「スマートスピーカー」の中にある「人工知能」は何をしているのか、作り方から理解する:ものになるモノ、ならないモノ(77)
世界の名だたるプラットフォーマーが開発に力を入れる「スマートスピーカー」。どのような手順でどんな処理が行われているのかは完全にブラックボックスだ。「スマートスピーカーを理解するには、自作するのが早道」と提唱する開発者に話を聞いた。
Amazon、Google、LINE、Apple(日本未上陸)と世界の名だたるプラットフォーマーが開発に力を入れる「スマートスピーカー」。筆者の中では、iPhoneに搭載されたSiriに次いで「人工知能」の存在を身近に感じる製品であると捉えている。ただ「オーケー、グーグル」や「アレクサ」と問い掛けたその先ではどのような手順でどんな処理が行われているのかは完全にブラックボックスだ。そのような折、「スマートスピーカーを理解するには、自作するのが早道」と提唱する開発者に出会った。筆者自ら自作することはなくても、話を聞けば、ブラックボックスの一隅をのぞき見ることができるかもしれないと話を聞いた。
 栂井良太氏
栂井良太氏この春、静岡大学を卒業し都内のゲーム開発企業に就職した栂井良太氏は、スマートスピーカーを自作した。筆者のような技術素人が「自作」と聞くと、ハードとソフトを自ら開発したのかと驚くばかりだが、ご本人は自作に至ったきっかけを「GoogleHomeと赤外線リモコンを組み合わせて家電をコントロールしたかったのだが、手頃な赤外線リモコンの種類も少なく、せっかく見つけても軒並み売り切れだった。ならば赤外線に対応したスマートスピーカーを自分で作ってしまえと考えた」と飄々(ひょうひょう)としている。
栂井氏は、スマートスピーカーを自作することのメリットとして次の3つのポイントを力説する。
- 【1】カスタマイズの自由度
スマートスピーカー自体に赤外線リモコンを搭載するといったオリジナリティーを追求できる。現在、メーカー製品で本体に赤外線を搭載している製品は少ない。手軽に購入できるのは、Clova WAVEだけだ。これだけでもGoogle HomeやAmazon Echoへのアドバンテージとなる。
- 【2】好きなホットワードを設定できる
ホットワードとは、「アレクサ」「オーケー、グーグル」など、スタンバイ状態のスマートスピーカーを“起こす”言葉だ。「ウェイクワード」などともいわれる。Amazon Echoの場合は、「Alexa」「Amazon」「Echo」「Computer」の中から選べるが、Google Homeは、「OK, Google」固定で選択肢がない。栂井氏は、スマートスピーカーに「ヘイ、ブラザー」と呼び掛けたかったということで、それを実現した。
- 【3】自作することで理解が深まる
栂井氏は、この部分を特に力説する。大学で対話システムを専攻しただけあり「チャットbotや対話システムにおいて、何が重要で、どのような視点が必要なのかという知見が得られたのが大きかった」という。
まずは、自作スマートスピーカーの概要について聞いた。開発に必要な要素は大きく、ハードウェア部分とソフトウェア部分に分かれる。以下、本人が用意したプレゼン資料の図版を交えポイントを解説しよう。
ハードはシンプルだが、ソフトはさまざまなオープンソースの組み合わせ
スマートスピーカーのほとんどの処理は、クラウド上のサーバで実行されるので、ハードウェア自体はシンプルな作りである。必要なパーツは、小型コンピュータ(今回はRaspberry Pi)、USBマイクロフォン、USBスピーカーの3点だ。実際のスマートスピーカーはより高度なハードウェアを搭載しているが、自作する上ではRaspberry PiのUSBポートにマイクとスピーカーを接続するだけでハードウェアは完成する。

なお、栂井氏は、赤外線送受信の回路も備えたものを作成したのだが、それについては後述する。
ハードウェアができたら、さまざまな処理を実行するためのプログラムを組まなければならない。とはいえ、インディ開発者がゼロからスマートスピーカーのプログラムを構築するのは非現実的な話だ。そこで、栂井氏は、Raspberry Pi上でLinuxを動かし、さまざまなオープンソースソフトウェア(OSS)を組み合わせることでオリジナルなスマートスピーカーを実現した。
次の図は、スマートスピーカーに音声コマンドで指示を行い、サーバ上の処理を経て応答が返ってくるまでのプロセスをソフトウェアの構成要素の視点から段階的に示したものだ。順番に解説していこう。

