Lesson 6丂僨乕僞宆乮儕僗僩乛僞僾儖乛帿彂乛奺庬僆僽僕僃僋僩乯 乗 Python婎慴暥朄擖栧丗婡夿妛廗仌僨傿乕僾儔乕僯儞僌擖栧乮Python曇乯
Python尵岅偺暥朄傪丄僐乕僪傪彂偔棳傟偵増偭偰愢柧偟偰偄偔楢嵹丅慜夞偲崱夞偼丄抣傗僨乕僞偺宆傪愢柧丅崱夞偼偦偺屻曇偲偟偰丄list宆乛tuple宆乛dict宆丄偦傟傜埲奜偺僆僽僕僃僋僩偺宆傪庢傝忋偘傞丅
偙偺婰帠偼夛堳尷掕偱偡丅夛堳搊榐乮柍椏乯偡傞偲慡偰偛棗偄偨偩偗傑偡丅
偛拲堄丗杮婰帠偼丄仐IT乛Deep Insider曇廤晹乮僨僕僞儖傾僪僶儞僥乕僕幮乯偑乽deepinsider.jp乿偲偄偆僒僀僩偐傜丄撪梕傪夵曄偡傞偙偲側偔丄偦偺傑傑乽仐IT乿傊偲揮嵹偟偨傕偺偱偡丅偙偺偨傔梡帤梡岅偺摑堦儖乕儖側偳偼仐IT偺偦傟偲偼堦抳偟傑偣傫丅偁傜偐偠傔偛椆彸偔偩偝偄丅
丂慜夞偼丄婎杮揑側僨乕僞偺宆偱偁傞乽bool宆乮僽乕儖宆乯乿乽int宆乛float宆乮悢抣宆乯乿乽str宆乮暥帤楍宆乯乿偵偮偄偰夝愢偟偨丅崱夞偼丄偦偺屻曇偲偟偰乽list宆乮儕僗僩宆乯乿乽tuple宆乮僞僾儖宆乯乿乽dict宆乮帿彂宆乯乿丄偦傟傜埲奜偺儌僕儏乕儖傗壗傜偐偺僆僽僕僃僋僩偺宆偵偮偄偰愢柧偡傞丅仸媟拲傗恾丄僐乕僪儕僗僩偺斣崋偼慜夞偐傜偺懕偒斣崋偲偟偰偄傞丅
丂杮楢嵹偼丄幚嵺偵儔僀僽儔儕乽TensorFlow乿偱僨傿乕僾儔乕僯儞僌偺僐乕僪傪彂偔棳傟偵増偭偰丄嬶懱揑偵偼Lesson 1偱宖嵹偟偨恾1-a乛b乛c乛d偺僒儞僾儖僐乕僪偺弴偱丄婎慴暥朄偑妛傫偱偄偗傞傛偆偵栚師傪峔惉偟偰偄傞丅崱夞偼丄恾1-a乛b乛d撪偺堦晹僐乕僪傪庢傝忋偘傞丅



丂崱夞丄杮峞偱愢柧偡傞偺偼丄恾1-a乛b乛d亂嵞宖亃偵偍偗傞愒榞撪偺僐乕僪偺傒偲側傞丅惵榞撪偺僐乕僪偼慜夞愢柧偟偨撪梕偲側傞丅
丂側偍丄杮峞偱帵偡僒儞僾儖僐乕僪偺幚峴娐嫬偵偮偄偰偼丄Lesson 1傪堦撉偟偰傎偟偄丅
丂Lesson 1偱傕帵偟偨傛偆偵丄杮楢嵹偺偡傋偰偺僒儞僾儖僐乕僪偼丄壓婰偺儕儞僋愭偱幚峴傕偟偔偼嶲徠偱偒傞丅


Python尵岅偺婎慴暥朄
丂偦傟偱偼丄list宆乛tuple宆乛dict宆傪弴偵愢柧偟偰偄偙偆丅側偍崱夞偼丄愢柧偡傋偒暥朄梫慺偑懡偔丄偙傟傑偱傛傝傕彮偟挿傔偺婰帠偲側偭偰偄傞丅
僨乕僞偺宆乮僐儗僋僔儑儞曇乯
丂曄悢偵偼丄慜夞Lesson 4偱尒偨傛偆側乽儌僕儏乕儖乿偩偗偱側偔丄乽悢抣乿乽暥復乿乽堦棗僨乕僞乿側偳丄偝傑偞傑側抣乛僨乕僞偑戙擖偱偒傞丅椺偊偽儕僗僩8偼丄慜宖偺恾1-b乛d撪偺僒儞僾儖僐乕僪偺拞偵偁傞乽曄悢偵懳偟偰壗偐傪戙擖偟偰偄傞峴乿乮亖朻摢偱帵偟偨亂嵞宖亃夋憸偺愒榞偺撪梕乯偺拞偐傜丄list宆乛tuple宆乛dict宆偵娭偡傞傕偺偩偗傪敳偒弌偟偰暲傋偨傕偺偩丅
#import tensorflow as tf
#mnist = tf.keras.datasets.mnist
# 埲壓偺僐乕僪傪摦偐偡偨傔偵偼丄忋婰2峴傪帠慜偵幚峴偟偰偍偔昁梫偑偁傞
#---------------------------------------------------------------------
# 曄悢傊偺乽僞僾儖抣乿偺戙擖
(x_train, y_train),(x_test, y_test) = mnist.load_data()
