第221回 今どきスマホのCPU「A12 Bionic」「Kirin 980」には暗黒面がいっぱい:頭脳放談
Appleの「A12 Bionic」や、Huaweiの「Kirin 980」といった最新のスマートフォン向けCPUはいずれも同じような構成となっている。いずれもぜいたくな作りとなっており、ほとんど使われないシリコン部分も多いようだ。なぜこのような作りになっているのか推察してみた。
今回はスマートフォン(スマホ)向けの最新SoCプロセッサ2機種を取り上げさせていただく。1つはAppleの「A12 Bionic」、もう1つはHuaweiの「Kirin 980」である。
 AppleのiPhone Xsなどに搭載されている「A12 Bionic」のイメージ
AppleのiPhone Xsなどに搭載されている「A12 Bionic」のイメージ HuaweiのHUAWEI Mate 20などに搭載されている「Kirin 980」
HuaweiのHUAWEI Mate 20などに搭載されている「Kirin 980」同時期に登場した同目的のチップなので、その構成が似てくるのは致し方あるまい。どちらも、消費電力効率に優れた小型のものと、性能を要求されるときのみに使われる高性能大型の(当然消費電力が大きい)ものを組み合わせた構成となっている。ただ、A12 Bionicは小型4コアと大型2コアの合計6コアに対し、Kirin 980は小型4コアと大型2コアに加え、両者の中間ともいえる中型のものを2コアの合計8コアとなっている。
そして、前世代と比べて5割ほど性能が向上したGPU、カメラ入力に威力を発揮するISP、そして機械学習、人工知能処理のための膨大な演算を行うための専用エンジン、A12 Bionicの方はNeural Engine、Kirin 980の方はNPU(Neural network Processing Unit)と名前は異なるものの、やりたいことはほとんど一緒(掛け算と足し算)のはずのものを搭載している。
こうして見ると骨格は全く同じだ。細かく言えば、Apple自身がコア開発の主体となっているA12 Bionicに対して、Kirin 980はCPUコアとGPUコアはARM開発ベースのものを使用しているなどと違いはある。
A12 Bionicの目玉の高性能Neural Engineに対して、Kirin 980はNPUを2個搭載(前の世代は1個だった)、けれどAppleのNeural Engineの内部はよく見れば8コア構成などと、細かいことを針小棒大に言い立てて比較することは可能と言えば可能だ。しかし、基本構成は極めてよく似ている、というより遠くから見たらほとんど見分けが付かないくらいである。
今どきのスマホCPUには「モッタイナイ」がいっぱい
A12 Bionicのよくできた紹介ページ(A12 Bionic)を眺めていると、各部の説明の横にチップのイメージ図のようなものが現れて、先ほど説明したようなコアの数などが理解できるようになっていて少しうれしい。
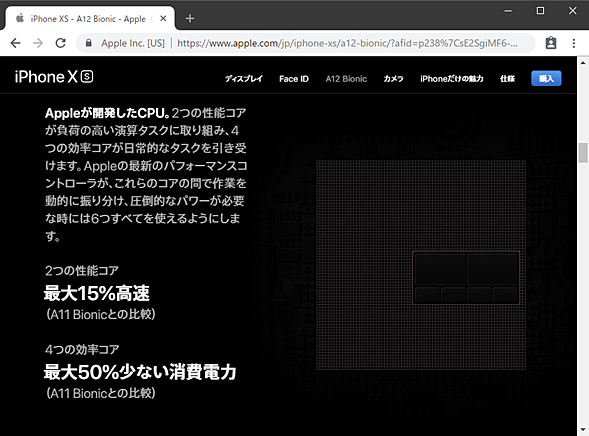 Appleの「A12 Bionic」を紹介するWebページ
Appleの「A12 Bionic」を紹介するWebページAppleの「A12 Bionic」を紹介するWebページには、各部の説明とともにチップのイメージ図が現れるので非常に分かりやすくなっている。
イメージ図なので、実際のチップ上の面積そのままではないと思われるが、大きいコアは大きく、小さいコアは小さく描かれているので、実際のチップの雰囲気を醸し出している。これを見て思うのが、「これらのコアたちが全て忙しく働く局面などというものは、あるのだろうか?」という疑問である。お察しの通り、それに対する答えは、それは「極めてまれ」か、もしかすると「ないのではないか」というものだ。
だからといって、それらのコアのどれかが不要だなどと言う気はさらさらない。逆に、処理すべき仕事に応じて特化したコアがそれぞれに存在することで、スマホに要求される機能のバランスというものが辛うじて成立しているように思えるのだ。ただ、「シリコン=トランジスタ」の使い方としては、誠にもったいないことをしないとイケない時代になってしまった。特に昔を知る年寄りにとっては。
はるかな昔、新人としてCPUの設計を始めたころ、最初に習うのはお金(コスト)はシリコンの面積の関数という「絶対原理」であった。時代や手段に応じて関数パラメータは変わっても、これは「真理」に近い領域でいまだに変わらない。そこでシリコンの面積をケチって、いかにコストを安くするかということを教わるわけである。
チップ上、トランジスタ領域が全てではないが、単純に言えば1つ1つのトランジスタの2次元的大きさに数を掛ければ面積となる。ともかく少ないトランジスタ数で所望の機能を実現する、ということが望まれていた。