ホットワード検出
音声認識を行うスマートスピーカーにとって、ホットワードは、極めて重要な要素である。スタンバイ状態のスマートスピーカーは、マイクで常に周囲の音を拾っている。自分が呼ばれたことを認識し、処理を開始するためには、あらかじめ特定の合言葉を決めておく必要がある。
栂井氏は、「Snowboy Hotword Detection」を活用している。このサービスは、独自のホットワードを3回発声し登録するだけで、機械学習によって高精度な検出モデルを作成し、Raspberry Piなどの環境で利用可能にするライブラリだ。個人は無料で利用可能。
音声録音と認識
ホットワードによって処理を開始したスマートスピーカーに対し、ユーザーは音声で指示を出す。その音声を、音声認識を行うサーバに送信するための録音処理が必要になる。音声の録音は、「SoX」を利用する。
SoXは、コマンドラインから音声の録音・加工・変換を行うことのできるOSSだ。下図のようなコマンドを組むことで、「音量が閾値(しきいち)を超えたら録音を開始し、下回ると録音を終了する」といった、「発話による指示で動作を開始し、自動的に発話区間を検出して録音を行う」プログラムを構築できる。これにより、音声のWAVEファイルを生成し、それを音声認識サーバに送信する仕組みだ。


1つ驚いたのは、ユーザーの音声指示をいったん録音し、音声ファイルを生成した上でサーバに送信する点だ。筆者は、リアルタイムストリーミングでサーバに送信されると考えていたが、その理由について、栂井氏は「スマートスピーカーの機種により、ストリーミング送信する場合もあり、その方がレスポンスは優れている。ただし、技術的にハードルが高い部分もある。音声ファイルを生成後に送信する方法なら、通常のHTTP通信が可能なので作り込みもシンプルになる」と明かしてくれた。
音声認識サービスを利用してテキストへ変換
端末内で生成した音声ファイルを音声認識サービスに送信して文字列に変換する。いわゆる「Speech to Text」の工程である。この処理は、「Cognitive Service Bing Speech API」や「Google Cloud Speech API」といった音声認識サービスを利用する。

人工知能で自然言語理解処理を行う
前の段階で、文字列に変換されたデータを受け取ったら、次は、その文字列を人工知能に送信し、ユーザーが何を望んでいるのかを理解するための処理を行う。ここでは、「Language Understanding Intelligent Service(LUIS)」を利用して、後述する意図分類と要素抽出を行う。
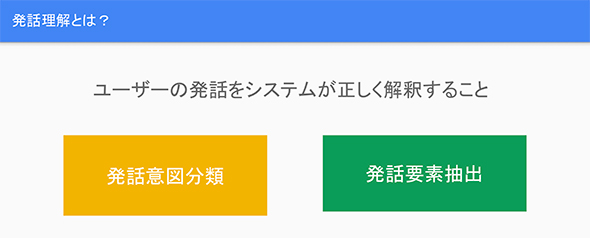
意図分類
コンピュータが人間の発話を理解するためには、単にそこに含まれる単語の意味を理解するだけではなく、全体の文脈を読み解く必要がある。この文脈を読み解くことを「発話意図分類」という。
言うなればユーザーの「目的」が何かを理解するための手順だ。例えば、時刻を知りたい場合、「今、何時?」「時刻を教えて?」など人間の発話はブレるものだ。そのような場合でも「ユーザーは時間を知りたがっている」とコンピュータに理解させる必要がある。
 ユーザーの発話の「目的」が何であるかをスマートスピーカーが理解するための処理
ユーザーの発話の「目的」が何であるかをスマートスピーカーが理解するための処理
要素を抽出する
コンピュータがユーザーの意図(目的)を理解して対話を成り立たせるためには、発話に含まれる単語が何を示しているのか、その意味を理解する必要がある。それを行うためには、文字列の中から対話の根幹を成す「要素」を抽出しなければならない。
例えば、「新宿の明日の降水確率は?」と問い掛けると、その中から「新宿=場所」「明日=時間」「降水確率=天気」という形で要素を抽出し、「新宿」には「場所」、「明日」には「時間」、「降水確率」には「天気」というラベルを付加する。ユーザーの意図に対する答えを見つけるためのキーワードを拾い上げる工程だと考えればよい。