# 乽僞僾儖乿偺峔暥傪墳梡偟偰丄暋悢偺曄悢偵傑偲傔偰戙擖
x_train, x_test = x_train / 255.0, x_test / 255.0
# 埲壓偼乽僞僾儖乿偺峔暥傪墳梡偡傞摨偠曽朄側偺偱愢柧傪徣棯
# predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
丂偙偺椺偱偼丄庡偵僞僾儖抣偺僨乕僞乛抣偑曄悢偵戙擖偝傟偰偄傞丅
丂慜夞愢柧偟偨bool宆乛int宆乛float宆乛str宆偼丄扨堦偺僨乕僞傪昞尰偡傞偨傔偺宆偩偭偨丅堦曽丄崱夞愢柧偡傞壓婰偺3偮偺宆偼丄暋悢偺僨乕僞傪傑偲傔偰埖偆偨傔偺慻傒崬傒宆乮僐儗僋僔儑儞傕偟偔偼僐儞僥僫乕偲屇偽傟傞乯偱偁傞乮仸慻傒崬傒宆偼偙傟偱偡傋偰偱偼側偔丄崱夞徯夘偡傞暘偺傒傪婰嵹偟偰偄傞乯丅
- list宆丗 [0.0, 1.2, -1.2]偺傛偆偵丄暋悢偺抣傪傑偲傔偨儕僗僩乮亖堦棗僨乕僞乯抣丅儕僗僩宆
- tuple宆丗 ('Yamada','Taro')偺傛偆偵丄暋悢偺抣傪傑偲傔偨僞僾儖乮亖慻僨乕僞乯抣丅僞僾儖宆
- dict宆丗 {'a': 2.5, 'b': 1.4 }偺傛偆偵丄暋悢偺乽僉乕乮key乯丗抣乮value乯乿偺僙僢僩抣傪傑偲傔偨僨傿僋僔儑僫儕抣丅帿彂宆
丂偦傟偧傟嬶懱揑側僐乕僪偱帵偟側偑傜愢柧偟偰偄偙偆丅偪側傒偵set宆乮廤崌宆乯偲偄偆僐儗僋僔儑儞傕偁傞偑丄偙傟偼婡夿妛廗偱偼斾妑揑弌斣偑彮側偄偺偱丄杮峞偱偼愢柧傪妱垽偡傞丅
list宆乮儕僗僩宆乯
丂list宆偼慜宖偺儕僗僩8偵偼娷傑傟偰偄側偐偭偨偺偱丄偙偙偱偼壖偺僒儞僾儖僐乕僪傪採帵偡傞乮儕僗僩8-1乯丅
abc_list = ['a', 'b', 'c', 'd', 'e']
abc_list # ['a', 'b', 'c', 'd', 'e']偲弌椡偝傟傞
丂曄悢傊偺乽儕僗僩抣乿偺戙擖傪僀儊乕僕壔偡傞偲丄恾10-1偺傛偆偵側傞乮仸慜夞偺奊偲戝嵎側偄偑丄抣偺晹暘偺昞尰偑彮偟曄傢偭偰偄傞乯丅偙偺傛偆偵儕僗僩偼丄暋悢偺抣偑1楍偵弴偵暲傫偱傂偲傑偲傔偵側偭偨傕偺傪僀儊乕僕偡傞偲傛偄丅

丂偙偺僐乕僪椺偱偼丄曄悢abc_list偵丄乽'a'丄'b'丄'c'丄'd'丄'e'乿偲偄偆5屄偺暥帤楍傪傑偲傔偨儕僗僩抣傪愝掕乮亖戙擖乯偟偰偄傞丅
丂偙偺傛偆偵儕僗僩偼丄妏妵屖[乣]偱嫴傫偱婰弎偡傞丅妵屖偺拞偼僇儞儅','偱嬫愗傞乮仸妵屖傗僇儞儅偺娫偵偁傞敿妏僗儁乕僗偼偁偭偰傕側偔偰傕傛偄偑丄堦斒揑偵偼僇儞儅偺屻偵敿妏僗儁乕僗傪1偮擖傟傞乯丅偙偙偱偼'a'側偳偺暥帤楍抣偵偟偰偄傞偑丄屄乆偺抣乮亖僆僽僕僃僋僩乯偺宆偼壗偱傕傛偄丅
丂婡夿妛廗乛僨傿乕僾儔乕僯儞僌偺僨乕僞偼丄悢妛寁嶼偺偨傔偵傕傑偲傔偰埖偭偰娗棟偡傞昁梫偑偁傞偺偱丄偙偺儕僗僩宆乮偁傞偄偼儕僗僩偲摨條偵埖偊傞儔僀僽儔儕乽NumPy乿偺偺攝楍側偳乯傪懡梡偡傞丅傛偭偰儕僗僩宆偵偮偄偰偼丄摿偵傛偔棟夝偟偰偍偔昁梫偑偁傞丅傛傝怺偟偄撪梕傪丄亀婡夿妛廗仌僨傿乕僾儔乕僯儞僌擖栧乮僨乕僞峔憿曇乯亁偱愢柧偟偰偄傞偺偱丄暪偣偰嶲徠偟偰傎偟偄丅
仦 僀儞僨僋僔儞僌乮梫慺僨乕僞偺庢摼乯
