検索の専門家以外にも説明が簡単にできる」という利点があることを付け加えておきます。
キーワードごとの適合率の算出
さて、非常にシンプルな手法ですが、データを使ってキーワードごとの意図を明らかにすることができました。キーワードの意図が分かると、これを使って改善前の検索結果を定量的に評価することが可能になります。ここで初めて「何か……思ったような検索結果が返ってこない」といった感覚を数値化できます。この明らかになった検索意図を使って改善前のサイトの検索適合率を計算します。
例えば、「ホテル」で検索された検索結果が次のような状態だったとしましょう。ホテルで検索したときの検索結果上位10件の求人のうち、業種が「ホテル業界」に該当するものが5件だった場合です。

この場合、「上位10件適合率は50%」のように定量的に算出できます。
ポイントは、「前述した“キーワードの意図”も“上位適合率”もデータを使って機械的に計算可能にしている」ところです。「機械的に計算可能」ということは「キーワードごとの適合率や、その他の条件ごとの上位適合率を計算し比べることができる」ことを意味します。
検索改善の予想効果
さて、ここまでで検索結果の適合率が算出できるようになりました。次に検索改善の「予想効果」を“仮説立て”によって求めます。予想効果を先に見立てる理由は、「予想効果を見立てるために、仮説を構築しモデルを組み立てることで、仮説単位ごとの振り返りが可能になる」ためです。もう1つは「予想効果を最大化するための改善方法を選択する」ためです。検索改善にはさまざまなアプローチがありますが、予想効果は、限られたリソースをどのアプローチに配分するかを決める際の指標になります。
KGIと適合率の関係を仮説立てる
予想効果を見立てるためには、何を指標にするのか決める必要がありますが、例えば、求人情報サイトで「応募数」がKGI(Key Goal Indicator)だったとしましょう。その場合、検索改善が寄与する効果も「応募数」となります。そして、検索改善によって「応募数」が増えることを示せばいいのです。いろいろな方法がありますが、例えば「検索キーワードごとの適合率」と「応募数」の関係を見てみます。つまり、「検索改善によって適合率がどのくらい上がれば、どのくらいの応募効果が上がるのか」の仮説を立てるということです。
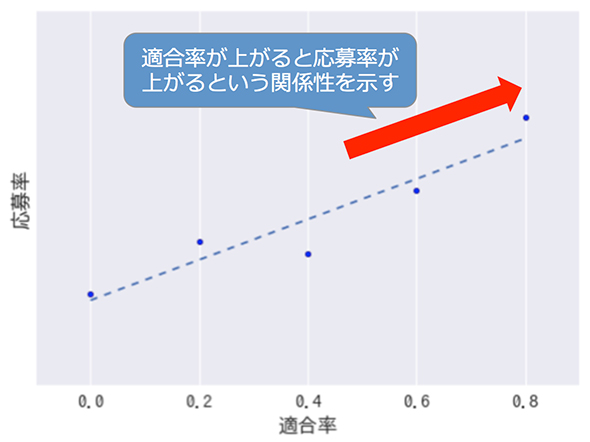 図3 検索キーワードごとの適合率と応募率の関係
図3 検索キーワードごとの適合率と応募率の関係上の例でいうと、「改善前の適合率が50%程度であれば、適合率を80%程度まで上げることで、その水準の応募率に比例した応募率が得られる」という仮説が立てられます。つまり、「この予想効果のコスト対効果」を他のアプローチと比べることで、「適合率を向上させる」という改善アプローチを採ることを方針として決定できるのです。
関連記事
 事例で分かるデータ分析プロジェクトの進め方の基本
事例で分かるデータ分析プロジェクトの進め方の基本
ビジネスのデータ分析業務に12年ほど関わる筆者の経験に基づきデータ分析のプロジェクトがどのようなものかをお話しします。 リクルートの有名サイト事例に見る、シナリオベースABテストの基本的な考え方と改善プロセス、チーム体制
リクルートの有名サイト事例に見る、シナリオベースABテストの基本的な考え方と改善プロセス、チーム体制
ABテストを利用したサイト改善の限界にぶつかっている人たちに向けて、リクルートグループ内で実践している改善ノウハウをお伝えする連載。初回はユーザー体験(シナリオ)の良しあしの検証と、改善するABテストの基本的な考え方、サービス改善PDCAプロセス、チーム体制について。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。