別の行を参照しているのにロック待ちが発生した(処理遅延):SQL Serverトラブルシューティング(69)(1/2 ページ)
本連載では、「Microsoft SQL Server(以下、SQL Server)」で発生するトラブルについて、「なぜ起こったか」の理由とともに具体的な対処方法を紹介していきます。今回は「別の行を参照しているのにロック待ちが発生した」場合の解決方法を解説します。
本連載では、「Microsoft SQL Server(以下、SQL Server)」で発生するトラブルについて、「なぜ起こったか」の理由とともに具体的な対処方法を紹介していきます。
トラブル 58(カテゴリー:処理遅延):別の行を参照しているのにロック待ちが発生した
「Windows Server 2012 R2」上に「SQL Server 2016 RTM」をインストールした環境を想定して解説します(本トラブルシューティングの対応バージョン:SQL Server 全バージョン)。
トラブルの実例:トラブル39で発生したロック待ちを防ぐため、クエリで操作する範囲を最小限に修正して処理を実行していた。ある日、別部署の製品データを大規模に修正するという話が聞こえてきたが、自分が操作する製品とは別データであるため特に気にしていなかった。しかし修正時期に自分の処理を実行すると処理遅延が発生してしまった。dm_exec_requestsを実行して状況を確認してみると、statusはsuspendedになっており、wait_typeはLCK_M_ISと表示された(図1)。
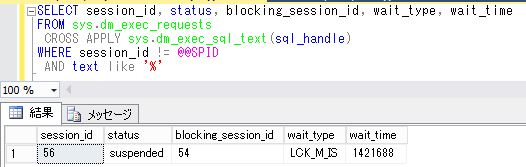 図1 LCK_M_ISの待ちが発生
図1 LCK_M_ISの待ちが発生トラブルの原因を探る
wait_typeではLCKから始まるLCK_M_ISと表示されていたため、動的管理ビューのdm_tran_locksを使用してロックの状況を確認してみます(図2)。

通常であればデータの更新や挿入では、粒度の小さいロックリソースに対して排他ロック(X)を要求し、OBJECTなどの粒度の大きいロックリソースに対しては、粒度の小さいロックリソースの排他ロックを保有していることを示すインテント排他ロック(IX)が要求されます。
例えば、table1の製品Aを挿入する場合、製品Aの行に対して排他ロックを要求し、table1のOBJECTにはインテント排他ロックが要求されます。その状態であれば、別のセッションがtable1の製品Bを検索したとしても、製品Bの行に対して共有ロック(S)とtable1に対してインテント共有ロック(IS)が要求されるためロック待ちは発生しません。
なぜ今回はtable1のOBJECTに対して排他ロック(X)が保有されていたのでしょうか。パフォーマンスログから気になるカウンタを探していると、Access MethodsのTable Lock Escalations/secというカウンタ(*1)が上昇していることが確認できました(図3)。

Table Lock Escalations/sec はロックのエスカレーション(*2)回数を示しています。通常は同時実行性を高めるため、最小限のロックを確保して処理を実行します。しかし操作対象のデータが多く、ロックの確保によりオーバーヘッドが大きくなりそうな場合は、ロックの粒度を大きくしてオーバーヘッドを減少させることがあります。この動作は一般的にロックのエスカレーションと呼ばれます。ユーザーが意図しない範囲までロックが確保されてしまうため、ロック待ちが発生し同時実効性が低下してしまうこともあります。
関連記事
 「SQL Server 2016」に搭載される新たなセキュリティ対策を追う
「SQL Server 2016」に搭載される新たなセキュリティ対策を追う
パブリックプレビューが公開されているマイクロソフトのRDB次期版「SQL Server 2016」。特徴の1つとするセキュリティ対策機能のポイントと目指すところをキーパーソンに聞いた。 そもそも、リレーショナルデータベースとは何か?
そもそも、リレーショナルデータベースとは何か?
データベースを基礎から勉強し理解を深めていくことは簡単なことではありません。本連載では、データベースに対するハードルを少しでも低くするために、初心者の方に必要なデータベースの基本から、障害対策やチューニングといった実践に即した内容までを幅広く解説していきます。今回は、データベースの役割と、それを管理するソフトウェアであるDBMSの基本機能について解説します。【更新】 データの登録を行うINSERT文
データの登録を行うINSERT文
 複数の条件を指定してSELECT文を実行する
複数の条件を指定してSELECT文を実行する
前回は、SELECT文の初歩の初歩を解説しました。今回は、複数の条件を指定して、目的のデータを取り出す方法を解説します(編集部) Oracle運用の基本「ログ」を理解しよう
Oracle運用の基本「ログ」を理解しよう
本連載では、Oracle Database運用の鍵となるトラブル対処法について紹介していきます。第1回、第2回では情報収集の要となるログについて見ていきます。ログの出力情報は10gと11gとでは大きく異なる点がありますので、それぞれについても確認しておきましょう。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。