丂慜夞愢柧偟偨bool宆乛int宆乛float宆乛str宆偼扨堦偺僨乕僞偩偭偨偺偱丄曄悢偐傜僨乕僞傪庢摼偡傞応崌偼丄扨偵曄悢柤傪彂偔偩偗偩偭偨丅偦傟傜偲堘偭偰丄僐儗僋僔儑儞偺応崌偼丄暋悢偺僨乕僞偑傑偲傑偭偨僐儗僋僔儑儞偺拞偐傜丄扨堦偺僨乕僞傪庢傝弌偝側偗傟偽側傜側偄応柺偑偁傞丅偦偺庢傝弌偟曽朄乮僀儞僨僋僔儞僌偲屇傇乯偵偮偄偰娙扨偵愢柧偟偰偍偙偆丅
丂list宆偺応崌偼丄曄悢柤偺屻偵懕偗偨妏妵屖[乣]偺拞偵僀儞僨僢僋僗斣崋乮屻弎乯傪婰嵹偟偰丄庢傝弌偡偙偲偵側傞丅僀儞僨僢僋僗斣崋乮index乯偲偼丄0偐傜僗僞乕僩偟偰丄1丄2丄3乧乧偲暲傇惍悢抣偺偙偲偱丄乽儕僗僩偺梫慺悢暘乿乮偮傑傝0乣乽儕僗僩梫慺悢 - 1乿乯偺惍悢抣偑巊偊傞丅椺偊偽愭傎偳偺曄悢abc_list偱偁傟偽丄乽'a'偺僀儞僨僢僋僗斣崋亖0偐傜僗僞乕僩偟偰丄'b'偺僀儞僨僢僋僗斣崋亖1丄'c'偺僀儞僨僢僋僗斣崋亖2丄'd'偺僀儞僨僢僋僗斣崋亖3丄'e'偺僀儞僨僢僋僗斣崋亖4乿偲側傞乮恾10-2乯丅
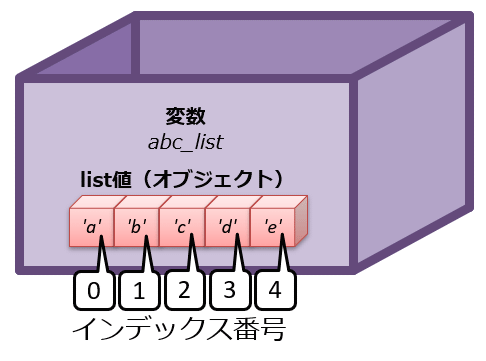 恾10-2丂儕僗僩偺僀儞僨僢僋僗斣崋
恾10-2丂儕僗僩偺僀儞僨僢僋僗斣崋 丂椺傪嫇偘傞偲丄曄悢abc_list偵戙擖偝傟偰偄傞list宆僆僽僕僃僋僩偐傜'b'偲偄偆梫慺僨乕僞傪庢傝弌偟偨偄偺偱偁傟偽丄儕僗僩8-2偺傛偆偵丄曄悢柤abc_list偺屻偵懕偗偨妏妵屖[乣]偺拞偵僀儞僨僢僋僗斣崋偺1傪婰嵹偡傟偽傛偄丅
abc_list[1]
# 'b'偲弌椡偝傟傞
丂偪側傒偵丄慜宖偺儕僗僩8偵predictions_array[i]傗true_label[i]偲偄偆僐乕僪傕娷傑傟偰偄偨偑丄偙傟傜偼尩枾偵偼儕僗僩偱偼側偔丄儔僀僽儔儕乽NumPy乿偺懡師尦攝楍乮ndarray宆偺僆僽僕僃僋僩乯偱偁傞丅ndarray偼丄儕僗僩偲摨偠傛偆偵僀儞僨僋僔儞僌偡傞偙偲偑偱偒傞丅偮傑傝predictions_array[i]傗true_label[i]偲偄偆僐乕僪傕儕僗僩8-2偲摨偠偙偲傪峴偭偰偄傞偲偄偆傢偗偩丅
丂惍悢抣偱偼側偔曄悢柤偺i偑婰嵹偝傟偰偄傞偑丄偙偺i偵偼0傗1側偳偺惍悢抣偑戙擖偝傟偰偄傞偺偩丅僀儞僨僢僋僗斣崋傪昞偡曄悢偺柤慜偼丄乽index乿偺摢暥帤偐傜i偲柦柤偡傞偙偲偑姷椺偲側偭偰偄傞偺偱妎偊偰偍偄偰傎偟偄丅
丂僀儞僨僋僔儞僌偼戙擖偵傕墳梡偱偒傞丅椺偊偽儕僗僩8-3偺傛偆偵丄abc_list[1]偲偄偆僐乕僪偱庢摼偟偨屄暿梫慺偵懳偟偰丄悢抣傗暥帤楍側偳偺僆僽僕僃僋僩傪戙擖偡傞偙偲偱丄偦偺梫慺偺傒傪曄峏偡傞偙偲傕偱偒傞丅
abc_list[1] = 'x'
abc_list # ['a', 'x', 'c', 'd', 'e']偲弌椡偝傟傞
仦 僗儔僀僔儞僌乮斖埻僨乕僞偺庢摼乯
丂扨堦偺僨乕僞偩偗偱偼側偔丄斖埻巜掕偱暋悢偺僨乕僞傪庢摼乮亖僗儔僀僗乯偡傞曽朄乮僗儔僀僔儞僌偲屇傇乯偵偮偄偰傕娙扨偵愢柧偟偰偍偙偆丅椺偊偽丄僀儞僨僢僋僗斣崋2乣3偺2偮乮亖list宆僆僽僕僃僋僩偵側傞乯傪庢摼偟偨偄応崌偼丄儕僗僩8-4偺傛偆偵婰弎偡傟偽傛偄丅
abc_list[2:4]
# ['c', 'd']偲弌椡偝傟傞
丂僐乕僪椺偐傜悇應偱偒傞偲巚偆偑丄妏妵屖[乣]偺拞偵婰嵹偡傞斖埻巜掕偼丄
亙奐巒僀儞僨僢僋僗斣崋亜:亙廔椆僀儞僨僢僋僗斣崋亜