筆者が初期に扱ったあるCPUは、ALU(算術論理演算ユニット)が大活躍していた。その名の通り、算術命令や論理演算命令などのデータを処理するときに、ALUは計算の実体を担う。しかし、そのCPUでは、メモリから命令を取り出すためのプログラムカウンターの更新やら、メモリアドレスの計算、それどころか、本来CPUとは無関係なはずのタイマーのカウントアップに至るまで、1つしかないALUが使い回されていた。
ともかく数少ないトランジスタを有効活用、「遊び時間なし」で使い切るのがよしとされた。しかし集積度が上がり、トランジスタ数がもう少し使えるようになるとこれが変わっていく。1つの回路にいろいろ兼用させていたのでは性能が上がらないからだ。それぞれの機能を分離して同時にいろいろできるようにしていく。
無関係なタイマーなどは真っ先に独立した回路にお引き取り願う。次に、メモリからフェッチするときのポインタと、プログラム中の制御で使われるプログラムカウンタは独立したハードウェアにするという具合に、どんどん機能分化が進んだ。
当然、1つの装置であれこれ兼用していた頃より急速に性能は向上していく。同時にクロック速度もどんどん速くなり、半導体製造プロセスの進化とともに性能はうなぎ登りに上がっていったわけだ。けれどそんな「黄金」時代も長くは続かない。電流にせよ、クロック速度にせよ、いろいろ限界に直面してくるわけだ。
シリコン上の暗黒面には意味がある
何年だか前に「ダークシリコン」という言葉がはやったことがあった。熱的、消費電力的な制約を考えると、巨大なシリコンに多数のトランジスタを集積しても、フルスピードで動かせるのは一部の回路になってしまい、残りの回路は「お休み」にしておくしかない、という問題だ。
働いていない「ダーク」な領域が広いシリコンの大部分を覆い尽くしているイメージである。これを無視して昔のように全てのトランジスタを最高速で動かすなどすれば、熱暴走程度で済めばよし、下手をするとチップが溶けかねない。最近でこそ、ダークシリコンと叫んでいる人はあまり聞かないが、問題が解決したわけではない。問題はずっと頭の上に重くのしかかかっているのだ。
「そこを何とか」性能と消費電力の折り合いをつける、というのが最近の設計の主題だと言ってもよい。バランスこそ命である。ことにスマホともなると、熱的な制約よりも、限られた容量の中での電池の持ちという、よりキツイ制約も加わる。昔もコストは問題だったから手放しで性能を追求できたわけでもないが、今はそれ以外の制約もキツくなっているように思える。そういう制約下で、似たような問題を解こうとすれば、結局、似たり寄ったりの答えになってしまうのだろうと思う。
単位時間当たりに小さな電力しか使わず長時間かけて処理しても、単位時間当たりに大きな電力を使って短時間で処理しても、使う電力量は単位時間当たり電力と時間の掛け算だから、小さな電力でも時間がかかりすぎれば所要量は上回るかもしれない。
それに、ある処理に特化した回路は、そうでないものに比べ無駄な動作がない分、多くのケースで効率的なことが多い。また、たとえ同じ電力だとしても、ユーザーの使い心地という点では、早く処理が終わる方がよいに決まっている。
それゆえ重要と思われる用途であれば、特定の機能ごとに特化したコアを使い分けるのはリーズナブルである。たとえ、一瞬しか動作せず、ほとんどの時間は眠っていてダークだったとしてもだ。かくして目標コストの面積以内であれば、盛り込めるだけいろいろ機能を盛り込み、まぁ場合によってはほとんど使われなかったとしても「OK」といった割り切りにならざるを得ない。
とてももったいないような気もするし、苦渋の選択のような気もする。まぁ、「入るものは入れておけば」程度の軽い気持ちでよいのかもしれない。いくら酷使しようが、遊ばせておこうが、トランジスタが文句を垂れることはないのだから。
筆者紹介
Massa POP Izumida
日本では数少ないx86プロセッサのアーキテクト。某米国半導体メーカーで8bitと16bitの、日本のベンチャー企業でx86互換プロセッサの設計に従事する。その後、出版社の半導体事業部などを経て、現在は某半導体メーカーでヘテロジニアス マルチコアプロセッサを中心とした開発を行っている。
更新履歴
【2018/11/26】当初、Kirin 980のCPU構成を、4コアが通常使用の消費電力効率に優れた小型のもの、残り2コアが性能を要求されるときのみに使われる高性能大型のものとしていましたが、4コアが小型、2コアが中型、2コアが大型のものでした。お詫して訂正いたします。
【2018/10/23】初版公開。
「頭脳放談」
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。