人工知能が意図分類と要素抽出を開発者の意図通りに行うためには、人工知能(この場合は「LUIS」)をトレーニング(機械学習)する必要がある(参考)。基本的には、例文となる文章を入力することで学習させる。前に発話の「ブレ」について説明したが、言い方を変えた例文が多ければそれだけ人工知能が賢くなるという。
対話モデルを用意する
ユーザーからの発話によるリクエストに対し、スマートスピーカーがどのような答えを返すのかを決めるのがこの部分である。ここでは、「Watson Assistant」を使い構築する。
前の段階でサーバから帰ってきた「意図」と「要素」に対する解答を返すために「if分岐」などでルールを記述する。「この部分は機械学習で実行する場合もあるが、まだまだ発展途上なので、ユーザーの意図に対し確実な解答を返すためにはif文を定義する必要がある」(栂井氏)という。
ちなみに、「要素を抽出する」の手順の説明では天気についての対話モデルを例に挙げているが、天気そのものの情報は(天気情報を提供するWebサービスのAPIから取得する」(栂井氏)そうだ。


音声合成
対話モデルから返されてきた「解答」は文字列の情報なので、それを音声にしてやる必要がある。いわゆる「Text to Speech」と呼ばれるAPIをRaspberry Piから叩くことになる。
ここでは2つの選択肢がある。音声合成をサーバ側で行うのか、ローカルで行うのかの2択だ。GoogleやAWSが提供しているサーバ側で処理する音声合成APIを使うと、とても自然な発話合成を実現できるが、音声ファイルを転送するタイムラグが生じる。一方、ローカルで実施すれば転送のタイムラグは気にする必要はなくなる。
栂井氏は「レスポンスを優先したかったので、ローカルで処理できる『OpenJtalk』を利用した。ただし、GoogleやAWSの音声合成と比較すると合成品質は落ちる」という。

サーバ処理とローカル処理における音声合成の品質の差を体感したければ、上記で紹介したOpenJtalkと、サーバ処理の「Amazon Polly」のサンプルデモにそれぞれ同じテキストを入力して聴き比べてみるといいだろう。
GitHubでソースコードを公開中
ここまでが自作スマートスピーカーのソフトウェアを構築するまでの概要だが、栂井氏は、このソフトウェアのコードをGitHubで「Py Assistant」として公開しているので、参考にしてほしい。
GitHubでは、本稿で触れていなかった赤外線送受信の回路やプログラムについても言及している。また、栂井氏が自作した赤外線付きのスマートスピーカーで自室のテレビをオン/オフする動画があるので、それも併せて紹介しておこう。

技術者でもプログラマーでもない筆者だが、普段から利用しているスマートスピーカーがサーバと連携することでどのような処理を行っているのかを垣間見ることができとても楽しい取材だった。
名だたる大企業がグローバルに展開するGoogle HomeやAmazon Echoが自作スマートスピーカーと同質のバックグラウンド処理を実行しているとは思わないが、基本的な考え方は同じであろう。それが理解できたことで、いつもとは違った新鮮な感情をいだきながらスマートスピーカーに向かってホットワードを語り掛ける自分がいる。
著者紹介
山崎潤一郎

音楽制作業を営む傍らIT分野のライターとしても活動。クラシック音楽やワールドミュージックといったジャンルを中心に、多数のアルバム制作に携わり、自身がプロデュースしたアルバムが音楽配信ランキングの上位に入ることもめずらしくない。ITライターとしては、講談社、KADOKAWA、ソフトバンククリエイティブといった大手出版社から多数の著書を上梓している。また、鍵盤楽器アプリ「Super Manetron」「Pocket Organ C3B3」などの開発者であると同時に演奏者でもあり、楽器アプリ奏者としてテレビ出演の経験もある。音楽趣味はプログレ。
関連記事
 Alexaのスキルとは? その開発に必要な基本概念
Alexaのスキルとは? その開発に必要な基本概念
Amazon Echoなどで利用可能なスキルを使うと開発者は独自の機能を追加できる。スキル開発に必要な基礎知識を見ていこう。 DialogflowでGoogleアシスタント対応アプリを作成しよう
DialogflowでGoogleアシスタント対応アプリを作成しよう
Dialogflowと呼ばれるツールを使い簡単なアプリを作成しながら、Googleアシスタントアプリ作成の基礎知識を見ていこう。 スマートスピーカー戦国時代を前に、プライバシー問題よりも注意すべきこととは
スマートスピーカー戦国時代を前に、プライバシー問題よりも注意すべきこととは
@ITは、2018年2月7日、東京で「@ITセキュリティセミナー」を開催した。本稿では、特別講演「お子様も戯れるスマートスピーカー戦国時代突入〜ビジネス利用のセキュリティリスクはいかに?」の内容をお伝えする。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。