偲偄偆巇條偵側偭偰偄傞丅乽偁傟丄2乣3偺偼偢偑丄2:4偲偄偆婰弎偵側偭偰偄傞乿偲偄偆揰偵婥晅偄偨恖偼塻偄丅亙廔椆僀儞僨僢僋僗斣崋亜偺梫慺帺懱偼丄拪弌斖埻偵娷傑傟側偄偙偲偵拲堄偑昁梫偩丅偝傜偵埲壓偺墳梡僥僋僯僢僋傕偁傞丅
丂墳梡僥僋僯僢僋1丗 亙奐巒僀儞僨僢僋僗斣崋亜傪徣棯偟偰丄椺偊偽abc_list[:4]偲婰弎偡傞偲丄乽愭摢偐傜僀儞僨僢僋僗3傑偱傪庢摼乿偲偄偆堄枴偵側傝丄['a', 'x', 'c', 'd']偑庢摼偱偒傞乮儕僗僩8-4-1乯丅
abc_list[:4] # 愭摢偐傜僀儞僨僢僋僗3傑偱傪庢摼
# ['a', 'x', 'c', 'd']偲弌椡偝傟傞
丂墳梡僥僋僯僢僋2丗 亙廔椆僀儞僨僢僋僗斣崋亜傪徣棯偟偰丄椺偊偽abc_list[2:]偲婰弎偡傞偲丄乽僀儞僨僢僋僗2偐傜枛旜傑偱傪庢摼乿偲偄偆堄枴偵側傝丄['c', 'd', 'e']偑庢摼偱偒傞乮儕僗僩8-4-2乯丅
abc_list[2:] # 僀儞僨僢僋僗2偐傜枛旜傑偱傪庢摼+
# ['c', 'd', 'e']偲弌椡偝傟傞
丂墳梡僥僋僯僢僋3丗 亙奐巒僀儞僨僢僋僗斣崋亜:亙廔椆僀儞僨僢僋僗斣崋亜丗亙壗屄愭偛偲亜偲偄偆峔暥傪巊偭偰丄椺偊偽abc_list[::2]偲婰嵹偡傞偲丄乽愭摢偐傜枛旜傑偱2屄愭偛偲偵庢摼乿偲偄偆堄枴偵側傝丄['a', 'c', 'e']偑庢摼偱偒傞乮儕僗僩8-4-3乯丅亙壗屄愭偛偲亜偵2傪巜掕偟偰偍傝丄'a'偺1屄愭偑'x'偱丄2屄愭偑'c'側偺偱丄師偺庢摼抣偼'c'偲側傞丅偦偺師偼'd'傪旘偽偟偰'e'偲側傞偨傔丄偙偺傛偆側儕僗僩抣偑庢摼偱偒傞偲偄偆傢偗偩丅
abc_list[::2] # 愭摢偐傜枛旜傑偱2屄愭偛偲偵庢摼
# ['a', 'c', 'e']偲弌椡偝傟傞
丂list宆偱偁傞儕僗僩偵娭偟偰偼丄儕僗僩偺憖嶌乮梫慺偺捛壛傗嶍彍丄楢寢丄僜乕僩丄僐僺乕側偳乯宯偺娭悢偑偁傝丄摿掕偺応柺偱偼傛偔巊偆偺偱偡傋偰徯夘偟偨偄偲偙傠偩偑丄杮楢嵹偼乽TensorFlow僠儏乕僩儕傾儖偺撉傒彂偒乿偵僼僅乕僇僗傪摉偰偰偍傝丄偦傟傜偵偮偄偰偼偁傑傝弌斣偑側偄傛偆偩偭偨偺偱妱垽偡傞丅
tuple宆乮僞僾儖宆乯
丂師偵tuple宆偼丄慜宖偺儕僗僩8偵娷傑傟偰偄偨偑彮偟暋嶨側偺偱丄傑偢偼僔儞僾儖側壖偺僒儞僾儖僐乕僪偱愢柧偟傛偆乮儕僗僩8-5丄恾10-3乯丅
# 僞僾儖抣偼1偮偺曄悢偵戙擖偱偒傞
tuple_data = ('Taro', 'Yamada')
# 娵妵屖傪徣棯偟偰乽tuple_data = 'Taro', 'Yamada'乿偲婰弎偟偰傕摨偠堄枴
tuple_data # ('Taro', 'Yamada')偲弌椡偝傟傞

丂儕僗僩8-5偱偼丄曄悢tuple_data偵丄乽'Taro'乿偲乽'Yamada'乿偲偄偆2偮偺抣傪乽1偮偺抣乿偵僷僢僋偟偨乮亖傑偲傔偨乯僞僾儖抣傪戙擖偟偰偄傞丅
丂偙偺傛偆偵僞僾儖偼丄娵妵屖(乣)偱嫴傫偱婰弎偡傞丅妵屖偺拞偼僇儞儅','偱嬫愗傞丅屄乆偺抣偺宆偼壗偱傕傛偄丅
丂僞僾儖偺嶌惉曽朄偼丄婎杮揑偵偼儕僗僩偲摨偠偱偁傞丅傕偪傠傫堘偆晹暘傕偁傞丅摿偵儕僗僩偲堘偆偺偼丄娵妵屖(乣)偼乮尒傗偡偝側偳昁梫偵墳偠偰乯徣棯偱偒傞偲偄偆揰偩丅嬶懱揑偵偼('Taro', 'Yamada')偺戙傢傝偵'Taro', 'Yamada'偲婰弎偟偰傕傛偄乮屻弎偺儕僗僩8-7偱嵞搙愢柧偡傞乯丅
仦 儕僗僩偲僞僾儖偺巊偄暘偗巜恓
丂儕僗僩偼丄僨乕僞僐儗僋僔儑儞傊偺怴偨側僨乕僞偺捛壛傗嶍彍偑偱偒傞乮偙偺惈幙傪儈儏乕僞僽儖偲屇傇乯偺偱丄戝検偺僨乕僞傪庢傝埖偆偺偵偼曋棙偱偁傞丅傂偲尵偱偄偆偲乽僨乕僞偺儕僗僩壔乿乮亖堦棗僨乕僞偵偡傞偙偲乯偑摼堄偱偁傞丅
丂偦傟偵懳偟偰僞僾儖偼丄摦揑偵僨乕僞僐儗僋僔儑儞傪捛壛丒嶍彍偟偰曄峏偡傞曽朄偼採嫙偝傟偰偍傜偢乮偙偺惈幙傪僀儈儏乕僞僽儖偲屇傇乯丄2乣10屄側偳斾妑揑彮側偄屄悢暘偺抣傪乽1偮偺抣乿偺傛偆偵僷僢僋偵偟偰庢傝埖偄偨偄嵺偵曋棙偱偁傞丅傂偲尵偱偄偆偲乽暋悢偺抣偺僌儖乕僾壔乿偑摼堄偲偄偆偙偲偩丅
丂偙傟傪暦偄偰傕乽僞僾儖偺巊偄偳偙傠偑傛偔暘偐傜側偄乿偲偄偆堄尒丒姶憐偼懡偄偑丄朻摢偺儕僗僩8偱帵偟偨TensorFlow僠儏乕僩儕傾儖偐傜偺僐乕僪偺敳悎偱傕暘偐傞傛偆偵丄尰応偱偼僞僾儖偼懡梡偝傟偰偄傞丅僞僾儖偺椙偝偼僾儘僌儔儈儞僌傪恑傔傞偲暘偐偭偰偔傞偺偱丄偝傜偵僞僾儖偺摿挜揑側婡擻傪徯夘偟偰偄偙偆丅摿偵丄師偵愢柧偡傞傾儞僷僢僋戙擖偼丄僾儘僌儔儈儞僌傪偡傞偆偊偱旕忢偵曋棙偱偁傞丅幚嵺偵丄朻摢偺儕僗僩8偵偁傞乽僞僾儖娭楢偺峴乿偺偡傋偰偑傾儞僷僢僋戙擖偱偁傞丅
仦 傾儞僷僢僋戙擖乮暋悢偺曄悢傊偺暘夝戙擖乯
丂僞僾儖乮亖tuple宆偺僆僽僕僃僋僩乯傪暘夝偟偰丄暋悢偺曄悢偵戙擖偡傞偙偲傪傾儞僷僢僋傕偟偔偼傾儞僷僢僋戙擖偲屇傇丅
丂慜宖偺儕僗僩8偺愢柧偵擖傞慜偵丄偙偙偱偼梋寁側暥朄婡擻傪娷傔側偄壖偺僒儞僾儖僐乕僪傪採帵偡傞乮儕僗僩8-6丄恾10-4乯丅
# 曄悢乽tuple_data乿偺愰尵偲僞僾儖抣偺戙擖偼丄儕僗僩8-5偱峴偭偰偄傞
# tuple宆偱愰尵偟偨暋悢偺曄悢偵丄僞僾儖抣傪傾儞僷僢僋戙擖乮亖暘夝偟偰戙擖乯
(first_name, family_name) = tuple_data
family_name # 'Yamada'偲弌椡偝傟傞

丂儕僗僩8-6偺僐乕僪撪梕傪愢柧偡傞偲丄tuple_data偼丄('Taro', 'Yamada')偲偄偆抣傪帩偮僞僾儖偱偁傞丅偦偺僞僾儖偺奺梫慺傪戙擖偝傟傞懁偺曄悢孮偼丄(first_name, family_name)偲側偭偰偄傞丅
丂曄悢孮偺彂偒曽偼丄僞僾儖偺嶌惉曽朄偲傑偭偨偔摨偠偱偁傞丅摉慠偱偼偁傞偑丄戙擖尦偲側傞僞僾儖偺峔憿乮偙偺椺偱偼丄2偮偺梫慺偑偁傞乯偲丄戙擖愭偵偁傞曄悢孮偺峔憿乮偙偺椺偱偼丄2偮偺梫慺偑偁傞乯偼丄姰慡偵堦抳偝偣傞昁梫偑偁傞乮偙偺椺偱偼丄偳偪傜傕2偮偺梫慺偱堦抳偟偰偄傞乯丅偦偺峔憿偵婎偯偒丄1偮栚偺曄悢偵偼丄僞僾儖撪偵偁傞1斣栚偺僆僽僕僃僋僩偑戙擖偝傟丄2偮栚偺曄悢偵偼僞僾儖撪2斣栚偺僆僽僕僃僋僩偑戙擖偝傟傞丅
丂偦偺寢壥丄恾10-4偺僀儊乕僕偺偲偍傝丄曄悢first_name偵'Taro'偑丄曄悢family_name偵'Yamada'偑愝掕偝傟傞偙偲偵側傞偺偱偁傞丅
仦 娵妵屖偺徣棯
丂偡偱偵娙扨偵徯夘嵪傒偱偁傞偑丄僞僾儖偺廳梫側摿挜偲偟偰丄娵妵屖(乣)傪徣棯偟偰僇儞儅','偱嬫愗傞偩偗偱傕僞僾儖偲尒側偝傟傞丄偲偄偆揰偑偁傞丅儕僗僩8-7偼幚嵺偵徣棯偟偨傕偺丅
first_name, family_name = 'Taro', 'Yamada'
family_name # 'Yamada'偲弌椡偝傟傞
丂偙傟傪尒偰婥晅偄偨偩傠偆偐丅傑傞偱乽暋悢偺曄悢偺愰尵偲抣偺戙擖乿傪1峴偱傑偲傔偰峴偭偰偄傞傒偨偄偩偲丅幚嵺偵丄1峴偱傑偲傔偰曄悢傪愰尵偡傞偨傔偵丄僞僾儖偼巊傢傟傞偙偲偑偁傞丅儕僗僩8-8偼丄娵妵屖偺徣棯婡擻傪妶梡偟偰丄幚嵺偵暋悢偺曄悢傪傑偲傔偰愰尵偟偰抣傪戙擖偟偨椺偱偁傞丅
is_b, EPOCHS, color = False, 500, 'blue'
is_b, EPOCHS, color # '(False, 500, 'blue')'偲弌椡偝傟傞
丂偙偺傛偆偵僞僾儖偑偁傟偽丄僌儖乕僾扨埵偱曄悢傪戙擖偟偨傝娗棟偟偨傝偱偒傞傛偆側傝丄奐敪偑偟傗偡偔側傞偺偱偁傞丅
丂僞僾儖偼丄師夞Lesson 7偱愢柧偡傞乽娭悢乿偐傜弌椡偝傟傞抣乮亖尩枾偵偼乽栠傝抣乿傗乽曉傝抣乿偲屇偽傟傞乯偲偟偰巊傢傟傞偙偲傕懡偄丅娭悢偵傛偭偰偼丄弌椡偡傞抣偼1偮偱偼側偔丄2乣10屄偖傜偄側偳懡悢偺抣傪傑偲傔偰弌椡偟偨偄応崌偑偁傞偐傜偩丅偦偺堦椺偑儕僗僩8-9偺僐乕僪偱偁傞乮慜宖偺儕僗僩8偐傜偺敳悎乯丅
#import tensorflow as tf
#mnist = tf.keras.datasets.mnist
# 埲壓偺僐乕僪傪摦偐偡偨傔偵偼丄忋婰2峴傪帠慜偵幚峴偟偰偍偔昁梫偑偁傞
#---------------------------------------------------------------------
(x_train, y_train),(x_test, y_test) = mnist.load_data()
# 塃曈偺乽mnist.load_data()乿偼娭悢偱丄
# ((亙孭楙僨乕僞亜, 亙孭楙儔儀儖亜), (亙僥僗僩僨乕僞亜, 亙僥僗僩儔儀儖亜))
# 偲偄偆峔憿偺僞僾儖傪弌椡偡傞
丂儕僗僩8-9偱偼丄(x_train, y_train)偲(x_test, y_test)偲偄偆2偮偺僞僾儖宍幃偺曄悢偑愰尵偝傟偰偄傞丅
丂偙傟傜傪A偲B偲偄偆壖偺曄悢偵抲偒姺偊傞偲丄戙擖=偺嵍曈偼A, B偲側傝丄偙偺彂偒曽偼愭傎偳愢柧偟偨乽娵妵屖偑徣棯偝傟偨僞僾儖乿偱偁傞偙偲偑暘偐傞丅
丂徣棯偝傟偨娵妵屖傪(A, B)偲栠偟偰丄偦偺A偲B偺拞恎傪揥奐偡傞偲丄((x_train, y_train), (x_test, y_test))偲偄偆僐乕僪偵側傞乮恾10-5乯丅
丂偮傑傝儕僗僩8-9偼丄僞僾儖偺拞偵僞僾儖偑偁傞暋嶨側擖傟巕峔憿乮亖僀儊乕僕偲偟偰偼儅僩儕儑乕僔僇恖宍偺傛偆偵敔偺拞偵敔偑偁傞忬懺偺偙偲丅僱僗僩丄奒憌峔憿乯偵側偭偰偄傞偙偲偑暘偐傞丅

丂傑偲傔傞偲儕僗僩8-9偼丄娭悢偑弌椡偡傞乽擖傟巕峔憿偺僞僾儖乿傪丄x_train丄y_train丄x_test丄y_test偲偄偆4偮偺曄悢偵傾儞僷僢僋戙擖偟偰偄傞僐乕僪偱偁傞丅愭傎偳弎傋偨捠傝丄乽戙擖尦偲側傞僞僾儖偺峔憿偲丄戙擖愭偵偁傞曄悢孮偺峔憿偼丄姰慡偵堦抳偝偣傞昁梫乿偑偁傝丄偙偺応崌偼mnist.load_data()娭悢偺弌椡偑乽僞僾儖傪梫慺偲偡傞僞僾儖乿偲側偭偰偄偰丄偦傟偵崌傢偣傞昁梫偑偁傞偨傔丄x_train, y_train, x_test, y_test = mnist.load_data()乮4梫慺偺僞僾儖傊偺戙擖乯偺傛偆側彂偒曽偼偱偒側偄偙偲偵偼拲堄偟傛偆丅
丂傑偨丄慜宖偺儕僗僩8偵偁偭偨丄
x_train, x_test = x_train / 255.0, x_test / 255.0
predictions_array, true_label = predictions_array[i], true_label[i]
傕摨條偵丄娵妵屖偑徣棯偝傟偨丄僞僾儖偺傾儞僷僢僋戙擖側偺偱偁傞丅摨偠愢柧偵側傞偺偱徻嵶偼徣棯偡傞丅
丂x_train / 255.0偼丄妱傝嶼乮Lesson 10乽巐懃墘嶼乿偱夝愢乯偱偼偁傞偑丄尩枾偵偼Python尵岅偺婡擻偱偼側偔丄儔僀僽儔儕乽NumPy乿偺寁嶼婡擻偱偁傞乮仸徻偟偔偼僨乕僞峔憿曇乵Lesson 3乶傪嶲徠乯丅
丂predictions_array[i]傕儔僀僽儔儕乽NumPy乿偺婡擻偱偁傞偑丄偦偺堄枴偼慜弎偺儕僗僩偺夝愢偱尵媦嵪傒偱偁傞丅
dict宆乮帿彂宆乯
丂dict宆傕壖偺僒儞僾儖僐乕僪偱愢柧偡傞乮儕僗僩8-10丄恾10-6乯丅
abc_dict = { 'a': 1.2, 'b': 2.4, 'c': 3.6 }
abc_dict # { 'a': 1.2, 'b': 2.4, 'c': 3.6 }偲弌椡偝傟傞

丂儕僗僩8-10偱偼丄曄悢abc_dict偵丄乽'a': 1.2乿偲乽'b': 2.4乿偲乽'c': 3.6乿偲偄偆3偮偺乽僉乕乮key乯丗抣乮value乯乿偺僙僢僩抣傪帿彂僨乕僞偲偟偰戙擖偟偰偄傞丅愢柧偡傞傑偱傕側偄偲巚偆偑丄椺偊偽1偮栚偺僙僢僩抣偼丄'a'偑僉乕偱丄1.2偑抣偱偁傞丅
丂偙偺傛偆偵帿彂偼丄攇妵屖{乣}偱嫴傫偱婰弎偡傞丅妵屖偺拞偼僇儞儅','偱嬫愗傞丅屄乆偺抣偺宆偼壗偱傕傛偄丅偙傟傑偱偲傎傏摨偠僷僞乕儞側偺偱丄擄偟偔偼側偄偩傠偆丅
仦 僉乕巜掕偵傛傞抣偺庢摼
丂偦傕偦傕Python偺帿彂偲偼丄僉乕傪婎偵抣偑扵偣傞僐儗僋僔儑儞偺偙偲偱偁傞丅椺偊偽儕僗僩8-11偱偼丄曄悢abc_dict偵懳偟偰'a'偲偄偆僉乕偱抣傪庢摼偟偰偄傞丅偙偺寢壥丄1.2偲偄偆抣偑摼傜傟傞偙偲偵側傞丅
abc_dict['a']
# 1.2偲弌椡偝傟傞
丂僉乕偵傛傞抣偺庢摼偼戙擖偵傕墳梡偱偒傞丅椺偊偽儕僗僩8-12偺傛偆偵丄abc_dict['a']偲偄偆僐乕僪偱庢摼偟偨屄暿梫慺偵懳偟偰丄悢抣傗暥帤楍側偳偺僆僽僕僃僋僩傪戙擖偡傞偙偲偱丄偦偺梫慺偺傒傪曄峏偱偒傞丅傑偨丄懚嵼偟側偄僉乕柤傪巜掕偟偰戙擖傪偟偨応崌偼丄偦偺僉乕柤偲戙擖偟偨抣傪巊偭偰怴偟偄梫慺偑捛壛偝傟傞丅
abc_dict['a'] = 12.3 # 戙擖偵傛傞抣偺曄峏
abc_dict['x'] = 9.9 # 戙擖偵傛傞僉乕偲抣偺捛壛
abc_dict # {'a': 12.3, 'b': 2.4, 'c': 3.6, 'x': 9.9}偲弌椡偝傟傞
丂dict宆偱偁傞帿彂偵娭偟偰傕丄帿彂偺憖嶌乮梫慺偺嶍彍丄慡晹嬻偵偡傞丄僉乕偺桳柍僠僃僢僋側偳乯宯偺娭悢側偳偑偁傞偑丄杮楢嵹偱偼愢柧傪妱垽偡傞丅
僨乕僞偺宆乮奺庬僆僽僕僃僋僩曇乯
丂埲忋傑偱偑丄Python尵岅偺戙昞揑側慻傒崬傒宆偱偁傞丅傕偪傠傫丄曄悢偵戙擖偝傟傞僆僽僕僃僋僩偺宆偼懡庬懡條偱偁傞丅慜夞Lesson 4偱尒偨乽儌僕儏乕儖乿偩偗偱側偔丄Lesson 7偱愢柧偡傞乽娭悢乿傗丄Lesson 11偱愢柧偡傞乽僋儔僗乿側偳丄偝傜偵昗弨偵娷傑傟偰偄傞宆偐傜帺嶌偟偨宆傑偱丄偝傑偞傑側僆僽僕僃僋僩偺宆偑偁傝摼傞丅
丂椺偊偽儕僗僩9偼丄慜宖偺恾1-b乛d撪偺僒儞僾儖僐乕僪偺拞偵偁傞乽曄悢偵懳偟偰壗偐傪戙擖偟偰偄傞峴乿乮亖朻摢偱帵偟偨亂嵞宖亃夋憸偺愒榞偺撪梕乯偺拞偐傜丄慻傒崬傒宆埲奜偺傕偺偩偗傪敳偒弌偟偰暲傋偨傕偺偩丅
#import tensorflow as tf # 偙偺僐乕僪傪摦偐偡偨傔偵僀儞億乕僩偑昁梫
# 曄悢傊偺乽儌僕儏乕儖乿偺戙擖
mnist = tf.keras.datasets.mnist
# 曄悢傊偺乽壗傜偐偺僆僽僕僃僋僩乿偺戙擖乮1乯
#model = tf.keras.models.Sequential([
# tf.keras.layers.Flatten(),
# tf.keras.layers.Dense(512, activation=tf.nn.relu),
# tf.keras.layers.Dropout(0.2),
# tf.keras.layers.Dense(10, activation=tf.nn.softmax)
#])
# 乽tf.keras.models.Sequential([乣])乿偺堄枴偼丄Lesson 11乽僋儔僗乿偺夞偱夝愢
# 偙偙偱偼丄師偺僐乕僪偵椪帪揑偵抲偒姺偊偰夝愢
model = '亙娭悢乮尩枾偵偼僋儔僗偺僐儞僗僩儔僋僞乕丅徻嵶徣棯乯亜偑弌椡偟偨僆僽僕僃僋僩'
# 曄悢傊偺乽壗傜偐偺僆僽僕僃僋僩乿偺戙擖乮2乯
#history = model.fit(train_data, train_labels, epochs=EPOCHS,
# validation_split = 0.2, verbose=0,
# callbacks=[PrintDot()])
# 乽model.fit(乣)乿偺堄枴偼丄Lesson 7乽娭悢乿偺夞偱夝愢
# 偙偙偱偼丄師偺僐乕僪偵椪帪揑偵抲偒姺偊偰夝愢
history = '亙娭悢乮徻嵶徣棯乯亜偑弌椡偟偨僆僽僕僃僋僩'
丂儕僗僩9偱偼丄曄悢mnist偵乽儌僕儏乕儖乿偑戙擖偝傟丄曄悢model偵偼娭悢偐傜弌椡偝傟偨乽壗傜偐偺僆僽僕僃僋僩乿偑戙擖偝傟偰偄傞乮仸曄悢history傕摨條偺娭悢側偺偱丄埲崀丄愢柧傪妱垽乯丅Lesson 4偱宖嵹偟偨傕偺偲摨偠奊偵側偭偰偟傑偆偑丄僀儊乕僕壔偡傞偲丄憐憸捠傝恾10-7偺傛偆偵側傞丅僨乕僞偺宆偑壗偱偁傠偆偑丄忢偵儚儞僷僞乕儞側偺偱偁傞丅

偮偯偔
丂Lessson 4乣6偱丄曄悢偲僨乕僞宆偺愢柧傪偟偨丅偙偙傑偱偺暥朄愢柧偩偗偱傕丄TensorFlow僠儏乕僩儕傾儖偵偍偗傞丄偐側傝懡偔偺峴悢偺僐乕僪傪愢柧偱偒偨偙偲偵側傞丅
丂師夞偼丄娭悢偵偮偄偰愢柧偡傞丅娭悢偼丄曄悢偺師偵廳梫側Python尵岅偺暥朄梫慺偱偁傞丅偙傟傪墴偝偊傞偙偲偱丄偝傜偵戝晹暘偺TensorFlow僠儏乕僩儕傾儖偺僐乕僪偑撉傒彂偒偱偒傞傛偆偵側傞丅
Copyright© Digital Advantage Corp. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